
OpenAI五年内狂烧1150亿美元应战!年营收将达2000亿美元
OpenAI五年内狂烧1150亿美元应战!年营收将达2000亿美元OpenAI最近向股东们做了汇报,豪言将在未来五年烧1150亿美元,主要用于将自建的数据中心。与此同时,OpenAI也预测2030年营收将达到2000亿美元。OpenAI的信心因何如此充足?
来自主题: AI资讯
9148 点击 2025-09-09 12:04
 搜索
搜索
OpenAI最近向股东们做了汇报,豪言将在未来五年烧1150亿美元,主要用于将自建的数据中心。与此同时,OpenAI也预测2030年营收将达到2000亿美元。OpenAI的信心因何如此充足?

AI 数据行业,总有新人出头。

过去几年,大语言模型(LLM)的训练大多依赖于基于人类或数据偏好的强化学习(Preference-based Reinforcement Fine-tuning, PBRFT):输入提示、输出文本、获得一个偏好分数。这一范式催生了 GPT-4、Llama-3 等成功的早期大模型,但局限也日益明显:缺乏长期规划、环境交互与持续学习能力。
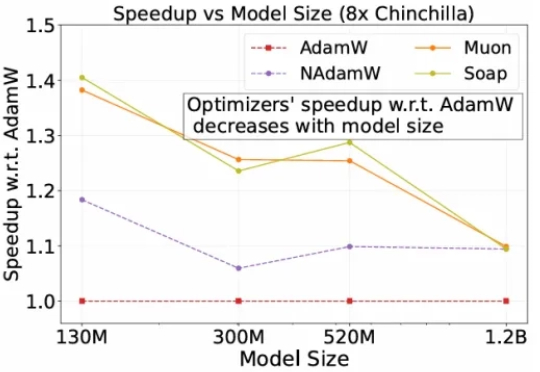
自2014 年提出以来,Adam 及其改进版 AdamW 长期占据开放权重语言模型预训练的主导地位,帮助模型在海量数据下保持稳定并实现较快收敛。

近日,备受关注的德里亚·巴茨(Andrea Bartz)等诉Anthropic公司的集体诉讼案以一项高达15亿美元的和解协议暂告段落。该案自立案之初便牵动科技界与版权界神经,其最终处理结果及创纪录的和解金额,在AI行业内引发强烈震动。
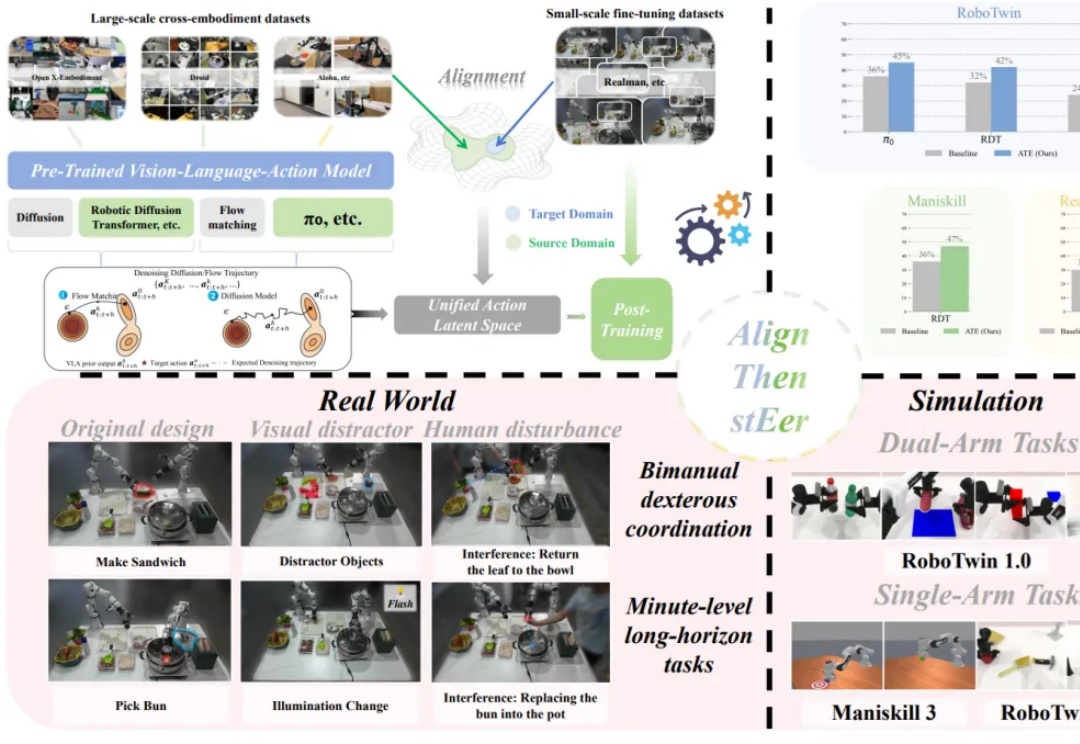
在多模态大模型的基座上,视觉 - 语言 - 动作(Visual-Language-Action, VLA)模型使用大量机器人操作数据进行预训练,有望实现通用的具身操作能力。

