

1000 亿天价,扎克伯格买下「半个天才」和 Meta AI 的未来
1000 亿天价,扎克伯格买下「半个天才」和 Meta AI 的未来不仅是大模型本身,Meta 也要成为 AI 基建大厂。
来自主题: AI资讯
6011 点击 2025-06-11 11:42
不仅是大模型本身,Meta 也要成为 AI 基建大厂。

为什么语言模型能从预测下一个词中学到很多,而视频模型却从预测下一帧中学到很少?
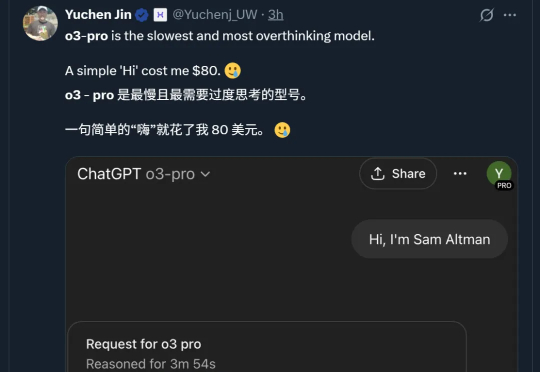
OpenAI深夜放大招,正式推出“最新最强版”推理模型o3-pro! 而且同一时间,o3模型降价80%不降智。官方测评结果显示,在专家评估中,所有人一致更偏爱o3-pro而非o3的回答。

今年苹果在 AI 上宣布的诸多所谓新功能,例如实时翻译、快捷指令等,并无太多革命性;至于视觉智能 (visual intelligence),不仅功能落后 Google Lens 六七年,交互体验上也远未达到一众 Android 友商的内置 AI/Agent 产品在 2025 上半年水平。

大模型的落地能力,核心在于性能的稳定输出,而性能稳定的底层支撑,是强大的算力集群。其中,构建万卡级算力集群,已成为全球公认的顶尖技术挑战。

游戏直播等实时渲染门槛要被击穿了?Adobe 的一项新研究带来新的可能。

为什么语言模型很成功,视频模型还是那么弱?

给大模型当老师,让它一步步按你的想法做数据分析,有多难?

测试时扩展(Test-Time Scaling)极大提升了大语言模型的性能,涌现出了如 OpenAI o 系列模型和 DeepSeek R1 等众多爆款。那么,什么是视觉领域的 test-time scaling?又该如何定义?
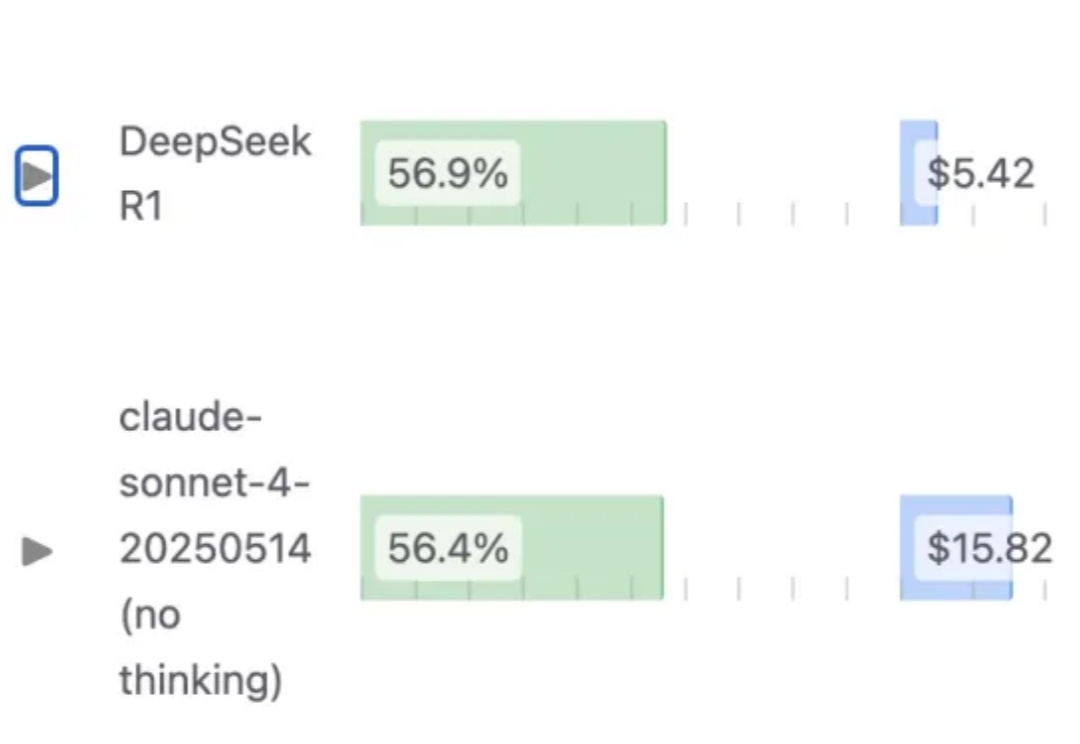
1.93bit量化之后的 DeepSeek-R1(0528),编程能力依然能超过Claude 4 Sonnet?