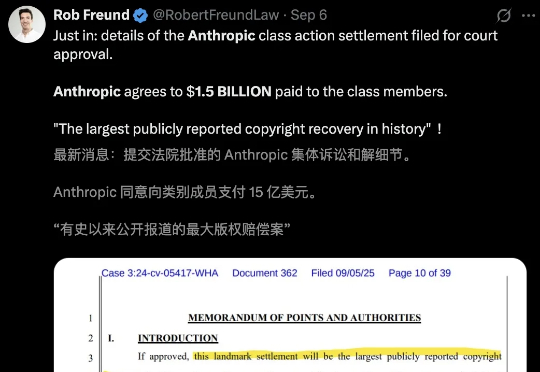
小扎豪掷143亿,却换不来AI燃料!数据之争下半场,中国冲出一匹黑马
小扎豪掷143亿,却换不来AI燃料!数据之争下半场,中国冲出一匹黑马真正决定AI上限的,已从「模型规模」转为「数据质量」。从Meta押注数据平台到xAI裁员转招「专业AI导师」,全球「数据大战」全面进入下半场。中国玩家里,澳鹏数据独占一档,仅2025年上半年营收达3.06亿元。高质量、可追溯、可工程化的数据生产,正成为AI产业的新壁垒。
来自主题: AI资讯
8741 点击 2025-09-17 16:25
 搜索
搜索
真正决定AI上限的,已从「模型规模」转为「数据质量」。从Meta押注数据平台到xAI裁员转招「专业AI导师」,全球「数据大战」全面进入下半场。中国玩家里,澳鹏数据独占一档,仅2025年上半年营收达3.06亿元。高质量、可追溯、可工程化的数据生产,正成为AI产业的新壁垒。

你有没有想过,为什么即使今天的 AI 已经能写代码、分析数据、回答复杂问题,但当你和它们对话时,总感觉缺了点什么?那种微妙的不舒适感,就像看着一个技术完美但缺乏灵魂的机器人在表演人类。这不是像素质量的问题,也不是语言能力的缺陷,而是一个更根本的缺失:情感智能。
谷歌DeepMind研究团队一年前的研究成果直到昨晚才姗姗揭秘,提出了一种叫做GDR的新方法,颠覆了传统训练中设法剔除脏数据的思路,将饱含恶意内容的数据「变废为宝」,处理后的数据集用于训练,甚至比直接剔除脏数据训练出的模型效果还好,「出淤泥而不染」,「择善而从」。

在大厂内部“从0到1”推动并构建数据基础设施十余年之后,离哲选择走向台前,开启一场真正意义上的“从技术到产品、从产品到服务闭环”的创业实验。

随着Agent的爆发,大型语言模型(LLM)的应用不再局限于生成日常对话,而是越来越多地被要求输出像JSON或XML这样的结构化数据。这种结构化输出对于确保安全性、与其他软件系统互操作以及执行下游自动化任务至关重要。
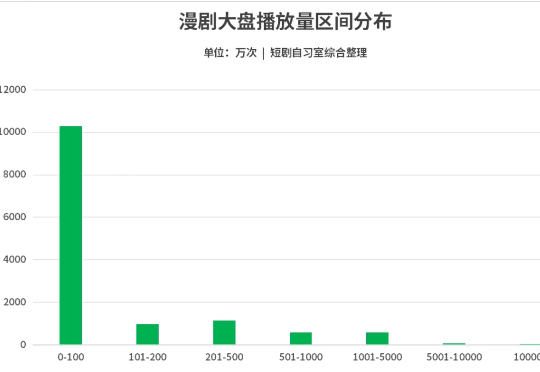
上周,漫剧的大量数据公布,让行业内外对这一内容形态的增速有了更全面的体感。但漫剧赛道无疑仍处于用数量博爆款的初期,什么样的漫剧更有爆相,怎样提高测出率乃至于爆款率——诸如此类的问题仍然难有定论。

近日,Gamma 创始人 Grant Lee 首次公开了公司的真实营收数据: 月经常性收入(MRR)已达到 480 万美元,折算年经常性收入(ARR)超过 5000 万美元。

北京深度逻辑智能科技有限公司推出了 LLaSO—— 首个完全开放、端到端的语音语言模型研究框架。LLaSO 旨在为整个社区提供一个统一、透明且可复现的基础设施,其贡献是 “全家桶” 式的,包含了一整套开源的数据、基准和模型,希望以此加速 LSLM 领域的社区驱动式创新。

就在 Scale AI 公司的 95 后创始人 Alexandr Wang 在 Meta 挑大梁之际,他迎来了一位比他更小的 00 后劲敌。这名 00 后叫阿里·安萨里(Ali Ansari),是一名

幻觉不是 bug,是数学上的宿命。 谢菲尔德大学的最新研究证明,大语言模型的幻觉问题在数学上不可避免—— 即使用完美的训练数据也无法根除。 而更为扎心的是,OpenAI 提出的置信度阈值方案虽能减少幻