速递|IBM未披露金额收购Seek AI,自然语言直连数据库,资源整合至Watsonx AI实验室
速递|IBM未披露金额收购Seek AI,自然语言直连数据库,资源整合至Watsonx AI实验室IBM 于 6 月 2 日宣布已收购 Seek AI,这是一个允许用户使用自然语言查询企业数据的 AI 平台,具体收购金额未披露。
来自主题: AI资讯
10781 点击 2025-06-03 16:33
 搜索
搜索
IBM 于 6 月 2 日宣布已收购 Seek AI,这是一个允许用户使用自然语言查询企业数据的 AI 平台,具体收购金额未披露。

大语言模型(LLMs)作为由复杂算法和海量数据驱动的产物,会不会“无意中”学会了某些类似人类进化出来的行为模式?这听起来或许有些大胆,但背后的推理其实并不难理解:

新加坡国立大学等机构的研究者们通过元能力对齐的训练框架,模仿人类推理的心理学原理,将演绎、归纳与溯因能力融入模型训练。实验结果显示,这一方法不仅提升了模型在数学与编程任务上的性能,还展现出跨领域的可扩展性。

在多智能体AI系统中,一旦任务失败,开发者常陷入「谁错了、错在哪」的谜团。PSU、杜克大学与谷歌DeepMind等机构首次提出「自动化失败归因」,发布Who&When数据集,探索三种归因方法,揭示该问题的复杂性与挑战性。

生成式AGI已经颠覆了人们的生活,但AI工具并没有随着用户使用场景的融合而整合。各个赛道的头部玩家依靠独家的数据库发展模型,现有算力和数据量难以支撑多模态和跨业务领域拓展,急需形成用户粘性的市场竞争也使得AI的生成稳定性被优先考虑。

如何让CLIP模型更关注细粒度特征学习,避免“近视”?360人工智能研究团队提出了FG-CLIP,可以明显缓解CLIP的“视觉近视”问题。让模型能更关注于正确的细节描述,而不是更全局但是错误的描述。
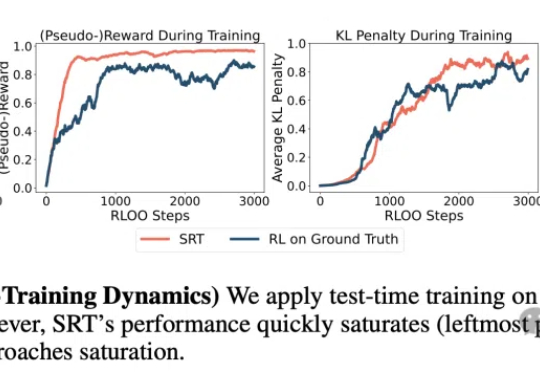
数据枯竭正成为AI发展的新瓶颈!CMU团队提出革命性方案SRT:让LLM实现无需人类标注的自我进化!SRT初期就能迭代提升数学与推理能力,甚至性能逼近传统强化学习的效果,揭示了其颠覆性潜力。
AI加速药物研发的同时引发专利泛滥问题,AI公司专利申请因缺乏体内实验数据(仅23%含体内实验,传统公司为47%),导致潜在药物后续开发受阻。专家建议提高专利门槛、允许他人二次申请未测试分子,并通过延长监管保护期平衡创新激励与公开风险。
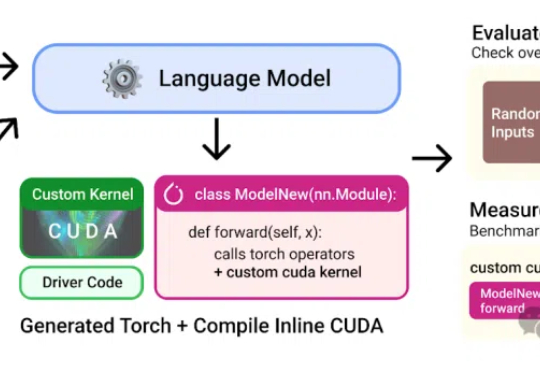
本想练练手合成点数据,没想到却一不小心干翻了PyTorch专家内核!斯坦福华人团队用纯CUDA-C写出的AI生成内核,瞬间惊艳圈内并登上Hacker News热榜。团队甚至表示:本来不想发这个结果的。
为提升大模型“推理+搜索”能力,阿里通义实验室出手了。