

大模型中毒记
大模型中毒记那个叫大模型的高手,被下毒了
来自主题: AI资讯
8241 点击 2025-10-21 10:09
那个叫大模型的高手,被下毒了

复旦大学NLP实验室研发Game-RL,利用游戏丰富视觉元素和明确规则生成多模态可验证推理数据,通过强化训练提升视觉语言模型的推理能力。创新性地提出Code2Logic方法,系统化合成游戏任务数据,构建GameQA数据集,验证了游戏数据在复杂推理训练中的优势。

AI 会写字吗?在写字机器人衍生换代的今天,你或许并不觉得 AI 写字有多么困难。

刚刚,DeepSeek 推出了全新的视觉文本压缩模型 DeepSeek-OCR。 该模型最大的突破在于极高的压缩效率: 20 个节点每天可处理 3300 万页数据,硬件要求仅为 A100-40G。

美国麻省理工学院李巨团队在国际顶尖学术期刊Nature上发表了一篇研究论文,展示了一种多模态机器人平台CRESt(Copilot for Real-world Experimental Scientists),通过将多模态模型(融合文本知识、化学成分以及微观结构信息)驱动的材料设计与高通量自动化实验相结合,大幅提升催化剂的研发速度和质量。

在某种程度上,GPT-5可以被视作是o3.1。 该观点出自OpenAI研究副总裁Jerry Tworek的首次播客采访,而Jerry其人,正是o1模型的主导者之一。
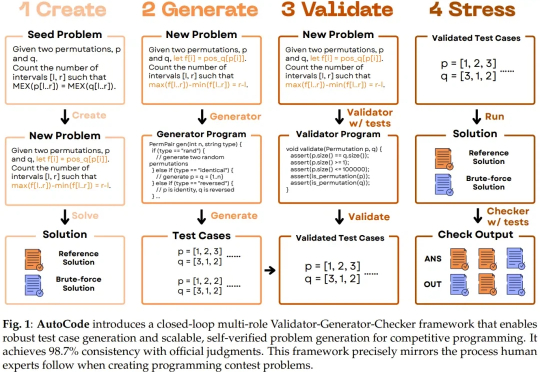
随着大型语言模型(LLM)朝着通用能力迈进,并以通用人工智能(AGI)为最终目标,测试其生成问题的能力也正变得越来越重要。尤其是在将 LLM 应用于高级编程任务时,因为未来 LLM 编程能力的发展和经济整合将需要大量的验证工作。
“很多模型在模拟器里完美运行,但一到现实就彻底失灵。” 在最新一次线上对谈中,Dexmal联合创始人唐文斌与Hugging Face联合创始人Thomas Wolf指出了当前机器人研究的最大痛点。
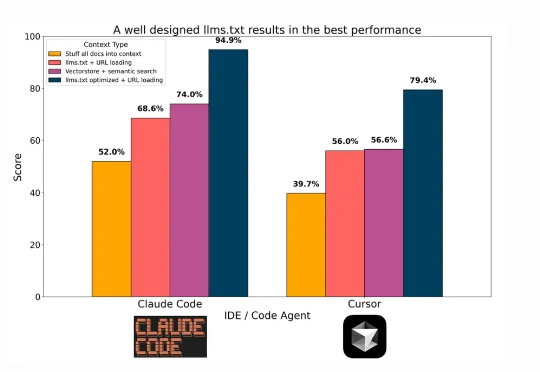
在技术飞速更新迭代的今天,每隔一段时间就会出现「XX 已死」的论调。「搜索已死」、「Prompt 已死」的余音未散,如今矛头又直指 RAG。
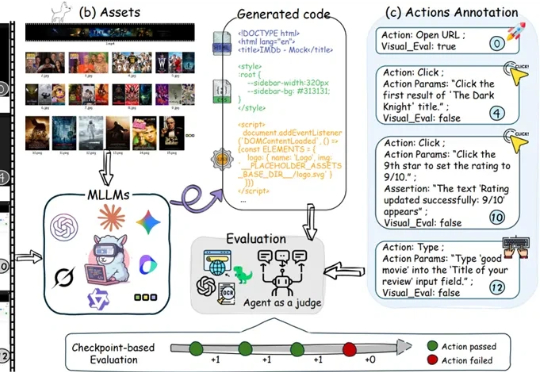
多模态大模型在根据静态截图生成网页代码(Image-to-Code)方面已展现出不俗能力,这让许多人对AI自动化前端开发充满期待。