
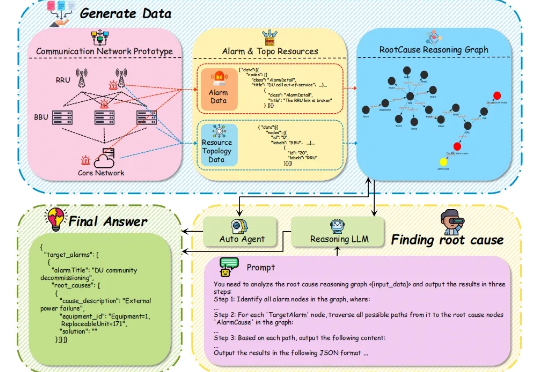
追剧不断网,可能背后有个AI在加班,故障诊断准度破91.79%
追剧不断网,可能背后有个AI在加班,故障诊断准度破91.79%当你的手机突然没信号时,电信工程师在做什么? 想象一下这样的场景:某个周五晚上,你正在用手机追剧,突然网络断了。与此同时,成千上万的用户也遇到了同样的问题。电信运营商的监控中心瞬间被数百个告警信息淹没 —— 基站离线、信号中断、设备故障…
来自主题: AI技术研报
6636 点击 2025-08-16 15:57
当你的手机突然没信号时,电信工程师在做什么? 想象一下这样的场景:某个周五晚上,你正在用手机追剧,突然网络断了。与此同时,成千上万的用户也遇到了同样的问题。电信运营商的监控中心瞬间被数百个告警信息淹没 —— 基站离线、信号中断、设备故障…
一家名为Palabra AI 的初创公司正在开发 AI 语音翻译引擎,致力于解决教学大型语言模型(LLMs)理解多种语言这一颇具挑战性的难题。
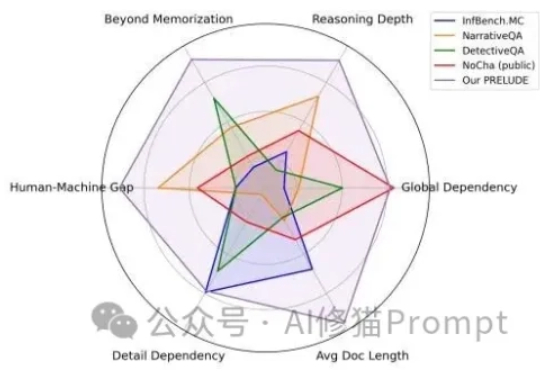
AI领域一度陷入“上下文窗口”的军备竞赛,从几千token扩展到数百万token。这相当于给了AI一个巨大的图书馆。但这些“百万上下文”的顶级模型,它究竟是真的“理解”了,还是只是一个更会“背书”的复读机?
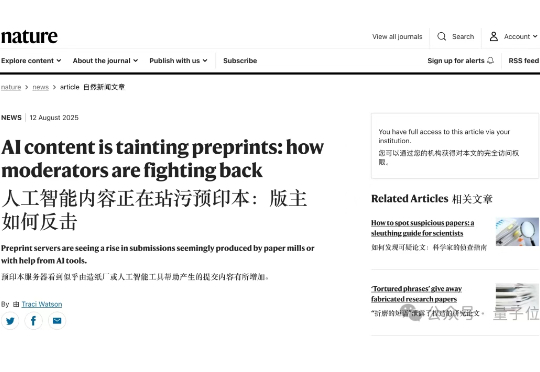
AI生成论文泛滥成灾,arXiv平台看不下去了—— 紧急升级审核机制,用自动化工具来检测AI生成内容。 Nature最新发现,原来每年竟然都有2%的论文会因为AI使用被拒?! 比如像,bioRxiv和medRxiv每天都要拒绝十多篇公式化AI手稿,每个月就高达7000多份。
