

商汤分拆了一家AI医疗公司,半年融资10亿,剑指“医疗世界模型”
商汤分拆了一家AI医疗公司,半年融资10亿,剑指“医疗世界模型”商汤分拆了一家AI医疗公司,半年内迅速跻身准独角兽行列。
来自主题: AI资讯
10578 点击 2025-12-03 10:42
商汤分拆了一家AI医疗公司,半年内迅速跻身准独角兽行列。

近日,清华大学深圳国际研究生院的机器人博士团队创办的「知有无界」获得卓源亚洲领投、力合科创跟投的种子轮融资。「知有无界」诞生在清华大学王学谦教授的智能机器人实验室,实现了全球首个船舶具身通用大模型,本轮融资后,「知有无界」将会进一步加快在船坞的商业化落地,并持续进行多代产品的研发。
大模型最广泛的应用如 ChatGPT、Deepseek、千问、豆包、Gemini 等通常会连接互联网进行检索增强生成(RAG)来产生用户问题的答案。随着多模态大模型(MLLMs)的崛起,大模型的主流技术之一 RAG 迅速向多模态发展,形成多模态检索增强生成(MM-RAG)这个新兴领域。ChatGPT、千问、豆包、Gemini 都开始允许用户提供文字、图片等多种模态的输入。

“既然我可以直接使用 PyTorch,为什么还要费心使用 CUDA 呢?”

刚刚,「欧洲的 DeepSeek」Mistral AI 刚刚发布了新一代的开放模型 Mistral 3 系列模型。该系列有多个模型,具体包括:「世界上最好的小型模型」:Ministral 3(14B、8B、3B),每个模型都发布了基础版、指令微调版和推理版。

VLA模型性能暴涨300%,背后训练数据还首次实现90%由世界模型生成。

在 Vision-Language Model 领域,提升其复杂推理能力通常依赖于耗费巨大的人工标注数据或启发式奖励。这不仅成本高昂,且难以规模化。

斯坦福和MIT的研究团队推出了一种新的AI智能体推理框架ReCAP,在长上下文任务中全面超越了现有的主流框架ReAct,性能提升显著。ReCAP通过独特的递归树结构和三大机制,解决了大语言模型在复杂任务中常见的目标漂移、上下文断层和成本爆炸等问题。
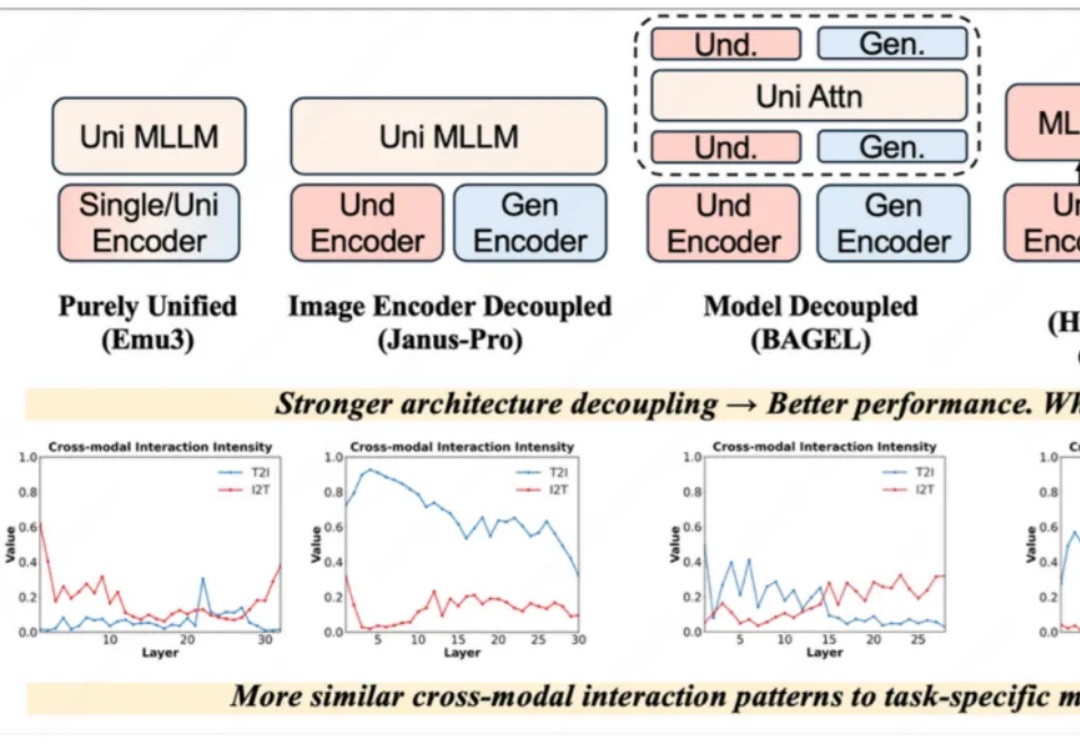
近一年以来,统一理解与生成模型发展十分迅速,该任务的主要挑战在于视觉理解和生成任务本身在网络层间会产生冲突。早期的完全统一模型(如 Emu3)与单任务的方法差距巨大,Janus-Pro、BAGEL 通过一步一步解耦模型架构,极大地减小了与单任务模型的性能差距,后续方法甚至通过直接拼接现有理解和生成模型以达到极致的性能。

在美国也出现了一种“开源重新兴起”的现象,某种意义上是对中国发展的反应。所以美国开始重新推动大量开源。