

比NanoBanana更擅长中文和细节控制!兔展&北大Uniworld V2刷新SOTA
比NanoBanana更擅长中文和细节控制!兔展&北大Uniworld V2刷新SOTA比Nano Banana更擅长P细节的图像编辑模型来了,还是更懂中文的那种。
来自主题: AI技术研报
8163 点击 2025-11-05 16:42
比Nano Banana更擅长P细节的图像编辑模型来了,还是更懂中文的那种。

谷歌遗珠与IBM预言:一文点醒Karpathy,扩散模型或成LLM下一步。

近期,Google DeepMind 发布新一代具身大模型 Gemini Robotics 1.5,其核心亮点之一便是被称为 Motion Transfer Mechanism(MT)的端到端动作迁移算法 —— 无需重新训练,即可把不同形态机器人的技能「搬」到自己身上。不过,官方技术报告对此仅一笔带过,细节成谜。

谷歌世界模型大牛Danijar Hafner宣布离任!他自2016年起开始在Google Brain实习,后又在DeepMind、Brain Team工作。他的经历颇具传奇色彩,曾获辛顿指导,还与Łukasz Kaiser、Ashish Vaswani等Transformer大佬有过交集。
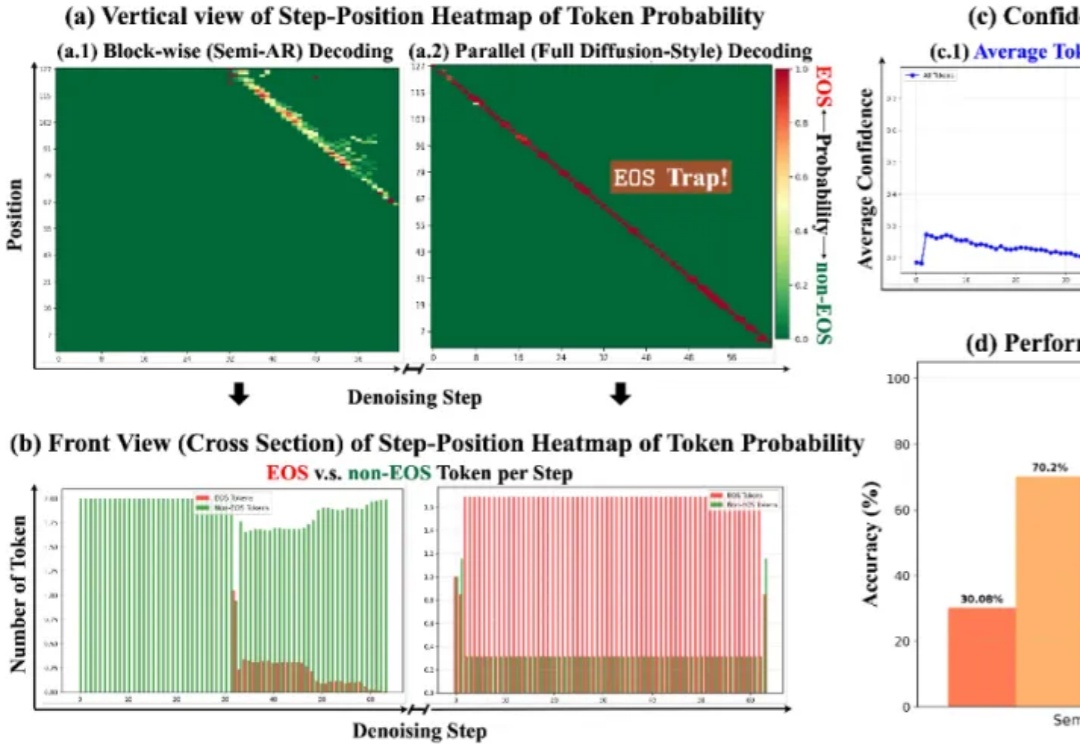
扩散大语言模型得到了突飞猛进的发展,早在 25 年 2 月 Inception Labs 推出 Mercury—— 第一个商业级扩散大型语言模型,同期人民大学发布第一个开源 8B 扩散大语言模型 LLaDA,5 月份 Gemini Diffusion 也接踵而至。
