
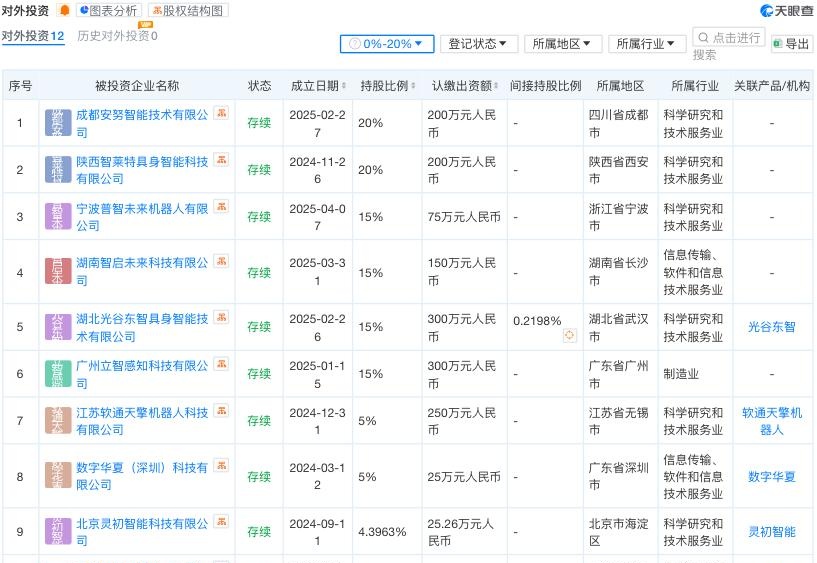
估值超150亿的智元机器人,正加速投资
估值超150亿的智元机器人,正加速投资将资源和资金用在产业链投资上,“物尽其用、财尽其力”。
来自主题: AI资讯
9202 点击 2025-04-15 11:14
将资源和资金用在产业链投资上,“物尽其用、财尽其力”。

Figure公司通过强化学习,成功实现机器人的自然步态。利用高效物理模拟器,仅用几小时完成相当于多年训练的数据,训练出的策略无需额外调整即可「零样本」迁移至真实机器人。
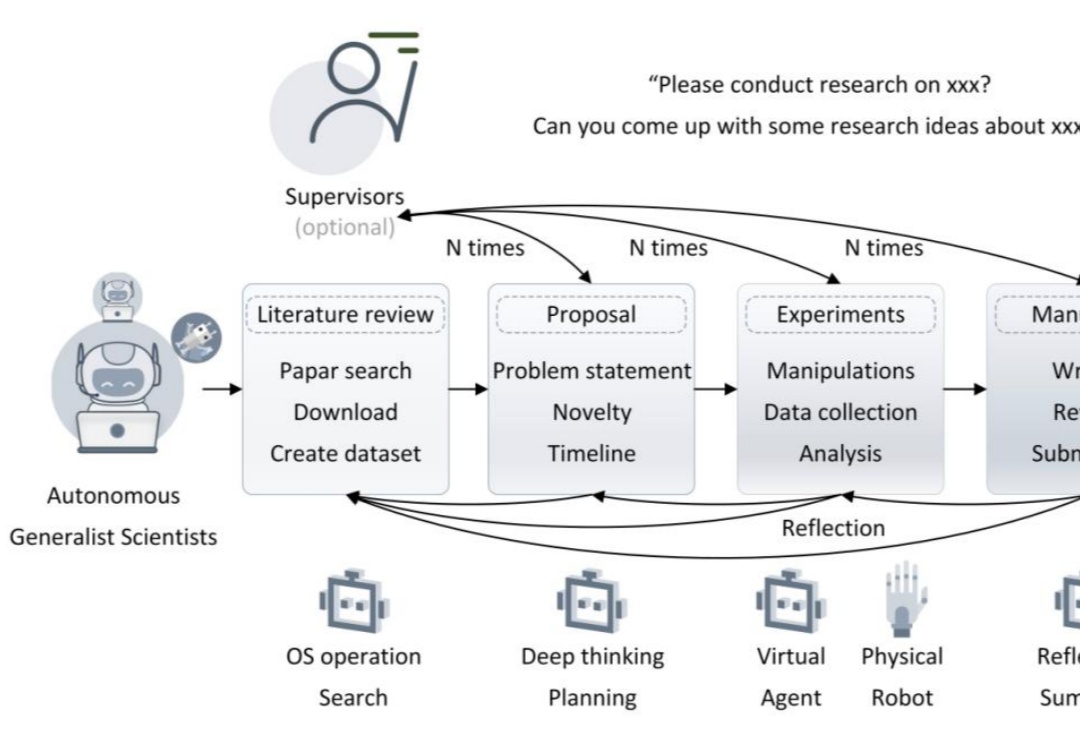
自主通才科学家的 5 个层级。
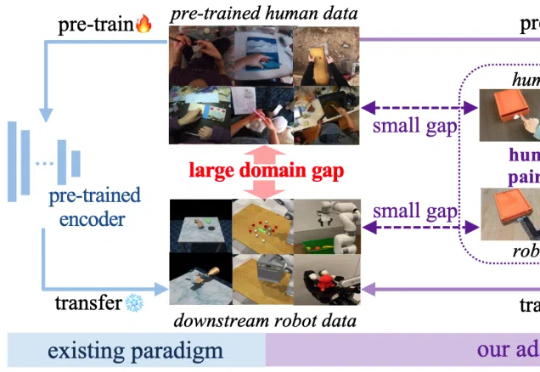
“让机器人看懂世界、听懂指令、动手干活”正从科幻走向现实。

上海人形机器人玩家傅利叶,首款开源产品来了!刚刚,发布小·人形机器人——Fourier N1。据了解,首批开源内容,可以直接实现本体以及走路和小跑功能,未来傅利叶还将持续更新推理代码和训练框架,确保上述功能都能复现。

好莱坞科幻大片《铁甲钢拳》就这样被宇树机器人实现了?!

近日,星尘智能连续完成A轮及A+轮融资数亿元,由锦秋基金、蚂蚁集团领投,云启资本、道彤资本等老股东跟投,华兴资本担任独家财务顾问。

在现实世界中,如何让智能体理解并挖掘 3D 场景中可交互的部位(Affordance)对于机器人操作与人机交互至关重要。所谓 3D Affordance Learning,就是希望模型能够根据视觉和语言线索,自动推理出物体可供哪些操作、以及可交互区域的空间位置,从而为机器人或人工智能系统提供对物体潜在操作方式的理解。
OpenAI 竞争对手Anthropic ,计划为其 Claude 聊天机器人推出价格更高的订阅选项。2025 年 3 月,Anthropic 以 615 亿美元的估值完成了 35 亿美元的融资交易,巩固了其作为全球最大初创企业之一的地位。

大规模数据集和标准化评估基准显著促进了自然语言处理和计算机视觉领域的发展。然而,机器人领域在如何构建大规模数据集并建立可靠的评估体系方面仍面临巨大挑战。