最后通牒!Claude聊天/代码「默认」全喂AI训练,你的隐私能被用5年
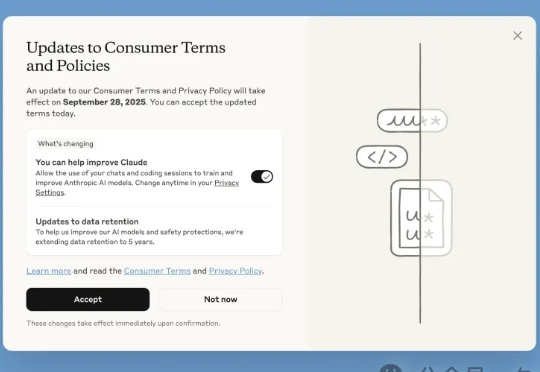
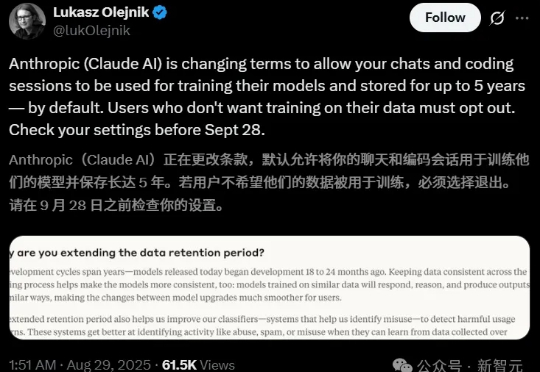
最后通牒!Claude聊天/代码「默认」全喂AI训练,你的隐私能被用5年近日,Anthropic更新了它的消费者条款,没想竟把网友惹怒了,有的还把以往的「旧账」都翻了出来。这次网友的反应为啥这么激烈?大家可能还记得在Claude上线之初,Anthropic就坚决表示不会拿用户数据来训练模型。这次变化不仅自己打脸,还把以往一些「背刺」用户的往事都抖搂出来了。
来自主题: AI资讯
10209 点击 2025-08-31 13:31