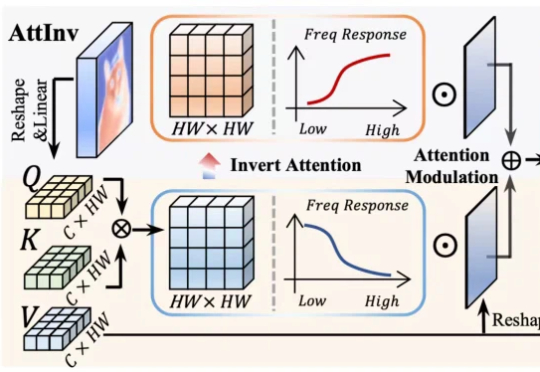
NeurIPS 2025 Spotlight | 条件表征学习:一步对齐表征与准则
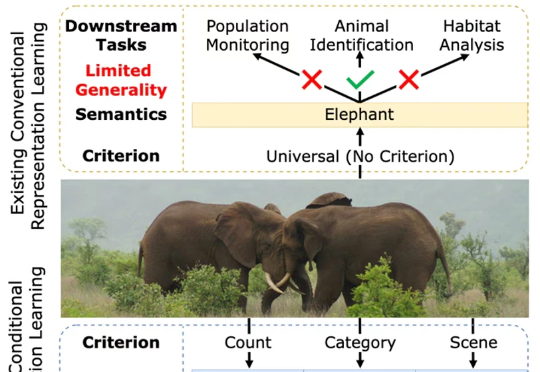
NeurIPS 2025 Spotlight | 条件表征学习:一步对齐表征与准则一张图片包含的信息是多维的。例如下面的图 1,我们至少可以得到三个层面的信息:主体是大象,数量有两头,环境是热带稀树草原(savanna)。然而,如果由传统的表征学习方法来处理这张图片,比方说就将其送入一个在 ImageNet 上训练好的 ResNet 或者 Vision Transformer,往往得到的表征只会体现其主体信息,也就是会简单地将该图片归为大象这一类别。这显然是不合理的。
来自主题: AI技术研报
7622 点击 2025-10-16 14:43