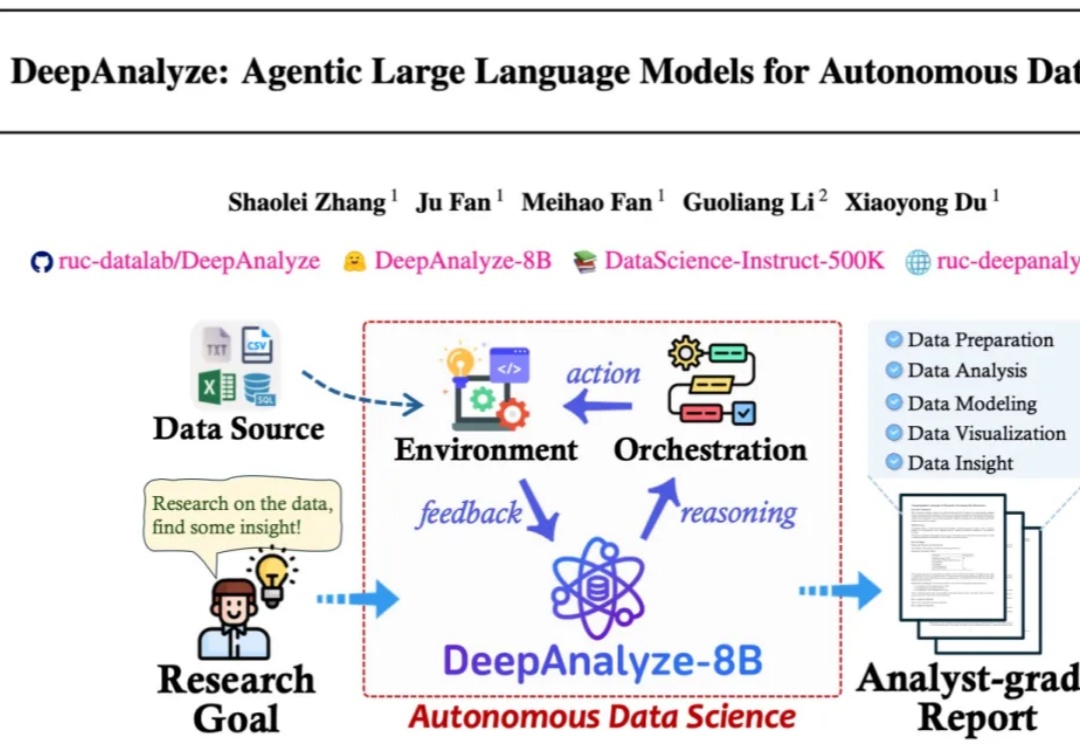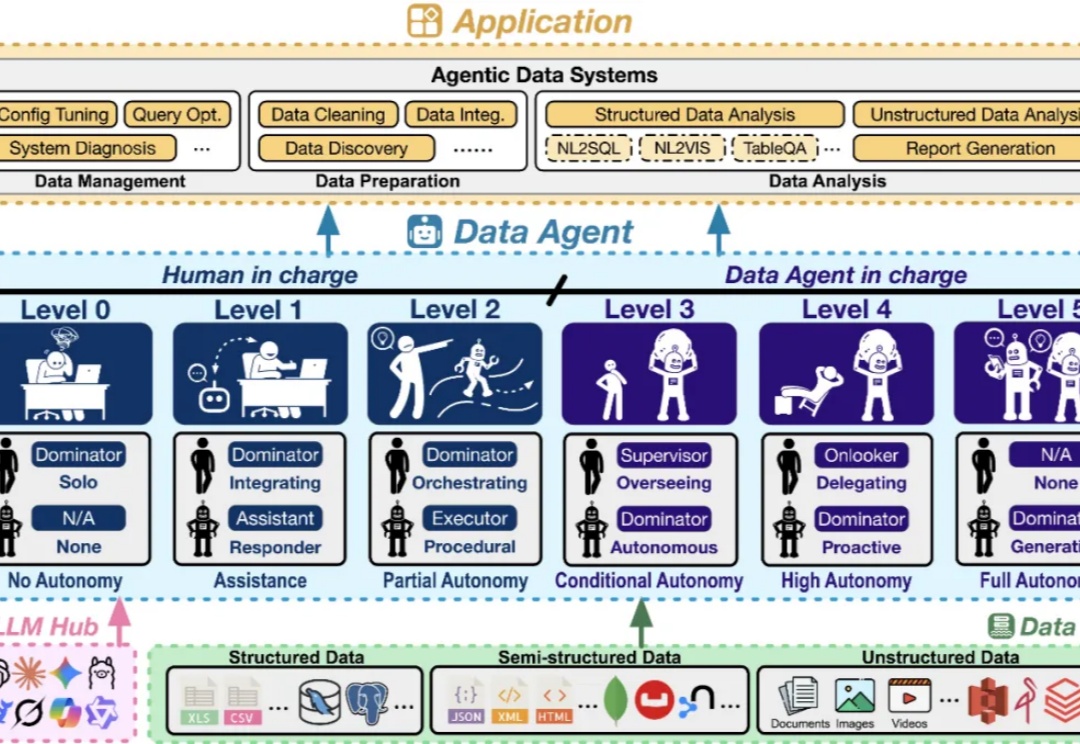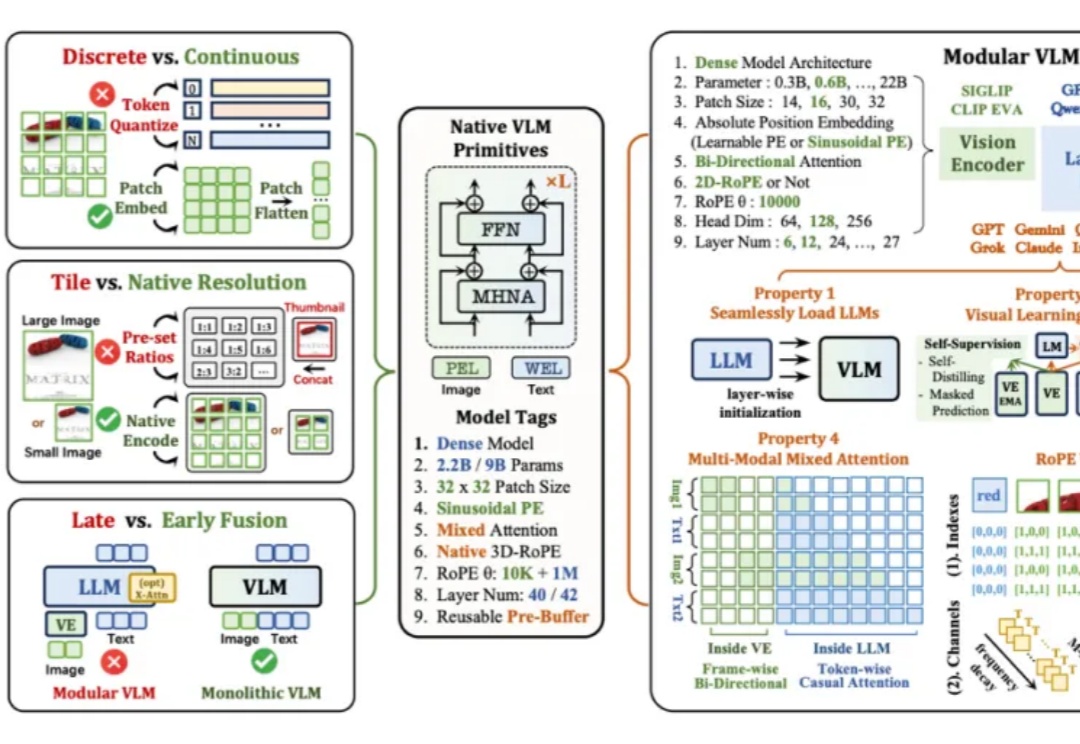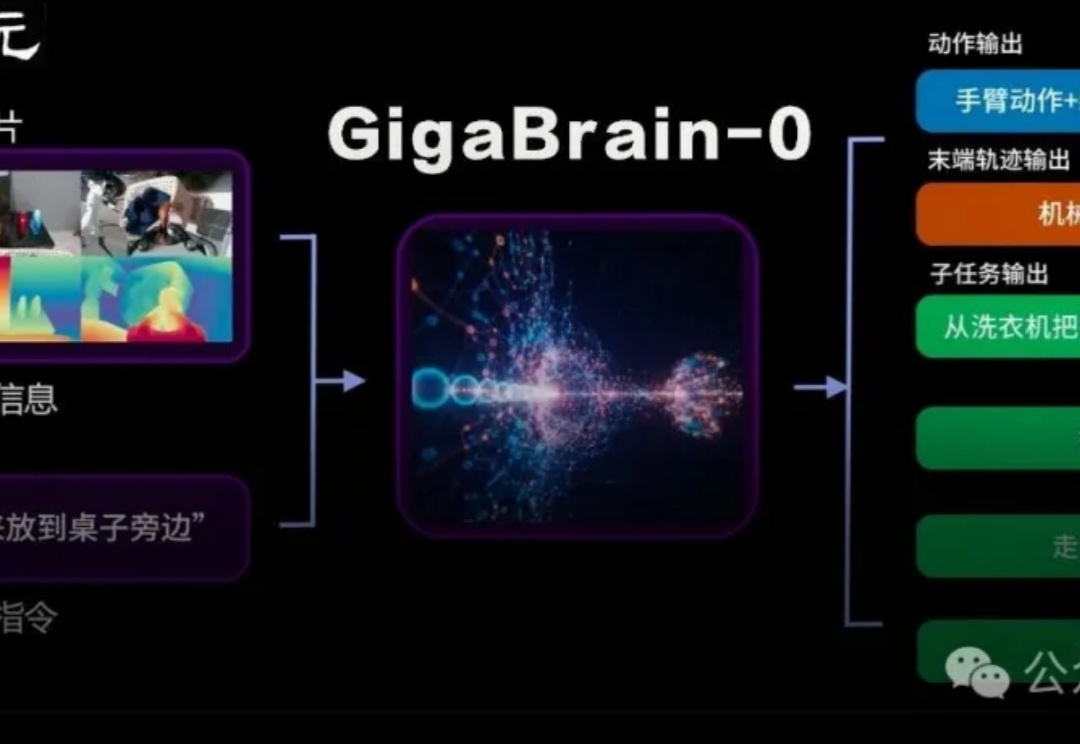
