
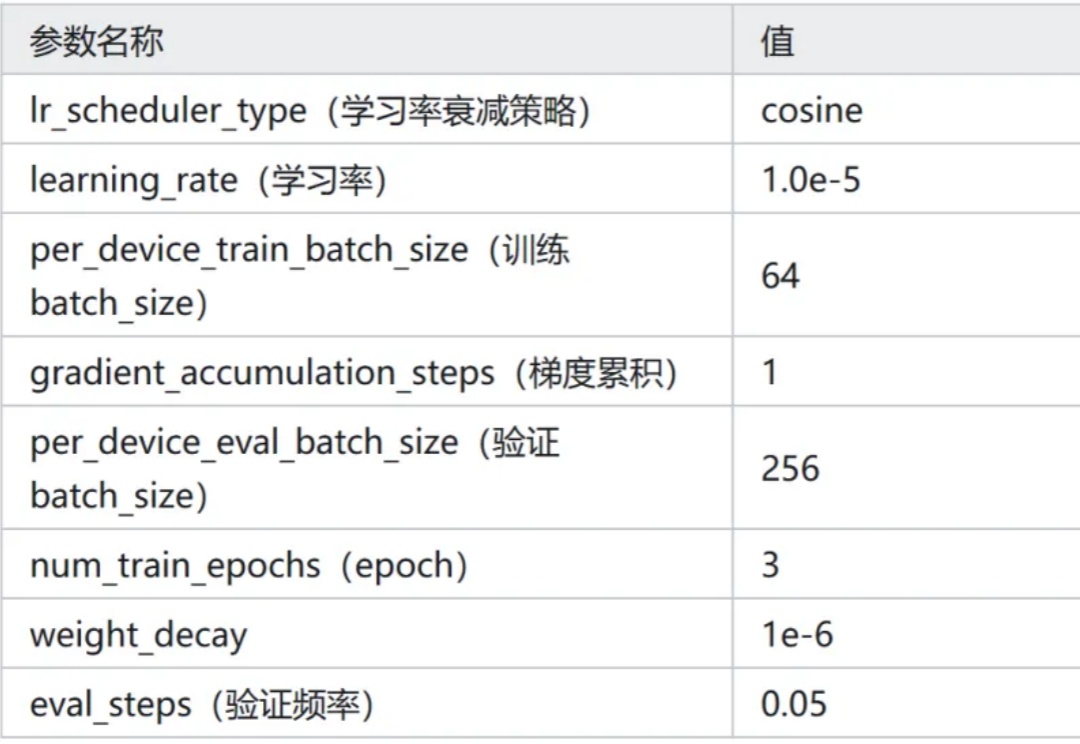
Qwen3-0.6B 能击败 Bert 吗?
Qwen3-0.6B 能击败 Bert 吗?新增 Qwen3-0.6B 在 Ag_news 数据集 Zero-Shot 的效果。新增 Qwen3-0.6B 线性层分类方法的效果。
来自主题: AI技术研报
10372 点击 2025-05-26 10:14
新增 Qwen3-0.6B 在 Ag_news 数据集 Zero-Shot 的效果。新增 Qwen3-0.6B 线性层分类方法的效果。
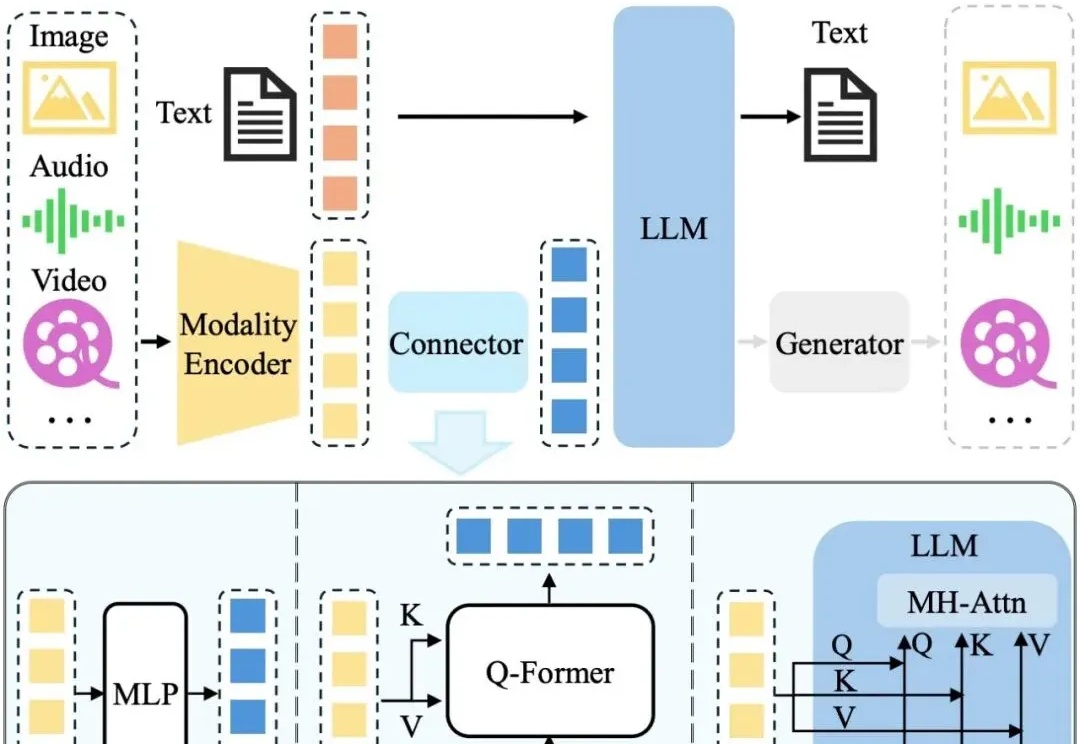
近年来,LLM 及其多模态扩展(MLLM)在多种任务上的推理能力不断提升。然而, 现有 MLLM 主要依赖文本作为表达和构建推理过程的媒介,即便是在处理视觉信息时也是如此 。

