突破后训练瓶颈?Meta超级智能实验室又一力作:CaT解决RL监督难题
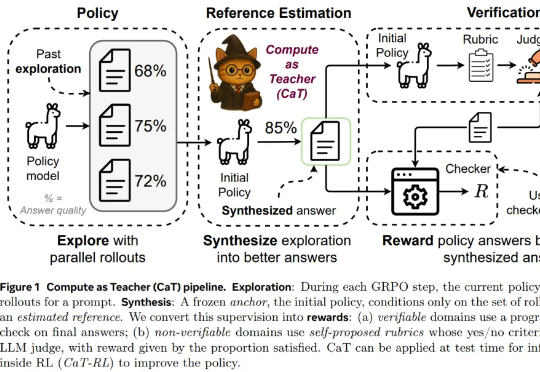
突破后训练瓶颈?Meta超级智能实验室又一力作:CaT解决RL监督难题为了回答这一问题,来自牛津大学、Meta 超级智能实验室等机构的研究者提出设想:推理计算是否可以替代缺失的监督?本文认为答案是肯定的,他们提出了一种名为 CaT(Compute as Teacher)的方法,核心思想是把推理时的额外计算当作教师信号,在缺乏人工标注或可验证答案时,也能为大模型提供监督信号。
来自主题: AI技术研报
6053 点击 2025-09-23 10:09