
Anthropic CEO再预警:未来5年砍掉一半入门岗,失业率10–20%
Anthropic CEO再预警:未来5年砍掉一半入门岗,失业率10–20%数据显示,仅2025年开年以来,美国已有超过一万个岗位因为引入AI而被裁撤。Anthropic CEO Dario Amodei认为AI技术的扩散对就业和社会的冲击,已经到了必须向全世界预警的地步。
来自主题: AI资讯
8798 点击 2025-10-15 14:06
 搜索
搜索
数据显示,仅2025年开年以来,美国已有超过一万个岗位因为引入AI而被裁撤。Anthropic CEO Dario Amodei认为AI技术的扩散对就业和社会的冲击,已经到了必须向全世界预警的地步。
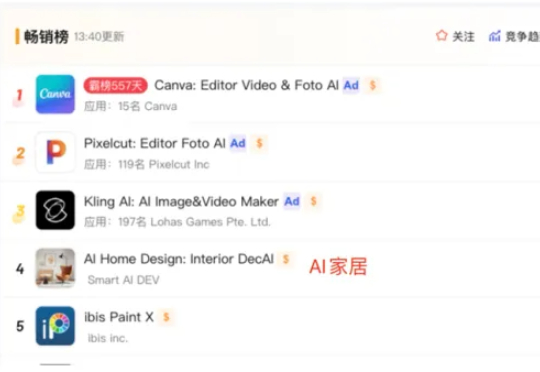
根据 Sensor Tower 数据显示,2025 H1 AI 应用的下载量达到 17 亿次,增长 67%,IAP 收入总计达到 19 亿美元,增幅达到 100.6%。在走过了概念验证阶段后,AI 应用正成为一股很强的增长动力,给已经相对平静的应用市场注入了活力。
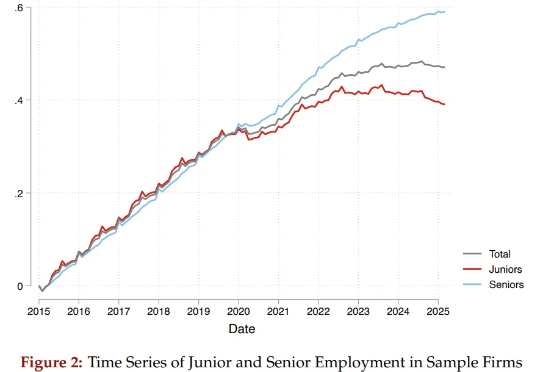
两位哈佛学者通过研究6200万份简历和近2亿条招聘职位数据,揭示了AI对就业带来的真实、残酷的冲击:它不是无差别地针对所有人,而是在大量“吞噬”初级岗位,让那些刚刚踏入社会的年轻人,面临着空前陡峭、狭窄的职业起跑线。与此同时,为数众多的普通院校毕业生群体受到的冲击更为显著。
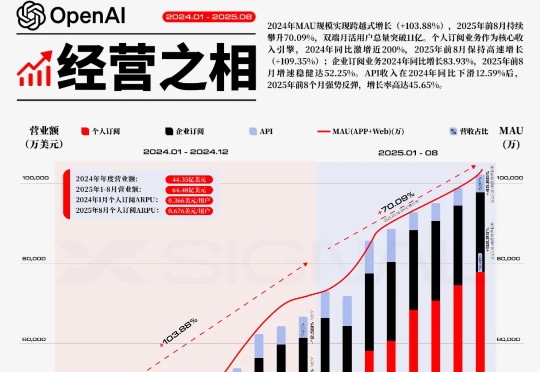
2022年11月,OpenAI的ChatGPT问世,这一事件不仅是技术创新的里程碑,更被视为重塑全球AI战略版图的关键转折点,它标志着新一轮大国AI竞赛的序幕被正式拉开。在此背景下,其增长的规模与速度本身,就是一种颠覆性的战略壁垒。

InfLLM-V2是一种可高效处理长文本的稀疏注意力模型,仅需少量长文本数据即可训练,且性能接近传统稠密模型。通过动态切换短长文本处理模式,显著提升长上下文任务的效率与质量。从短到长低成本「无缝切换」,预填充与解码双阶段加速,释放长上下文的真正生产力。

国际奥赛又一块金牌,被AI夺下了!在国际天文与天体物理奥赛(IOAA)中,GPT-5和Gemini 2.5 Pro完胜人类选手,在理论和数据分析测试中,拿下了最高分。在理论考试上,Gemini 2.5 Pro总体得分85.6%,GPT-5总体得分84.2%;
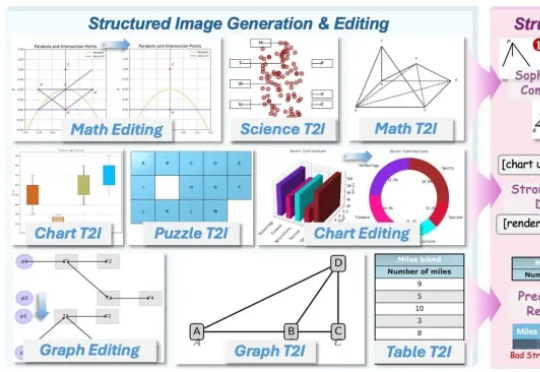
AI竟然画不好一张 “准确” 的图表?AI生图标杆如FLUX.1、GPT-Image,已经能生成媲美摄影大片的自然图像,却在柱状图、函数图这类结构化图像上频频出错,要么逻辑混乱、数据错误,要么就是标签错位。

图片来源:David AI Labs David AI Labs 这家初创公司通过出售音频数据集来帮助训练人工智能模型,近期在新一轮融资中从投资者处筹集了 5000 万美元——这表明为 AI 开发提供

既然后训练这么重要,那么作为初学者,应该掌握哪些知识?大家不妨看看这篇博客《Post-training 101》,可以很好的入门 LLM 后训练相关知识。从对下一个 token 预测过渡到指令跟随; 监督微调(SFT) 基本原理,包括数据集构建与损失函数设计;
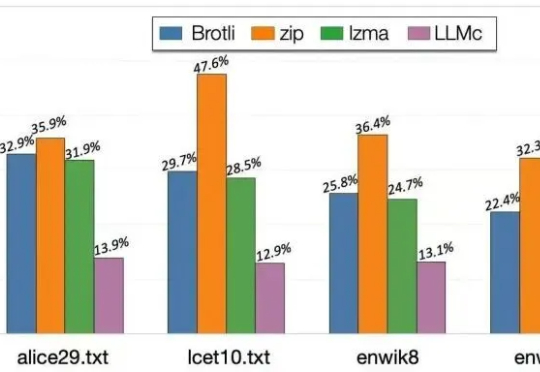
当大语言模型生成海量数据时,数据存储的难题也随之而来。对此,华盛顿大学(UW)SyFI实验室的研究者们提出了一个创新的解决方案:LLMc,即利用大型语言模型自身进行无损文本压缩的引擎。