
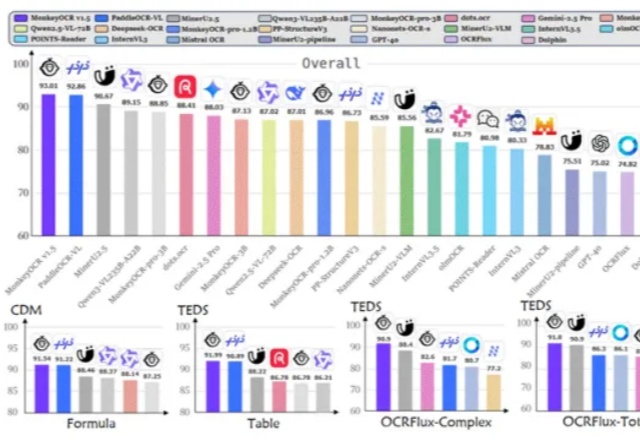
金山与华科发布多模态模型MonkeyOCR v1.5:文档解析能力超越PaddleOCR-VL,复杂表格解析首次突破90%
金山与华科发布多模态模型MonkeyOCR v1.5:文档解析能力超越PaddleOCR-VL,复杂表格解析首次突破90%是金山派来的猴子,复杂文档解析有救了!
来自主题: AI技术研报
11236 点击 2025-11-18 15:16
是金山派来的猴子,复杂文档解析有救了!
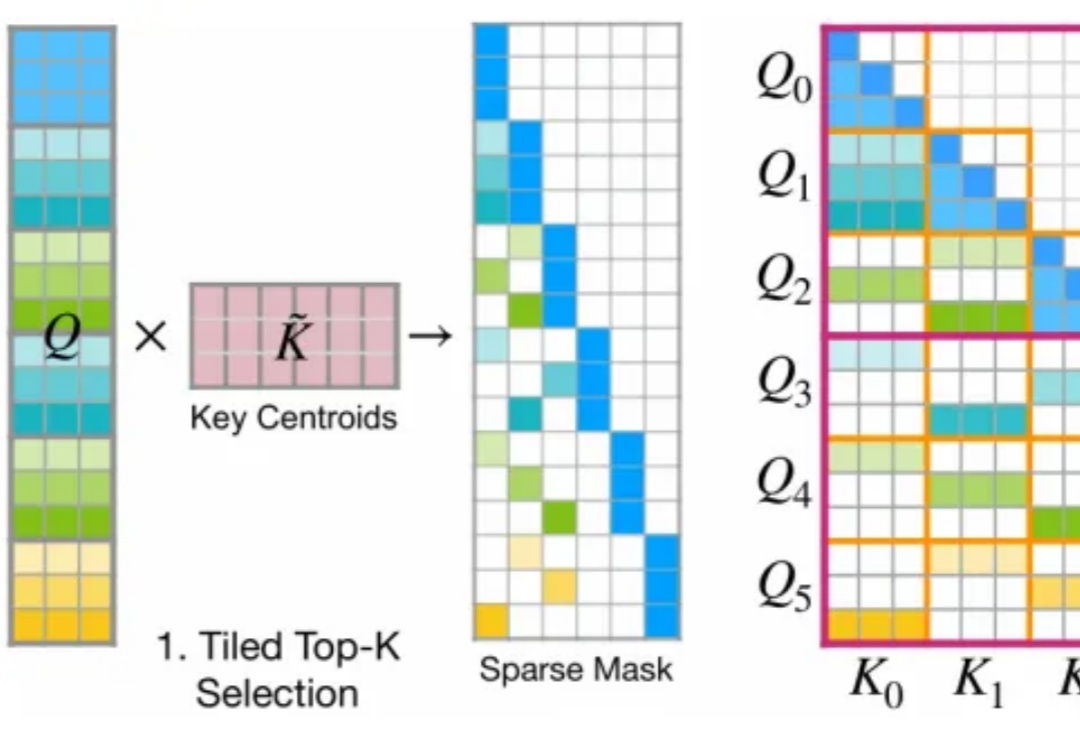
今年 2 月,月之暗面提出了一种名为 MoBA 的注意力机制,即 Mixture of Block Attention,可以直译为「块注意力混合」。
如果多个大模型能读懂彼此的想法,会发生什么?

