

灵宝机器人完成近亿元融资,工厂派投资人盯上「人形机器人」
灵宝机器人完成近亿元融资,工厂派投资人盯上「人形机器人」当 VC 还在计算估值模型时,似乎产线已经给出了更诚实的投票。
来自主题: AI资讯
7891 点击 2025-07-07 14:52
当 VC 还在计算估值模型时,似乎产线已经给出了更诚实的投票。
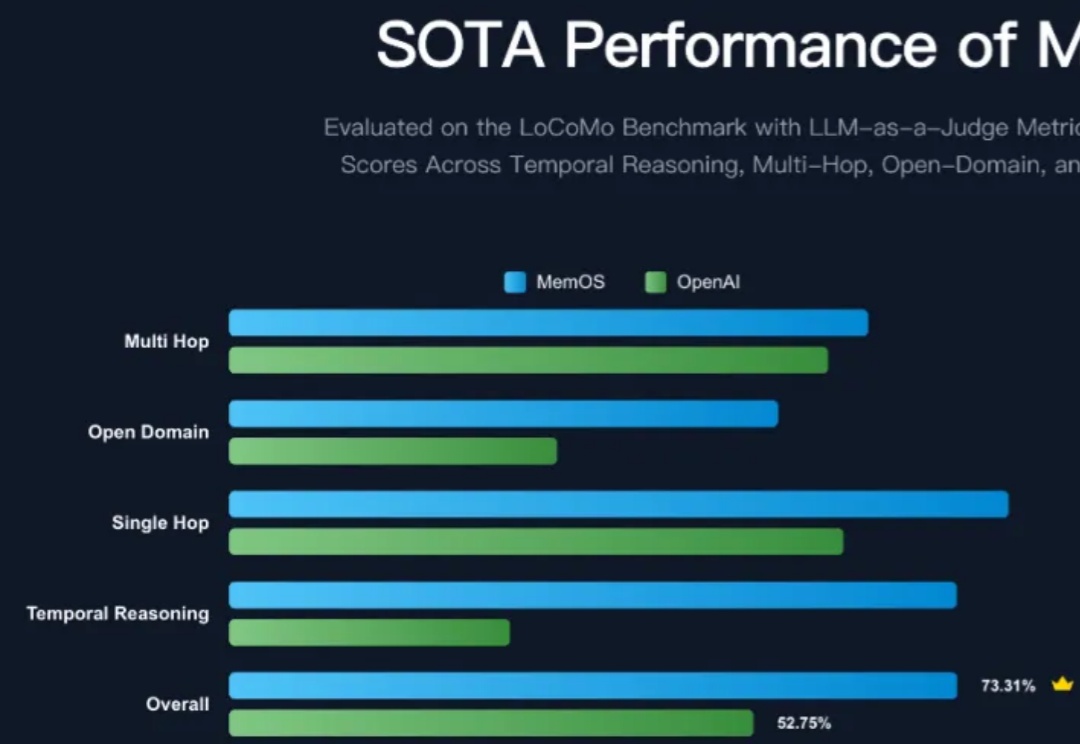
大模型记忆管理和优化框架是当前各大厂商争相优化的热点方向,MemOS 相比现有 OpenAI 的全局记忆在大模型记忆评测集上呈现出显著的提升,平均准确性提升超过 38.97%,Tokens 的开销进一步降低 60.95%,一举登顶记忆管理的 SOTA 框架,特别是在考验框架时序建模与检索能力的时序推理任务上,提升比例更是达到了 159%,相当震撼!
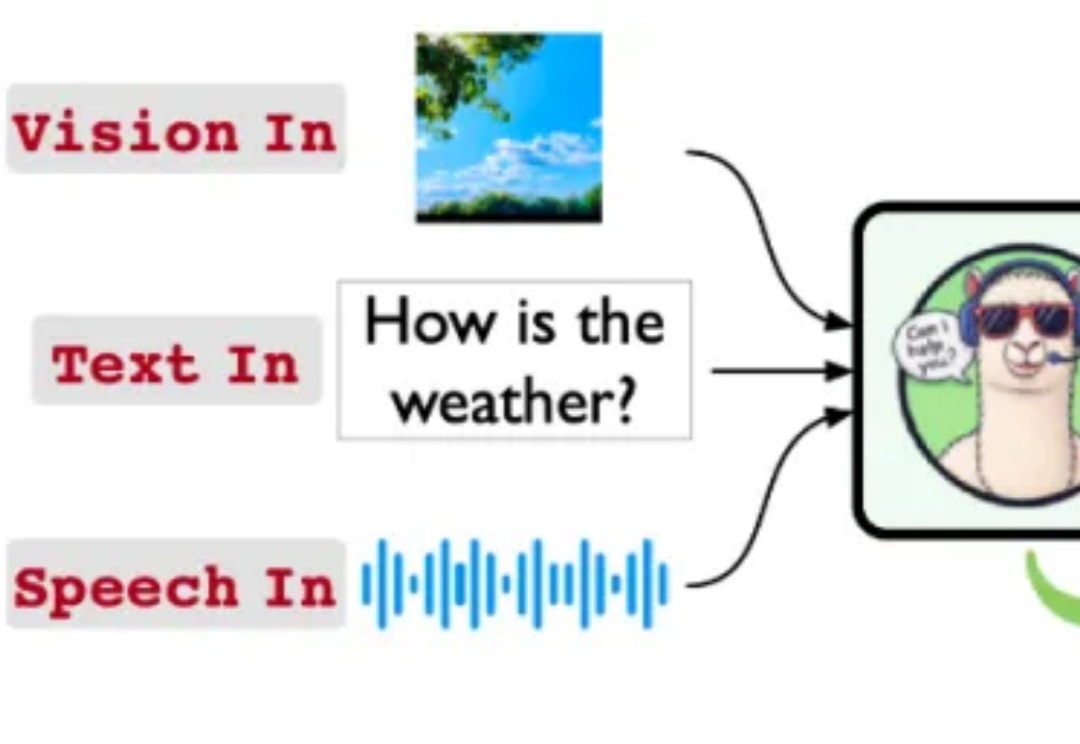
Stream-Omni:同时支持各种模态组合交互的文本-视觉-语音多模态大模型
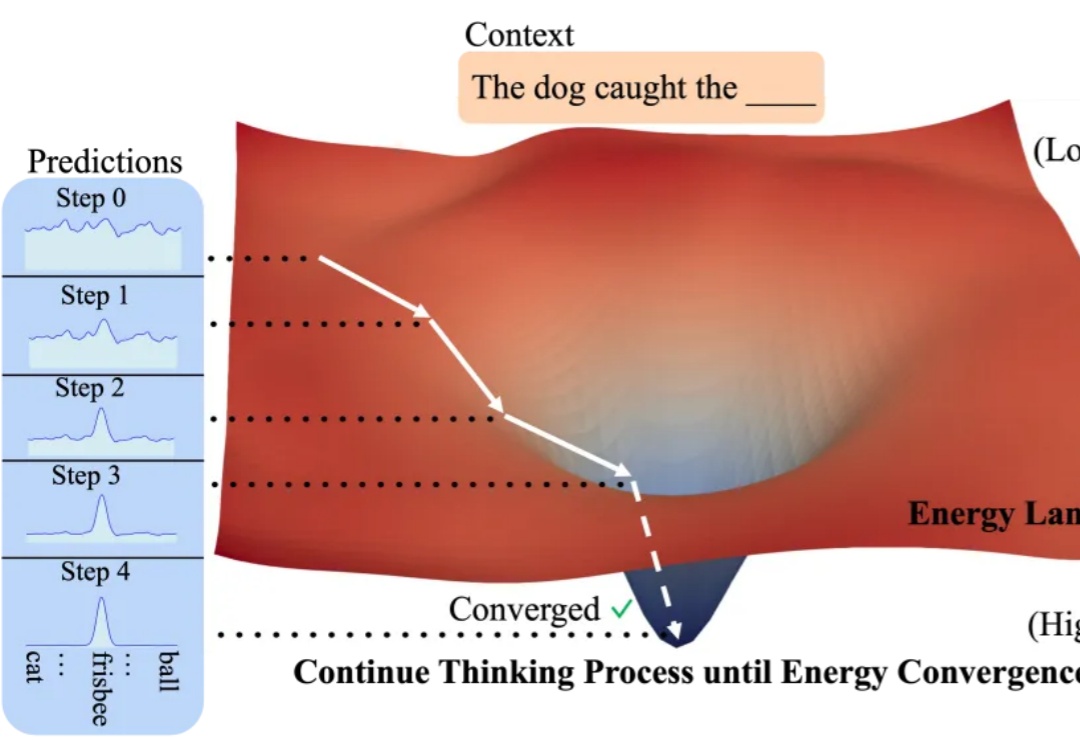
是否可以在不依赖额外监督的前提下,仅通过无监督学习让模型学会思考? 答案有了。
今年以来 Coding 领域的最大变量是 AI labs 们的加入,模型大厂纷纷发力,和创业公司共同竞争这一关键场景:两周前,all-in coding 的 Anthropic 更新了 Artifacts 功能,用户可以在聊天界面里直接生成、预览和编辑代码,实现类 vibe coding 的体验;
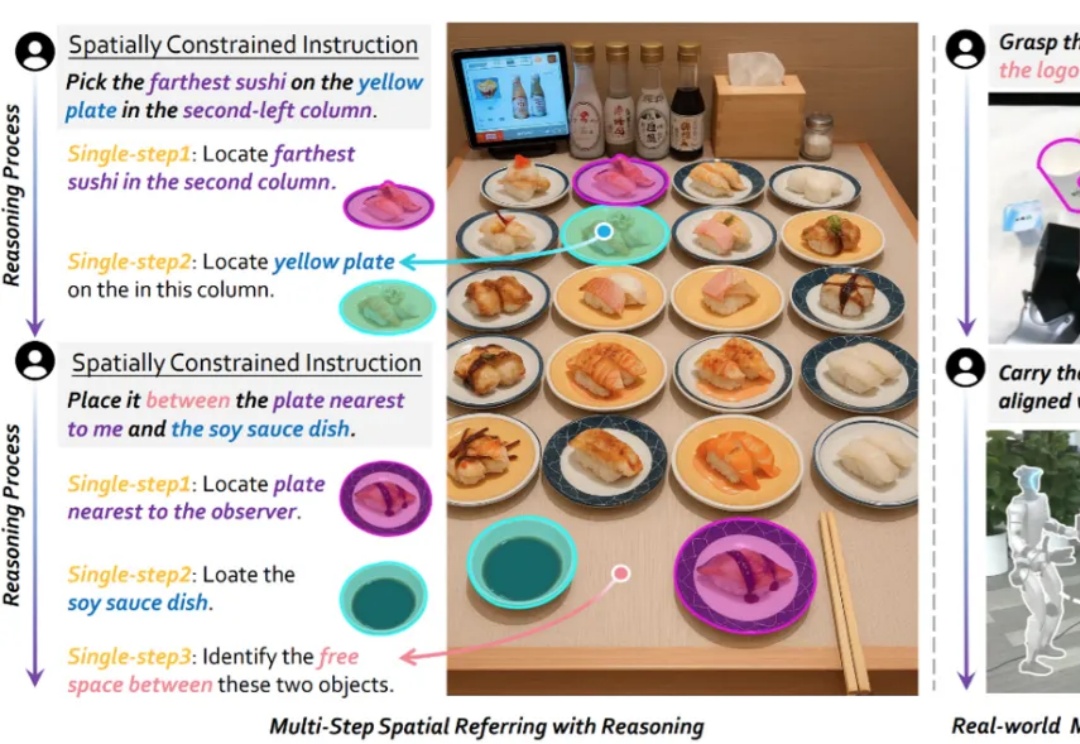
机器人走出实验室、进入真实世界真正可用,远比想象中更复杂。现实环境常常杂乱无序、物体种类繁多、灵活多变,远不像实验室那样干净、单一、可控。

海外和国内AI上差异最大的点可能还不是模型的水平,而是真的没应用。这导致一个很可怕的后果:国内AI整个生态是断链的。
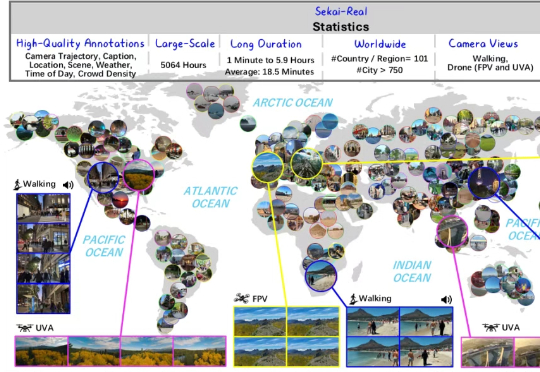