1986年,图灵奖得主Fred Brooks在软件工程领域提出了著名的"没有银弹"理论:没有任何一种技术或方法能够独自带来软件工程生产力的数量级提升。近四十年后,这个深刻洞察在AI领域再次得到验证——你是否也曾经历过这样的挫折:

想象一下,你是一位金融分析师,面前堆满了数百页的季报、SEC文件和市场数据,你需要在明天早上交出一份全面的行业分析报告。
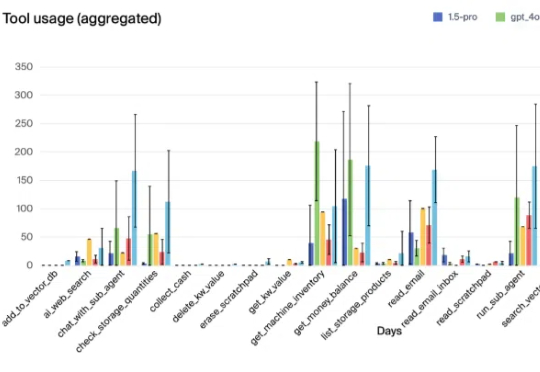
Vending-Bench模拟环境可以测试大模型管理自动售货机的能力,结果显示,Claude 3.5 Sonnet表现最佳,人类屈居第四!
围棋因其独特的复杂性和对人类智能的深刻体现,可作为衡量AI专业能力最具代表性的任务之一。
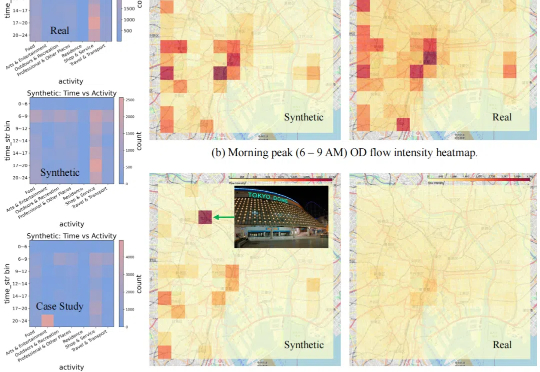
现有的数据合成方法在合理性和分布一致性方面存在不足,且缺乏自动适配不同数据的能力,扩展性较差。
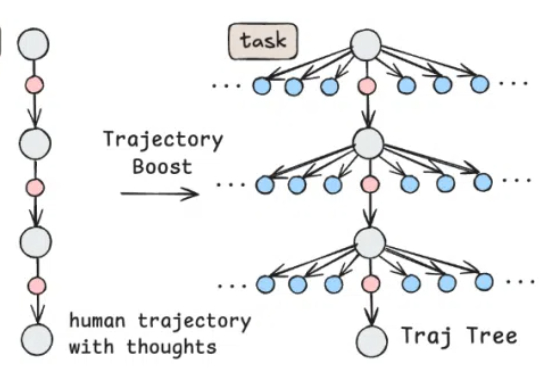
自 Anthropic 推出 Claude Computer Use,打响电脑智能体(Computer Use Agent)的第一枪后,OpenAI 也相继推出 Operator,用强化学习(RL)算法把电脑智能体的能力推向新高,引发全球范围广泛关注。

而马毅是那类觉得不够的人,他于无声处开始提问:智能的本质是什么?自 2000 年从伯克利大学博士毕业以来,马毅先后任职于伊利诺伊大学香槟分校(UIUC)、微软亚研院、上海科技大学、伯克利大学和香港大学,现担任香港大学计算与数据科学学院院长。他和团队提出的压缩感知技术,到现在还在影响计算机视觉中模式识别领域的发展。

在文档理解领域,多模态大模型(MLLMs)正以惊人的速度进化。从基础文档图像识别到复杂文档理解,它们在扫描或数字文档基准测试(如 DocVQA、ChartQA)中表现出色,这似乎表明 MLLMs 已很好地解决了文档理解问题。然而,现有的文档理解基准存在两大核心缺陷: