从VLA到RoboOmni,全模态具身新范式让机器人察言观色、听懂话外音
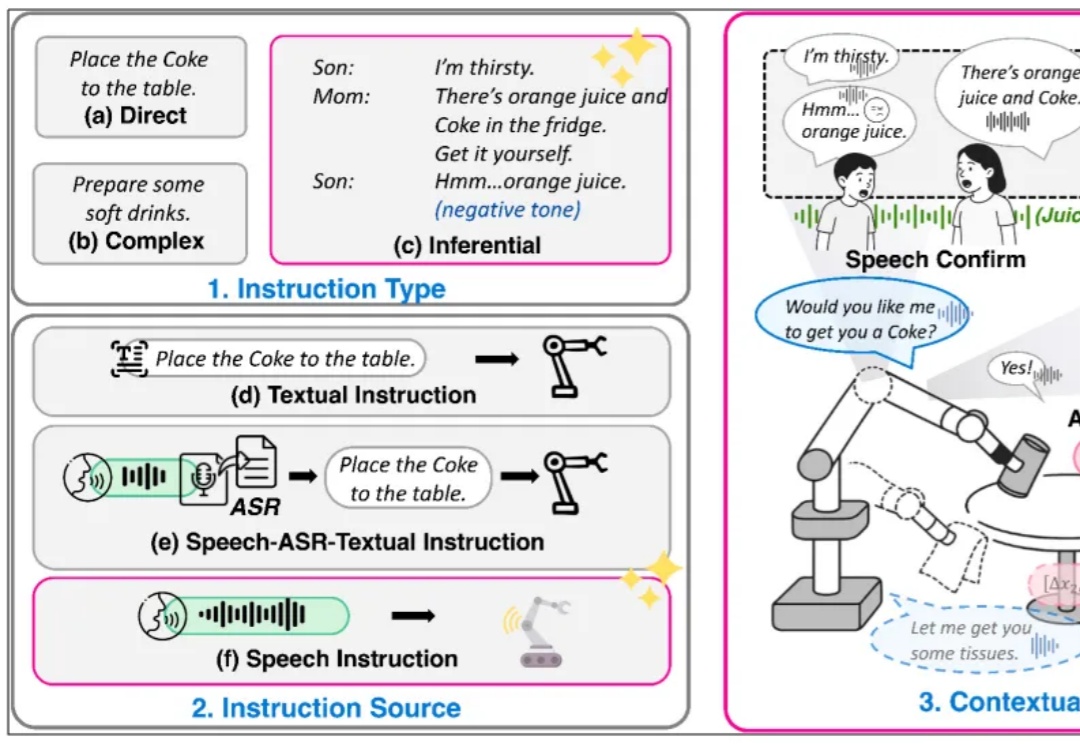
从VLA到RoboOmni,全模态具身新范式让机器人察言观色、听懂话外音复旦⼤学、上海创智学院与新加坡国立⼤学联合推出全模态端到端操作⼤模型 RoboOmni,统⼀视觉、⽂本、听觉与动作模态,实现动作⽣成与语⾳交互的协同控制。开源 140K 条语⾳ - 视觉 - ⽂字「情境指令」真机操作数据,引领机器⼈从「被动执⾏⼈类指令」迈向「主动提供服务」新时代。
来自主题: AI技术研报
9076 点击 2025-11-12 09:29