
又一国产图像大模型开源!实测连续P图绝了,中文渲染是短板
又一国产图像大模型开源!实测连续P图绝了,中文渲染是短板今日,美团正式发布并开源图像生成模型LongCat-Image,这是一款在图像编辑能力上达到开源SOTA水准的6B参数模型,重点瞄准文生图与单图编辑两大核心场景。在实际体验中,它在连续改图、风格变化和材质细节上表现较好,但在复杂排版场景下,中文文字渲染仍存在不稳定的情况。
来自主题: AI资讯
8225 点击 2025-12-08 19:51
今日,美团正式发布并开源图像生成模型LongCat-Image,这是一款在图像编辑能力上达到开源SOTA水准的6B参数模型,重点瞄准文生图与单图编辑两大核心场景。在实际体验中,它在连续改图、风格变化和材质细节上表现较好,但在复杂排版场景下,中文文字渲染仍存在不稳定的情况。
李笛携原小冰核心团队创立新公司“明日新程”(Nextie),聚焦群体智能与认知大模型,推出内测产品“团子”,通过多智能体协作提升AI认知能力,计划2026年1月7日上线。奇绩创坛参与投资。

目标物理世界的“ChatGPT时刻”。

今年以来,开源项目LightX2V 及其 4 步视频生成蒸馏模型在 ComfyUI 社区迅速走红,单月下载量超过 170 万次。越来越多创作者用它在消费级显卡上完成高质量视频生成,把“等几分钟出一段视频”变成“边看边出片”。

最近,Google Research 发布了一篇 Blog《Titans + MIRAS:帮助人工智能拥有长期记忆》。它们允许 AI 模型在运行过程中更新其核心内存,从而更快地工作并处理海量上下文。
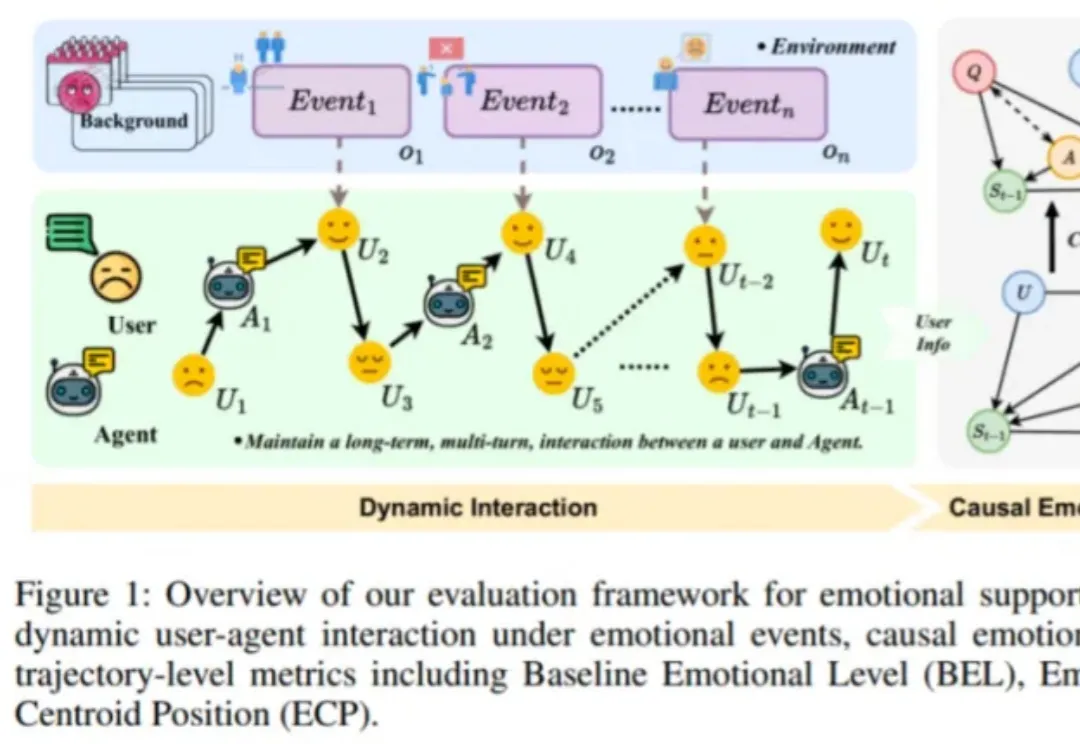
近日,由趣丸科技与北京大学软件工程国家工程研究中心共同发表的《Detecting Emotional Dynamic Trajectories: An Evaluation Framework for Emotional Support in Language Models(检测情感动态轨迹:大语言模型情感支持的评估框架)》论文,获 AAAI 2026 录用。

