
Claude一夜杀入Excel和PPT,暴击微软Copilot!永久记忆血洗软件业
Claude一夜杀入Excel和PPT,暴击微软Copilot!永久记忆血洗软件业跨文件记忆革命:单一对话同时操控多个Excel工作簿+PowerPoint幻灯片,数据从表格直飞演示文稿,无缝迁移零解释,Anthropic把AI Agent玩明白了。
来自主题: AI资讯
9153 点击 2026-03-13 10:58
 搜索
搜索
跨文件记忆革命:单一对话同时操控多个Excel工作簿+PowerPoint幻灯片,数据从表格直飞演示文稿,无缝迁移零解释,Anthropic把AI Agent玩明白了。

牛津大学团队推出全球首个心脏传感基础模型CSFM,能统一分析智能手环、心电图等多源数据,无论信号来自何处、是否完整,都能精准诊断房颤、预测死亡风险、重构血压波形,甚至用单一脉搏波生成完整心电图。打破了设备壁垒,让偏远地区也能享用顶级心脏监护,推动全球医疗平权。
X用户SnowShadow爆料,腾讯新上线的AI技能平台SkillHub,将ClawHub上的所有技能数据悉数扒下,导入到了自家平台。 斯坦伯格随即亲自下场回应。他透露自己此前曾收到邮件,对方抱怨ClawHub的速率限制导致他们“爬得不够快”.

AI 正从数字世界走向物理世界。
让OpenClaw帮干活还不够,现在,程序员们正想方设法让🦞自己变强。

用户把文本发到我们的 API,我们返回一串浮点数。没有标签,没有水印,没有任何元数据告诉你它从哪来、用的什么模型。大多数人看到这串数字,反应都是"不就是一堆浮点数嘛,能看出什么?"
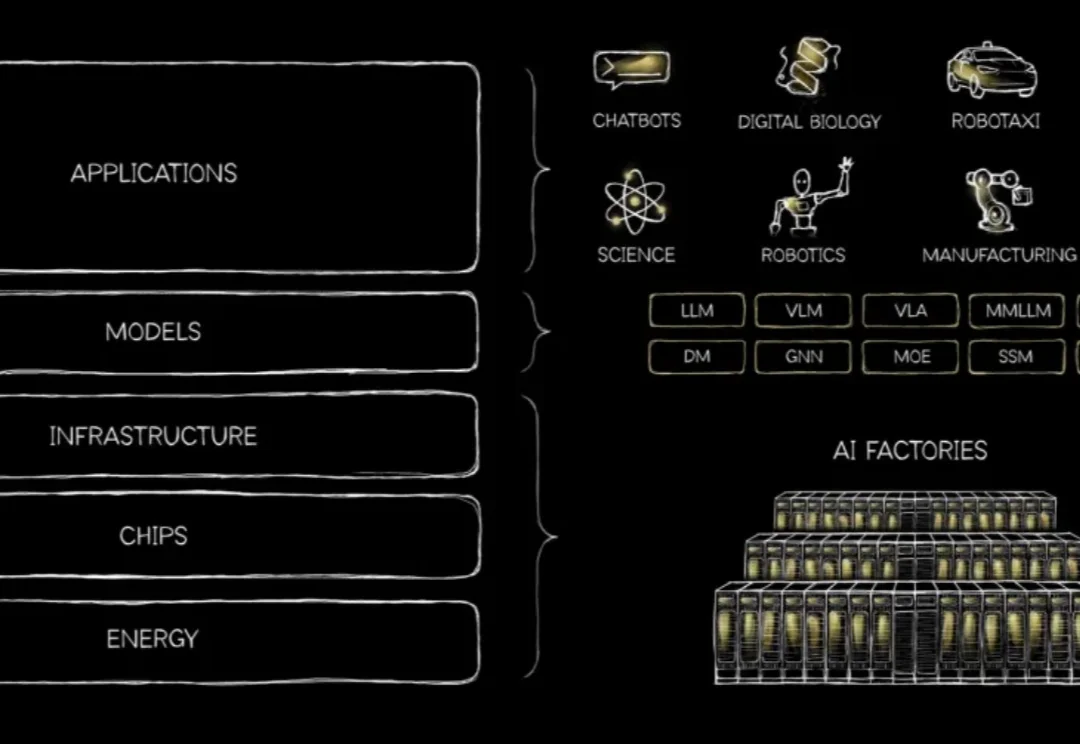
在「龙虾热」蔓延全国的此刻,大家把越来越多的工作交给 AI。从写代码到数据分析,很多人开始尝试让 AI 接管完整流程。

Ben在视频中提到了一个令人震惊的数据对比。虽然ChatGPT的使用率在飞速增长,企业也在疯狂尝试各种AI解决方案,但真正能看到商业价值的却少之又少。根据MIT的研究,在供应商销售的AI解决方案中,只有5%的试点项目最终进入了生产环境。Deloitte(德勤)发现只有15%的组织表示他们从AI中获得了显著的、可衡量的ROI。

对比学习已成为表征学习中的一种强大范式,能够在不依赖标签的情况下有效利用无标注数据。

NUS、ZJU、UW、Stanford、CUHK 联合提出 「ThinkMorph」,主张让文字与图像在统一架构里「原生协作」、「共同演化」,而不是像当下大多数多模态模型那样,看完图像就闭上眼睛,后续完全靠文字链条推进。仅用 2.4 万条数据微调 7B 统一模型,视觉推理平均提升 34.74%,多项任务比肩甚至超越 GPT-4o 和 Gemini 2.5 Flash。