
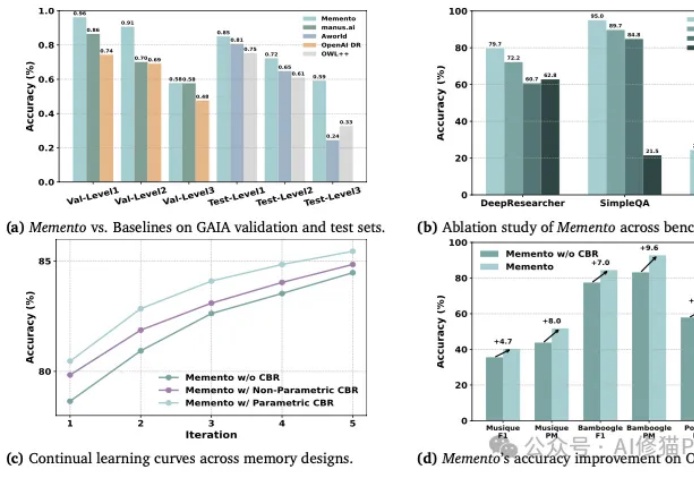
你的设想被证实了!不微调模型也能微调Agent,Memento霸榜GAIA|UCL最新
你的设想被证实了!不微调模型也能微调Agent,Memento霸榜GAIA|UCL最新你或许也有过这样的猜想,如何让AI智能体(Agent)变得更聪明、更能干,同时又不用烧掉堆积如山的算力去反复微调模型?
来自主题: AI技术研报
11134 点击 2025-09-01 09:58
你或许也有过这样的猜想,如何让AI智能体(Agent)变得更聪明、更能干,同时又不用烧掉堆积如山的算力去反复微调模型?
针对OpenAI最新开源的GPT-OSS,这一篇面向零基础小白用户的手把手式的详细训练教程或许能帮助你完成你的第一个GPT训练项目。
近年来,强化学习(Reinforcement Learning, RL)在提升大语言模型(LLM)复杂推理能力方面展现出显著效果,广泛应用于数学解题、代码生成等任务。通过 RL 微调的模型常在推理性能上超越仅依赖监督微调或预训练的模型。
开源赛道也是热闹了起来。 就在深夜,字节跳动 Seed 团队正式发布并开源了 Seed-OSS 系列模型,包含三个版本: Seed-OSS-36B-Base(含合成数据) Seed-OSS-36B-Base(不含合成数据) Seed-OSS-36B-Instruct(指令微调版)
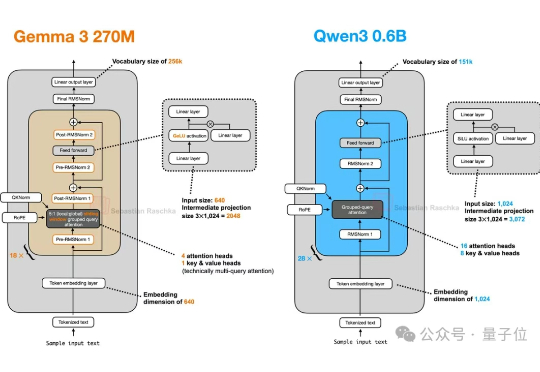
谷歌开源Gemma 3 270M闪亮登场!只需几分钟即可完成微调,指令遵循和文本结构化能力更是惊艳,性能超越Qwen 2.5同级模型。

首个开源多模态Deep Research Agent来了。整合了网页浏览、图像搜索、代码解释器、内部 OCR 等多种工具,通过全自动流程生成高质量推理轨迹,并用冷启动微调和强化学习优化决策,使模型在任务中能自主选择合适的工具组合和推理路径。
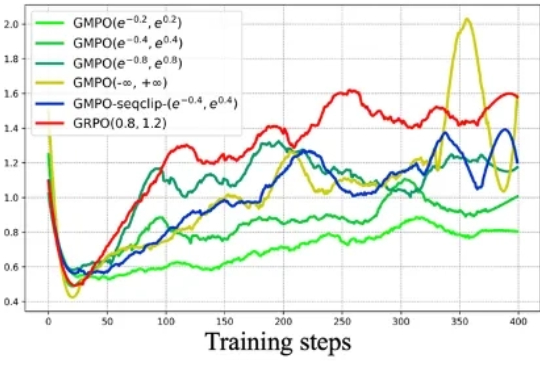
近年来,强化学习(RL)在大型语言模型(LLM)的微调过程中,尤其是在推理能力提升方面,取得了显著的成效。传统的强化学习方法,如近端策略优化(Proximal Policy Optimization,PPO)及其变种,包括组相对策略优化(Group Relative Policy Optimization,GRPO),在处理复杂推理任务时表现出了强大的潜力。
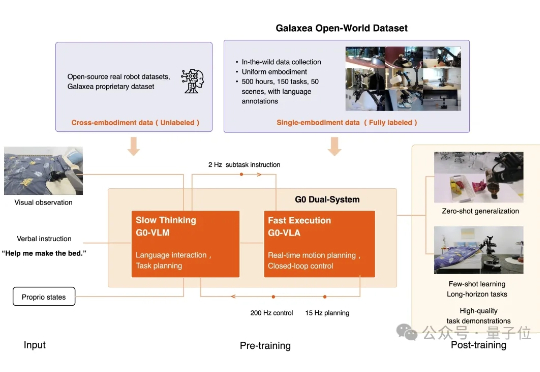
仅凭少量后训练微调,机器人就能完全自主、连续不断地完成床铺整理任务。 而它的每一步思考与动作实时投放在大屏幕上。

在语言模型领域,长思维链监督微调(Long-CoT SFT)与强化学习(RL)的组合堪称黄金搭档 —— 先让模型学习思考模式,再用奖励机制优化输出,性能通常能实现叠加提升。

近期,随着OpenAI-o1/o3和Deepseek-R1的成功,基于强化学习的微调方法(R1-Style)在AI领域引起广泛关注。这些方法在数学推理和代码智能方面展现出色表现,但在通用多模态数据上的应用研究仍有待深入。