现在,国内研究机构就从数据基石的角度出发,拿出了还原真实动态世界的新进展:上海人工智能实验室、北京理工大学、上海创智学院、东京大学等机构聚焦世界生成的第一步——世界探索,联合推出一个持续迭代的高质量视频数据集项目——Sekai(日语意为“世界”),服务于交互式视频生成、视觉导航、视频理解等任务,旨在利用图像、文本或视频构建一个动态且真实的世界,可供用户不受限制进行交互探索。
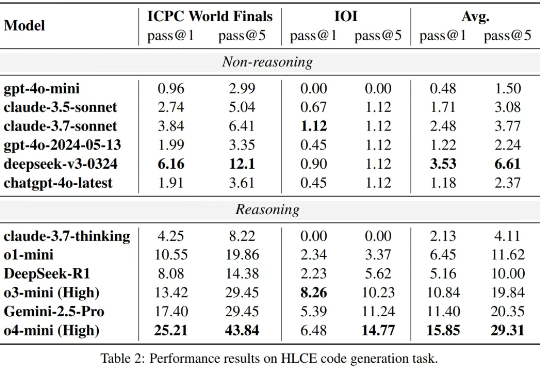
大语言模型(LLM)在标准编程基准测试(如 HumanEval,Livecodebench)上已经接近 “毕业”,但这是否意味着它们已经掌握了人类顶尖水平的复杂推理和编程能力?
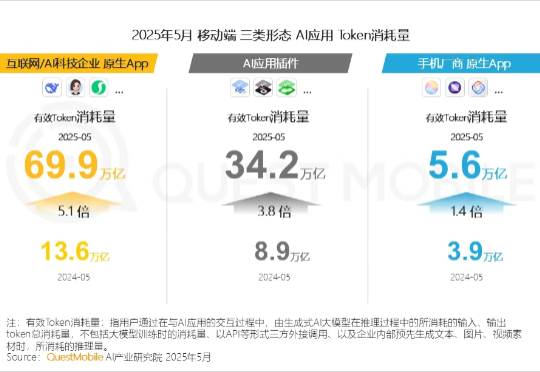
言归正传,今天就给大家分享一下AI应用行业月度报告。QuestMobile数据显示,过去几个月里,在大模型能力没有出现“代际跃迁”的情况下,AI应用持续深入垂直探索