单Transformer搞定任意视图3D重建!
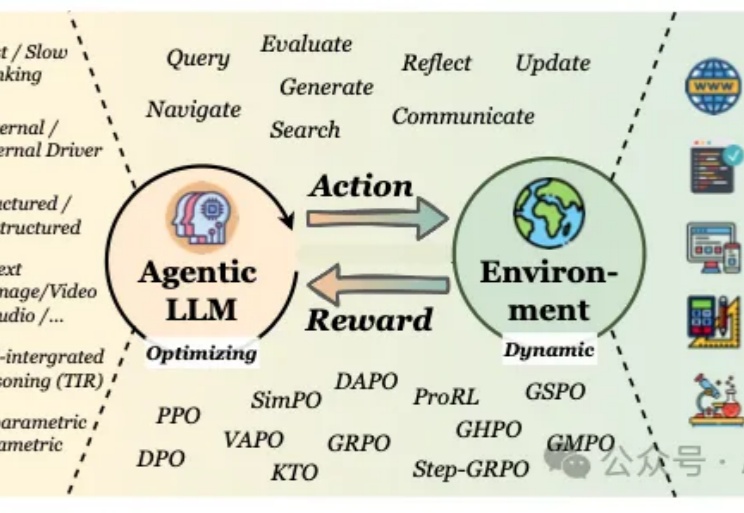
当我们谈论大型语言模型(LLM)的"强化学习"(RL)时,我们在谈论什么?从去年至今,RL可以说是当前AI领域最炙手可热的词汇。
最近,小编注意到一位全栈工程师 Rohith Singh 在Reddit上发表了一篇帖子,介绍他如何对四个模型(Kimi K2 Thinking、Sonnet 4.5、GPT-5 Codex 和 GPT-5.1 Codex)进行了实测。
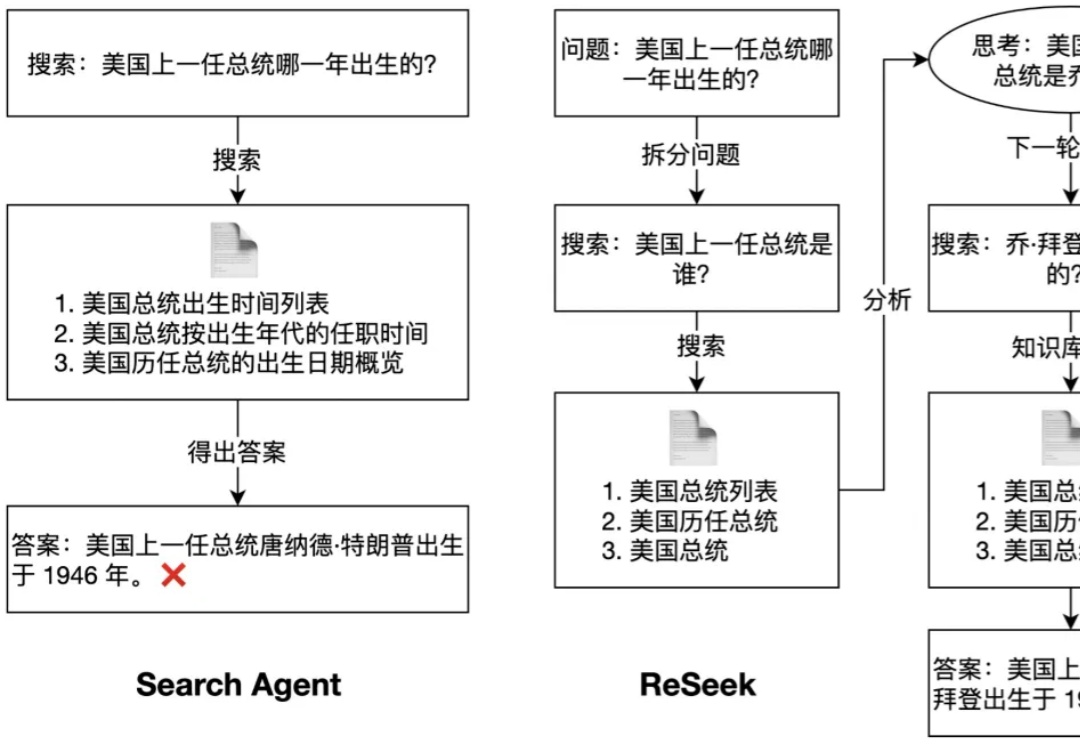
为了同时解决知识的实时性和推理的复杂性这两大挑战,搜索智能体(Search Agent)应运而生。它与 RAG 的核心区别在于,Search Agent 能够通过与实时搜索引擎进行多轮交互来分解并执行复杂任务。这种能力在人物画像构建,偏好搜索等任务中至关重要,因为它能模拟人类专家进行深度、实时的资料挖掘。

基层医生的AI好助手来了!国产AI,更懂中国医生。

GPT-5不再只是更聪明的模型,而是一台学会犹豫的机器。它能判断问题的难度,分配自己的思考时间,甚至决定何时该停下。OpenAI副总裁Jerry Tworek在最新访谈中透露:GPT-5的真正突破,是让AI拥有了「时间感」。当机器学会克制,人类却愈加焦躁。也许我们教给AI的,不只是如何思考,而是如何重新做人。

我们的大脑蕴藏着待解的进化密码,而AI的未来或许正系于此。