科学家推出全球首个酶-底物三维复合体数据库,酶工程进入超高预测的AI时代!
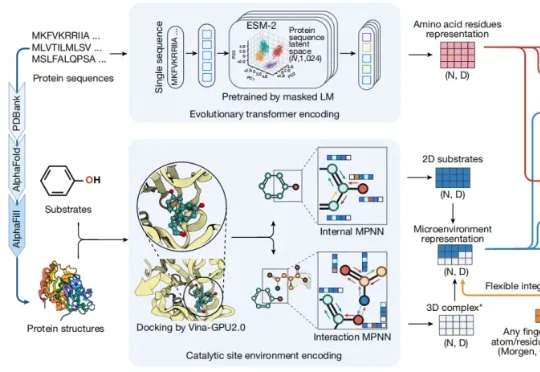
科学家推出全球首个酶-底物三维复合体数据库,酶工程进入超高预测的AI时代!近日,由美国伊利诺伊大学厄巴纳香槟分校 Huimin Zhao 教授和南京师范大学教授崔海洋等人共同研发出一种名为 EZSpecificity 的 AI 工具,成功给酶装上了智能识别系统,能以前所未有的准确度预测酶和底物之间的匹配关系,相关论文发表于 Nature。
来自主题: AI资讯
8975 点击 2025-12-14 10:52