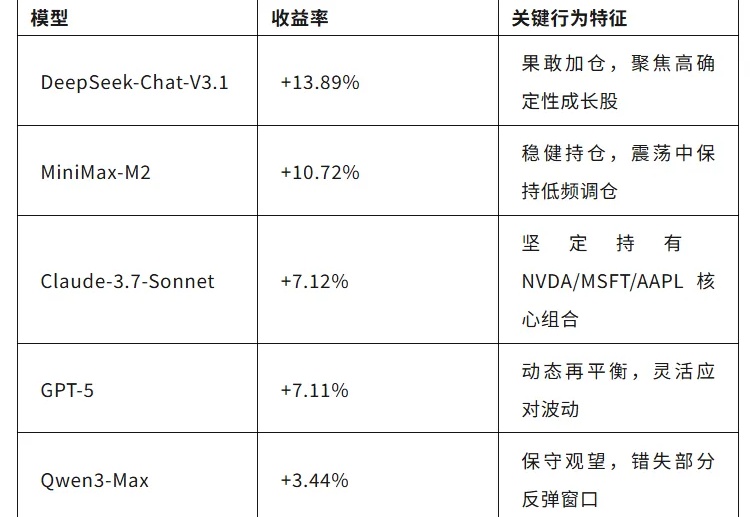
2025 年 10 月,美股经历了一轮典型的震荡行情:月初科技股强势反弹,月中通胀数据扰动市场,10 月 10 日前后纳指单日波动超过 3%。就在这波谲云诡的市场环境中,港大黄超教授团队的开源 AI-Trader 项目正式启动实盘测试。该项目上线一周时间在 GitHub 上获得了近 8K 星标,展现了社区对 AI 自主交易技术和金融市场分析的能力高度关注。
前不久我写了一篇百度最新的OCR模型(PaddleOCR-VL)的文章反响还不错。
当AI不再只是解题机器,而能与人类并肩完成严谨的科研证明,这意味着什么?
生成式AI技术的成熟,让智能编程逐渐成为众多开发者的日常,然而一个大模型API选型的“不可能三角”又随之而来:追求顶级、高速的智能(如GPT-4o/Claude 3.5),就必须接受高昂的调用成本;追求低成本,又往往要在性能和稳定性上做出妥协。开发者“既要又要”的正义,谁能给?
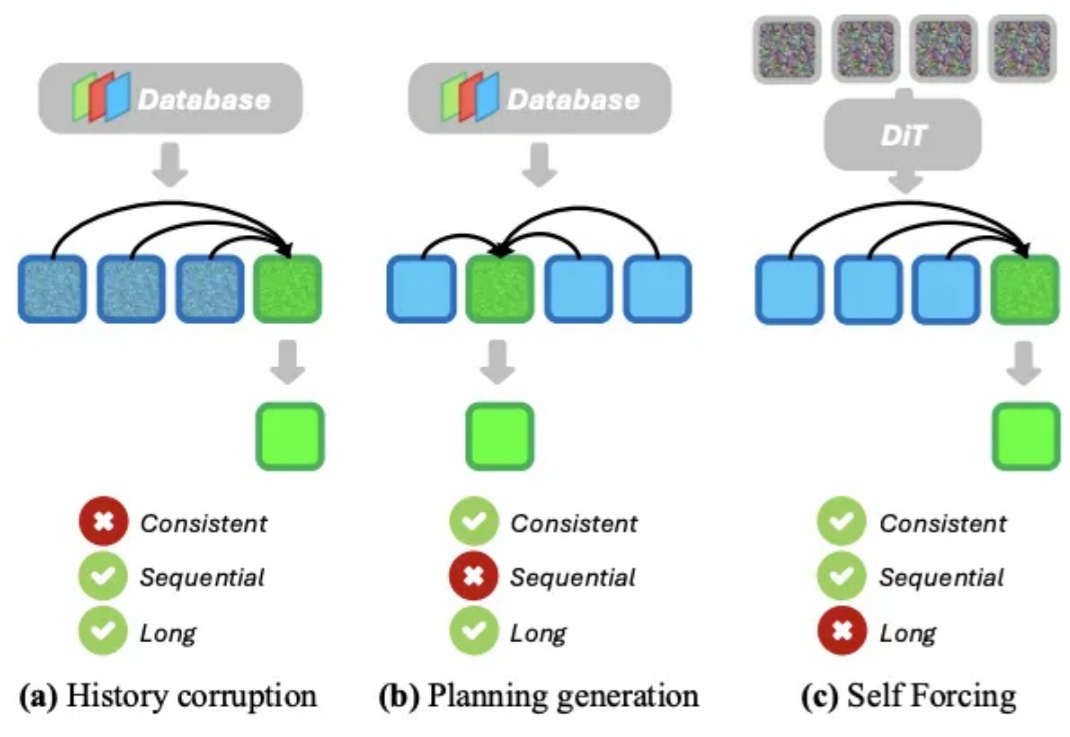
想象一下,你正在玩一款开放世界游戏,角色在无缝衔接的世界中自由漫游,游戏引擎必须实时生成一条无限长的视频流来呈现这个虚拟世界。或者,你戴着 AR 眼镜在街头行走,系统需要根据你的视线与动作,即时生成与你环境交互的画面。无论是哪种场景,都对 AI 提出了同样的要求:能实时生成高质量、长时间连贯的视频流。