

相机参数秒变图片!新模型打通理解生成壁垒,支持任意视角图像创作
相机参数秒变图片!新模型打通理解生成壁垒,支持任意视角图像创作能看懂相机参数,并且生成相应视角图片的多模态模型来了。
来自主题: AI技术研报
4586 点击 2025-10-28 13:57
能看懂相机参数,并且生成相应视角图片的多模态模型来了。

周日晚上,都准备去睡觉了。结果在 X 上刷到一条消息,有个国外的博主说,MiniMax 的 M2 模型将会成为中国最好的模型,与 Sonnet 4.5 旗鼓相当。 我当时心里咯噔一下。MiniMax?
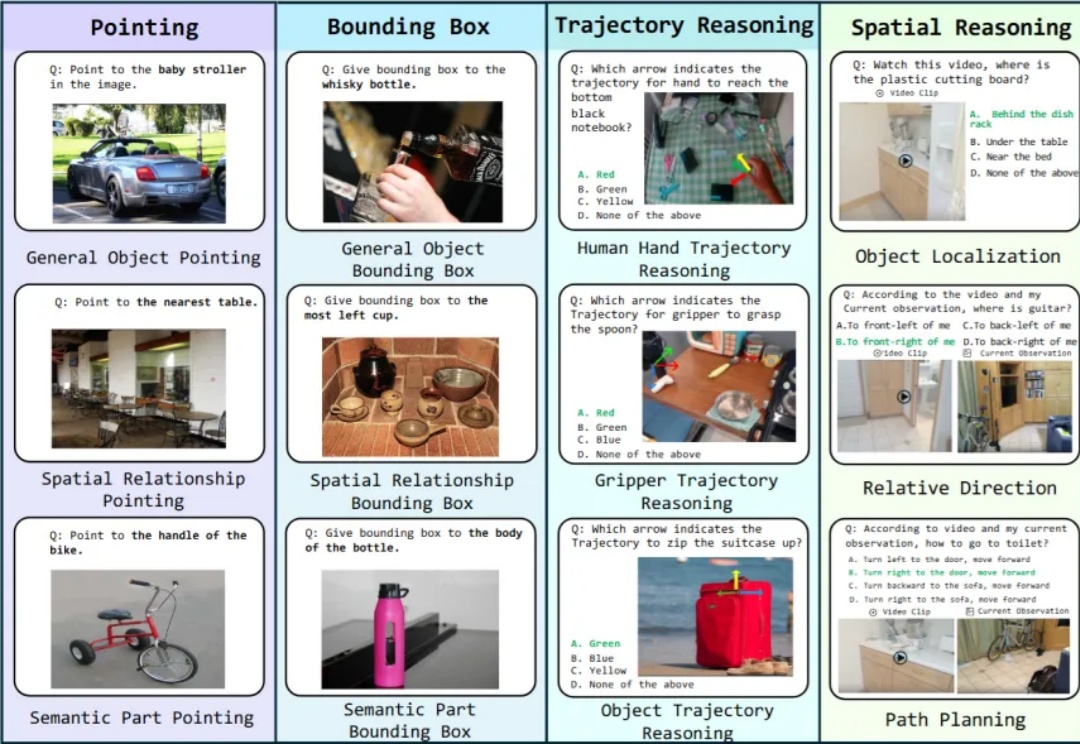
具身智能是近年来非常火概念。一个智能体(比如人)能够在环境中完成感知、理解与决策的闭环,并通过环境反馈不断进入新一轮循环,直至任务完成。这一过程往往依赖多种技能,涵盖了底层视觉对齐,空间感知,到上层决策的不同能力,这些能力便是广义上的具身智能。
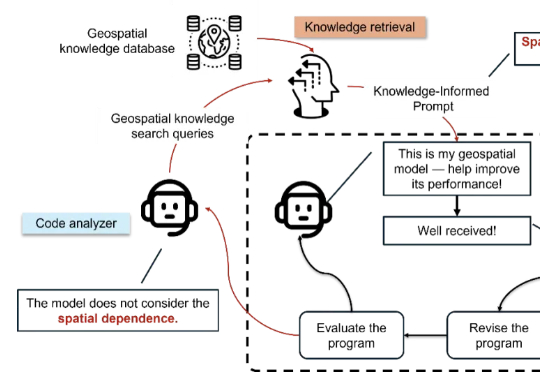
让AI懂地理,它才会走得更远。GeoEvolve让AI从助理变成「地理学博士生」,自己修bug、改算法、进化模型——这下,科学家可能真的要有个AI同事了。MIT和斯坦福学者提出了GeoEvolve,尝试了这样一种探索:

