

刚刚,北大&360里程碑式突破!32B安全分碾压千亿巨兽
刚刚,北大&360里程碑式突破!32B安全分碾压千亿巨兽打破思维惯性,「小模型」也能安全又强大!北大-360联合实验室发布TinyR1-32B模型,以仅20k数据的微调,实现了安全性能的里程碑式突破,并兼顾出色的推理与通用能力。
来自主题: AI资讯
8166 点击 2025-09-28 09:54
打破思维惯性,「小模型」也能安全又强大!北大-360联合实验室发布TinyR1-32B模型,以仅20k数据的微调,实现了安全性能的里程碑式突破,并兼顾出色的推理与通用能力。
明星创业公司Thinking Machines,第二篇研究论文热乎出炉!公司创始人、OpenAI前CTO Mira Murati依旧亲自站台,翁荔等一众大佬也纷纷转发支持:论文主题为“Modular Manifolds”,通过让整个网络的不同层/模块在统一框架下进行约束和优化,来提升训练的稳定性和效率。
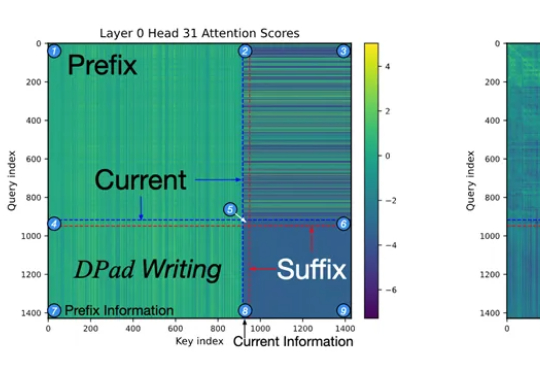
杜克大学团队发现,扩散大语言模型只需关注少量「中奖」token,就能在推理时把速度提升61-97倍,还能让模型更懂格式、更听话。新策略DPad不训练也能零成本挑出关键信息,实现「少算多准」的双赢。
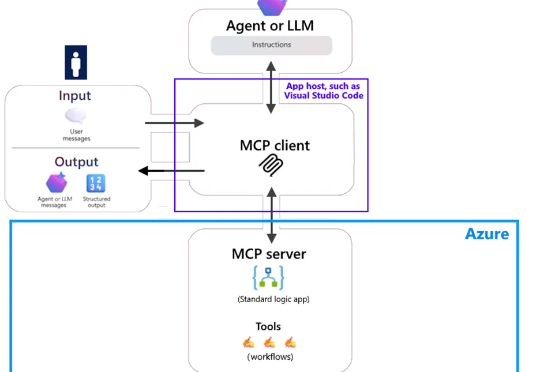
最近,微软宣布了一项新功能的公开预览。该功能使 Azure Logic Apps(标准版)能够充当 MCP 服务器,为开发者提供了一种灵活的方式来构建和管理代理。在 Azure Logic Apps 中,用户可以重新配置 Standard Logic App 使其充当远程模型上下文协议(MCP)服务器,快速启动这些工具的构建工作。

近日,为了加速多元素催化剂的发现与优化,美国麻省理工学院团队开发了一个多模态机器人平台——CRESt(Copilot for Real-world Experimental Scientists)。该平台能够结合自动化设备、大规模模型和实验室监测,在实验设计中融入人类经验、文献知识和显微结构信息,从而加速多元素催化剂的发现和优化加速发展。
在大模型训练时,如何管理权重、避免数值爆炸与丢失?Thinking Machines Lab 的新研究「模块流形」提出了一种新范式,它将传统「救火式」的数值修正,转变为「预防式」的约束优化,为更好地训练大模型提供了全新思路。
上周,一个做算法的朋友给我演示了用大模型生成电路原理图的过程。那个瞬间,我仿佛看到了未来的轮廓——当AI开始理解硬件设计,我们这些靠经验在竞争中胜出的工程师,出路在哪里?
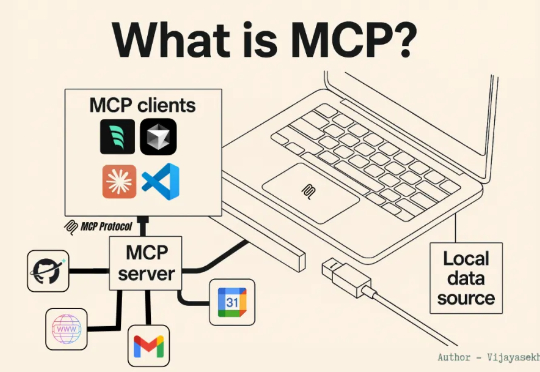
据 9to5Mac 报道,iOS 26.1、iPadOS 26.1 和 macOS Tahoe 26.1 开发者测试版隐藏的代码显示,苹果正在为 App Intents 引入 MCP 支持打基础。这也意味着未来,我们能让 ChatGPT、Claude 或其他任何兼容 MCP 的 AI 模型直接与 Mac、iPhone 和 iPad 应用交互。

奥特曼投下震撼弹:五年后AI将全面超越人类,到2030年诞生的「超级智能」甚至能攻克「量子引力」难题。人类智力的霸权时代,已进入倒计时。他在接受德国《世界报》采访时表示:我可以肯定地说,到2030年底之前,如果我们没能开发出能够完成人类自身无法企及任务的超级智能模型,我会感到非常意外。

业界首个高质量原生3D组件生成模型来了!来自腾讯混元3D团队。现有的3D生成算法通常会生成一体化的3D模型,而下游应用通常需要语义可分解的3D形状,即3D物体的每一个组件需要单独地生成出来。