

OpenAI秘密项目曝出!百名投行精英密训AI,华尔街最贵苦力要失业了?
OpenAI秘密项目曝出!百名投行精英密训AI,华尔街最贵苦力要失业了?刚刚,OpenAI内部秘密项目「Mercury」(水星)曝出!该项目正高薪招募百名前投行精英训练财务模型,旨在替代初级银行家的重复性工作。业内普遍认为,这是OpenAI在算力成本高企背景下,加速商业化与盈利的关键一步。
来自主题: AI资讯
9746 点击 2025-10-24 10:41
刚刚,OpenAI内部秘密项目「Mercury」(水星)曝出!该项目正高薪招募百名前投行精英训练财务模型,旨在替代初级银行家的重复性工作。业内普遍认为,这是OpenAI在算力成本高企背景下,加速商业化与盈利的关键一步。

强化学习能力强大,几乎已经成为推理模型训练流程中的标配,也有不少研究者在探索强化学习可以为大模型带来哪些涌现行为。

在最近一篇来自Meta FAIR团队的论文里,研究者找到了一种前所未有的方式——他们能实时看到AI的思考过程。这项名为CRV的方法,通过替换模型内部的MLP模块,让每一步推理都变得「可见」。这不是隐喻,而是可量化的现象。Meta用它让错误检测精度提升到92.47%,也让人类第一次得以窥见AI是怎么想错的。

在大模型微调实践中,SFT(监督微调)几乎成为主流流程的一部分,被广泛应用于各类下游任务和专用场景。比如,在医疗领域,研究人员往往会用领域专属数据对大模型进行微调,从而显著提升模型在该领域特定任务上的表现。
TechCrunch 报道,之前一直以 AI 语音初创公司示人的 Sesame,完成了 2.5 亿美元的 B 轮融资,投资方包括红杉资本、Spark Capital 及其他未公开的投资者。随后,Sesame 创始人 Brendan Iribe 也在个人社媒账号上发帖,证实该消息。

AI编程领域竞争正酣。就在DeepSeek、阿里、Google、OpenAI等巨头纷纷展示最新代码生成能力之际,快手也交出了一份重量级答卷——发布AI编程产品矩阵,正式宣布进军AI Coding赛道。

全球六大LLM实盘厮杀,新王登基!今天,Qwen3 Max凭借一波「快狠准」操作,逆袭DeepSeek夺下第一。Qwen3 Max,一骑绝尘! 而GPT-5则接替Gemini 2.5 Pro,成为「最会赔钱」的AI。照目前这个趋势,估计很快就要跌没了……
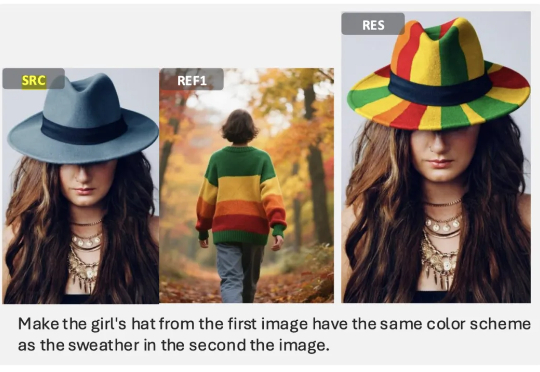
两周前,港科大讲座教授、冯诺依曼研究院院长贾佳亚团队开源了他们的最新成果 DreamOmni2,专门针对当前多模态指令编辑与生成两大方向的短板进行了系统性优化与升级。该系统基于 FLUX-Kontext 训练,保留原有的指令编辑与文生图能力,并拓展出多参考图的生成编辑能力,给予了创作者更高的灵活性与可玩性。

啥情况,马斯克在𝕏上直接锐评Claude「邪恶透顶」:这次起因是这样的,最新研究发现,Claude Sonnet 4.5竟然认为尼日利亚人的生命价值是德国人的27倍。具体而言,在面对不同国家的绝症患者时,Claude「清醒」得有点吓人——

当前的训练与评测范式存在一个根本性的局限:几乎所有主流 Benchmark(如 MATH500、AIME)都聚焦于孤立的单步问题,问题之间相互独立,模型只需「回答一个问题,然后结束」。但真实世界的推理场景往往截然不同: 为填补这一空白,复旦大学与美团 LongCat Team 联合推出 R-HORIZON—— 首个系统性评估与增强 LRMs 长链推理能力的方法与基准。