海外AI应用行业全景丨万字长文丨2025年9月丨赛道格局 + 赛道之王 + TOP 50 AI应用 + 增长之星丨Xsignal
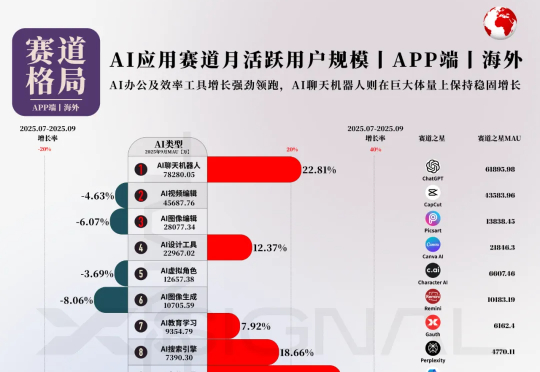
海外AI应用行业全景丨万字长文丨2025年9月丨赛道格局 + 赛道之王 + TOP 50 AI应用 + 增长之星丨Xsignal本次,X博士继续应用Xsignal数据交互平台的AI Holo(AI 全息)数据库数据,为你提供海外AI应用市场2025年9月的最新发展动态,发布2025年9月海外“赛道格局”、“赛道之王”、“TOP 50 AI应用”和“增长之星”四大数据榜单及深度洞察。
来自主题: AI技术研报
13977 点击 2025-10-31 15:16