Meta豪掷143亿收购Scale AI,意外成就了3名22岁青年的创业神话!他们靠着为OpenAI等顶级AI实验室输送模型专家训练师,干出百亿独角兽Mercor,年入1亿美金。目前,Mercor在《福布斯》Cloud 100 榜单中排名第89位。
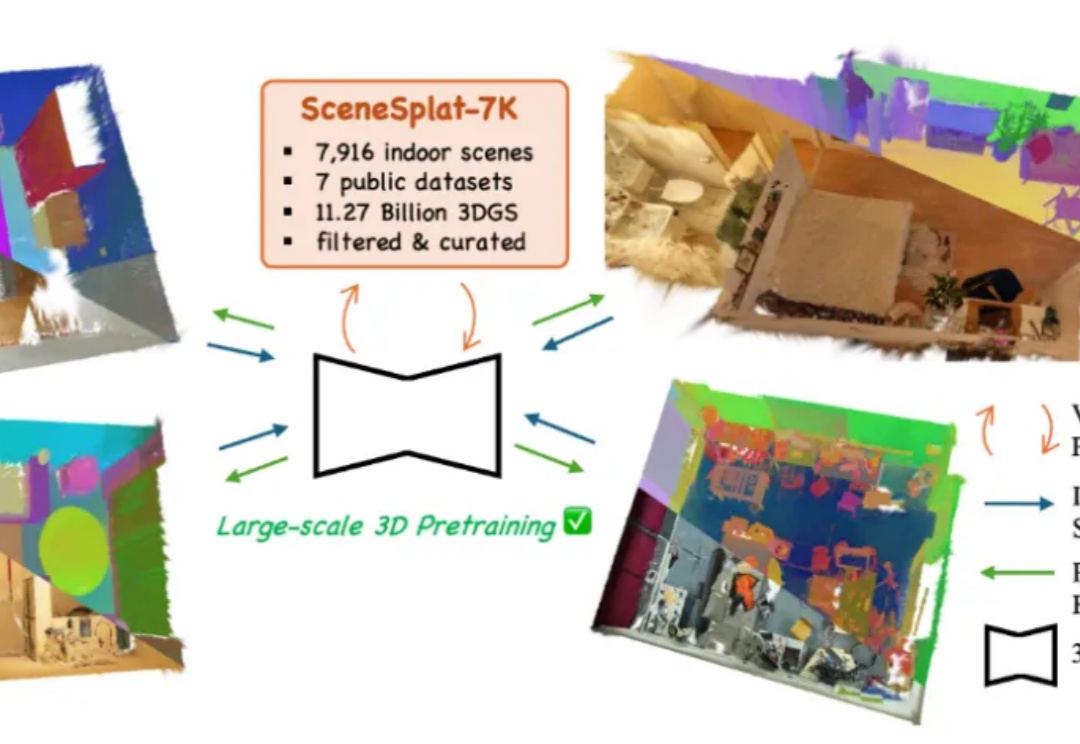
开放词汇识别与分类对于全面理解现实世界的 3D 场景至关重要。目前,所有现有方法在训练或推理过程中都依赖于 2D 或文本模态。这凸显出缺乏能够单独处理 3D 数据以进行端到端语义学习的模型,以及训练此类模型所需的数据。与此同时,3DGS 已成为各种视觉任务中 3D 场景表达的重要标准之一。
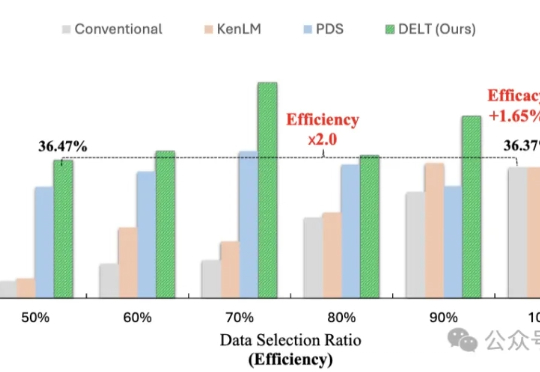
模型训练重点在于数据的数量与质量?其实还有一个关键因素—— 数据的出场顺序。
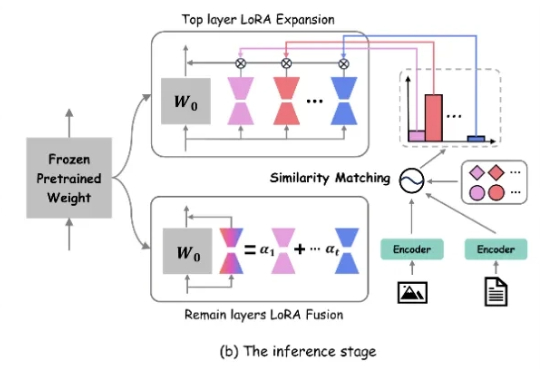
近年来,生成式 AI 和多模态大模型在各领域取得了令人瞩目的进展。然而,在现实世界应用中,动态环境下的数据分布和任务需求不断变化,大模型如何在此背景下实现持续学习成为了重要挑战