12 月 1 日,DeepSeek 一口气发布了两款新模型:DeepSeek-V3.2 和 DeepSeek-V3.2-Speciale。几天过去,热度依旧不减,解读其技术报告的博客也正在不断涌现。知名 AI 研究者和博主 Sebastian Raschka 发布这篇深度博客尤其值得一读,其详细梳理了 DeepSeek V3 到 V3.2 的进化历程。

在Alpha Arena 1.5赛季的美股真金白银实盘中,Grok 4.20完胜GPT-5.1和Gemini 3.0 Pro等一众顶流模型,在对手全线亏损的情况下,独自斩获了12.11%的正收益。成功背后的秘密是Grok对X的推文反映的市场情绪的及时精准捕捉。
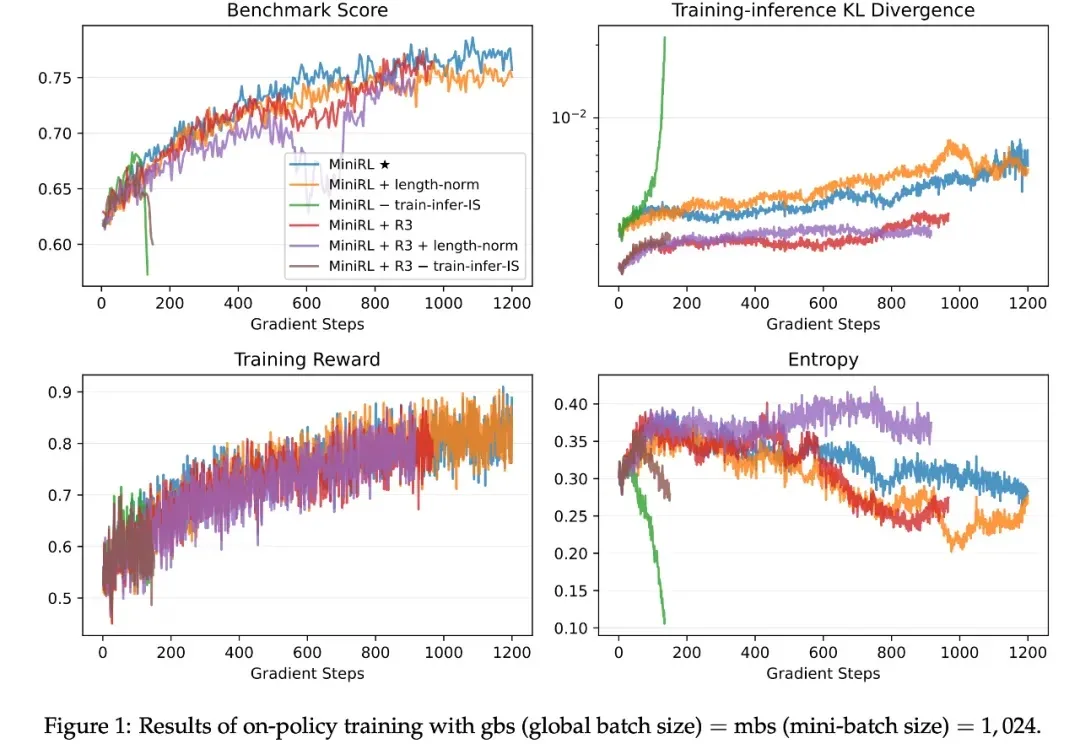
如今,强化学习(RL)已成为提升大语言模型(LLM)复杂推理与解题能力的关键技术范式,而稳定的训练过程对于成功扩展 RL 至关重要。由于语言具有强烈的上下文属性,LLM 的 RL 通常依赖序列级奖励 —— 即根据完整生成序列给一个标量分数。

国内记忆框架首开源,企业实战已上线运行。在海外巨头已经将“记忆系统”提升到基础设施层的同时,红熊AI便是其中之一。公司成立于2024年,围绕多模态大模型与记忆科学开展研发,并将这些能力用于为企业提供智能客服、营销自动化与AI智能体服务。