

GPT-5编程专用版发布!独立连续编程7小时,简单任务提速10倍,VS Code就能用
GPT-5编程专用版发布!独立连续编程7小时,简单任务提速10倍,VS Code就能用OpenAI Codex编程智能体大升级: 推出GPT-5-Codex特化版模型,支持独立连续编程7个小时。还有IDE插件版,在VS Code、Cursor中都可以使用Codex了。新模型最牛的地方在于“真·动态思考”能力。
来自主题: AI资讯
11101 点击 2025-09-16 09:31
OpenAI Codex编程智能体大升级: 推出GPT-5-Codex特化版模型,支持独立连续编程7个小时。还有IDE插件版,在VS Code、Cursor中都可以使用Codex了。新模型最牛的地方在于“真·动态思考”能力。

最强不敢说,但最快实锤了! 刚刚,xAI发布Grok 4 Fast,生成速度高达每秒75个 token,比标准版快10倍! 从下面的动图中,我们可以直观地看出差距——当左边的Grok 4还在说“让我想一下的时候”,Grok 4 Fast已经在说:“下一个问题是什么了。”

GPT-5 的发布,可以看作是一个分水岭。练习时长两年半的 GPT-5,并没有展现出和 GPT-4 本质上的差别,甚至因为模型的预设人格引发了用户的反感情绪。
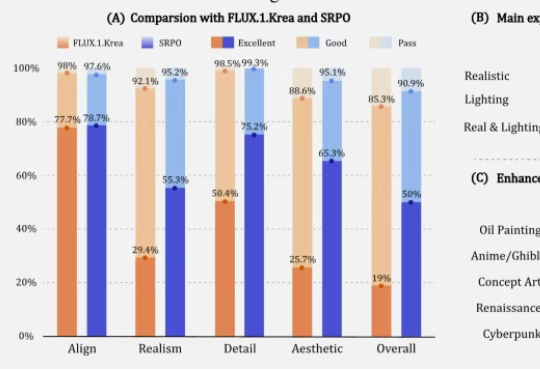
让AI生成的图像更符合人类精细偏好,在32块H20上训练10分钟就能收敛。腾讯混元新方法让微调的FLUX1.dev模型人工评估的真实感和美学评分提高3倍以上。

见过省电的模型,但这么省电的,还是第一次见。 在 《自然》 杂志发表的一篇论文中,加州大学洛杉矶分校 Shiqi Chen 等人描述了一种几乎不消耗电量的 AI 图像生成器的开发。

北京深度逻辑智能科技有限公司推出了 LLaSO—— 首个完全开放、端到端的语音语言模型研究框架。LLaSO 旨在为整个社区提供一个统一、透明且可复现的基础设施,其贡献是 “全家桶” 式的,包含了一整套开源的数据、基准和模型,希望以此加速 LSLM 领域的社区驱动式创新。

幻觉不是 bug,是数学上的宿命。 谢菲尔德大学的最新研究证明,大语言模型的幻觉问题在数学上不可避免—— 即使用完美的训练数据也无法根除。 而更为扎心的是,OpenAI 提出的置信度阈值方案虽能减少幻

只用 1.5% 的内存预算,性能就能超越使用完整 KV cache 的模型,这意味着大语言模型的推理成本可以大幅降低。EvolKV 的这一突破为实际部署中的内存优化提供了全新思路。

挑战自回归的扩散语言模型刚刚迎来了一个新里程碑:蚂蚁集团和人大联合团队用 20T 数据,从零训练出了业界首个原生 MoE 架构扩散语言模型 LLaDA-MoE。该模型虽然激活参数仅 1.4B,但性能可以比肩参数更多的自回归稠密模型 Qwen2.5-3B,而且推理速度更快。这为扩散语言模型的技术可行性提供了关键验证。
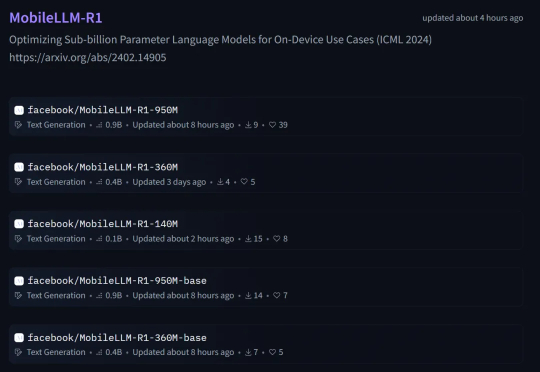
本周五,Meta AI 团队正式发布了 MobileLLM-R1。 这是 MobileLLM 的全新高效推理模型系列,包含两类模型:基础模型 MobileLLM-R1-140M-base、MobileLLM-R1-360M-base、MobileLLM-R1-950M-base 和它们相应的最终模型版。