近日,在 CNCC2025 大会上,郑波首次公开了淘宝全模态大模型的最新进展,并系统介绍了多模态智能在淘宝 AIGX 技术体系的研究应用。另外,结合 AI 模型技术在淘宝应用中的实践,他认为,「狭义 AGI 很可能在 5-10 年内到来。」
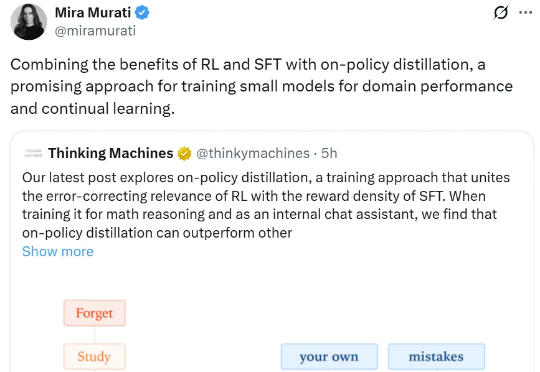
刚刚,不发论文、爱发博客的 Thinking Machines Lab (以下简称 TML)再次更新,发布了一篇题为《在策略蒸馏》的博客。在策略蒸馏(on-policy distillation)是一种将强化学习 (RL) 的纠错相关性与 SFT 的奖励密度相结合的训练方法。在将其用于数学推理和内部聊天助手时,TML 发现在策略蒸馏可以极低的成本超越其他方法。

2023 年的秋天,当全世界都在为 ChatGPT 和大语言模型疯狂的时候,远在澳大利亚悉尼的一对兄弟却在为一个看似简单的问题发愁:为什么微调一个开源模型要花这么长时间,还要用那么昂贵的 GPU?

预训练的核心是推动损失函数下降,这是我们一直追求的唯一目标。
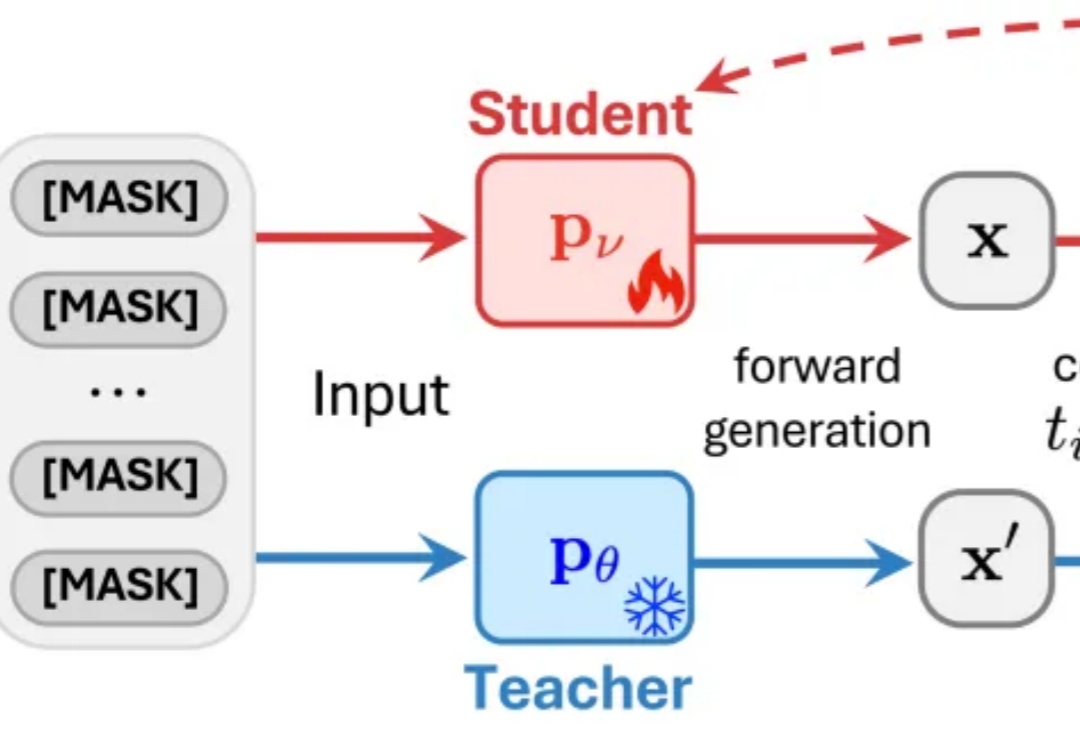
近日,来自普渡大学、德克萨斯大学、新加坡国立大学、摩根士丹利机器学习研究、小红书 hi-lab 的研究者联合提出了一种对离散扩散大语言模型的后训练方法 —— Discrete Diffusion Divergence Instruct (DiDi-Instruct)。经过 DiDi-Instruct 后训练的扩散大语言模型可以以 60 倍的加速超越传统的 GPT 模型和扩散大语言模型。

当今的 AI 智能体(Agent)越来越强大,尤其是像 VLM(视觉-语言模型)这样能「看懂」世界的智能体。但研究者发现一个大问题:相比于只处理文本的 LLM 智能体,VLM 智能体在面对复杂的视觉任务时,常常表现得像一个「莽撞的执行者」,而不是一个「深思熟虑的思考者」。