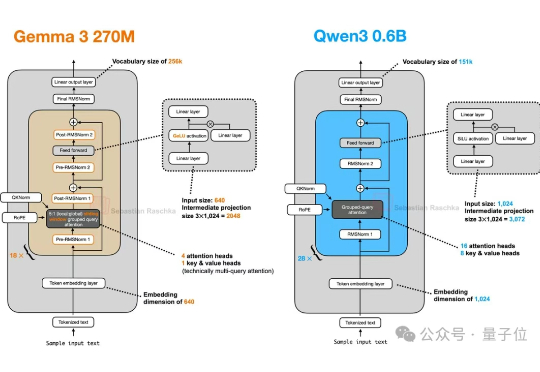
谷歌开源Gemma 3 270M闪亮登场!只需几分钟即可完成微调,指令遵循和文本结构化能力更是惊艳,性能超越Qwen 2.5同级模型。
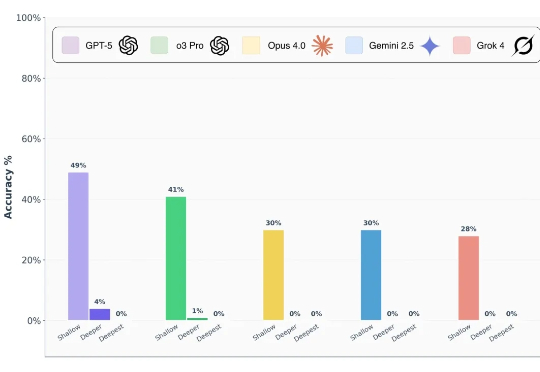
前沿 AI 模型真的能做到博士级推理吗? 前段时间,谷歌、OpenAI 的模型都在数学奥林匹克(IMO)水平测试中达到了金牌水准,这样的表现让人很容易联想到 LLM 是不是已经具备了解决博士级科研难题的推理能力?

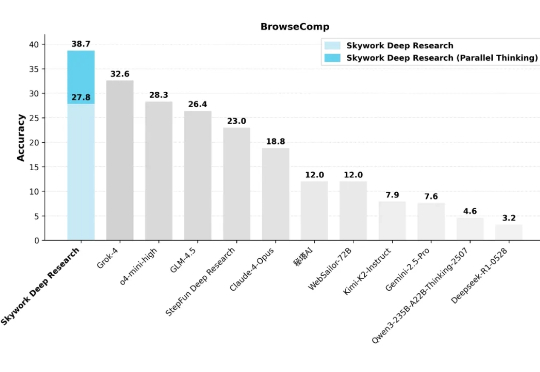
首个开源多模态Deep Research Agent来了。整合了网页浏览、图像搜索、代码解释器、内部 OCR 等多种工具,通过全自动流程生成高质量推理轨迹,并用冷启动微调和强化学习优化决策,使模型在任务中能自主选择合适的工具组合和推理路径。
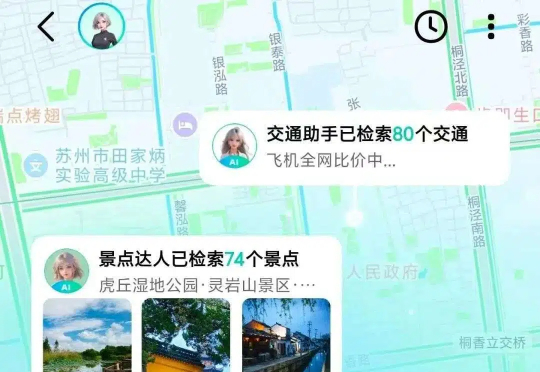
10亿用户App转向AI原生应用,大船如何掉头?高德最近打了个样,用AI重构底层技术栈,建立主-从Agent架构,将千问大模型与空间智能结合,展现出了新范式的强大威力,给用户带去了极大便利。

GPT-5发布以来,路由架构是最受关心的部分之一。它不仅实现了多个模型统一调度,而且还藏着奥特曼的诸多小心思。比如成本更可控、悄悄识别意图插入广告等。
疯狂的七月已经落下了帷幕,如果用一个词来形容国产大模型,「开源」无疑是当之无愧的高频词汇。