大模型掌握人类空间思考能力!三阶段训练框架学会“边画边想”,5个基准平均提升18.4%
大模型掌握人类空间思考能力!三阶段训练框架学会“边画边想”,5个基准平均提升18.4%“边看边画,边画边想”,让大模型掌握空间思考能力,结果直接实现空间推理任务新SOTA。
来自主题: AI技术研报
8000 点击 2025-06-21 16:48
 搜索
搜索
“边看边画,边画边想”,让大模型掌握空间思考能力,结果直接实现空间推理任务新SOTA。

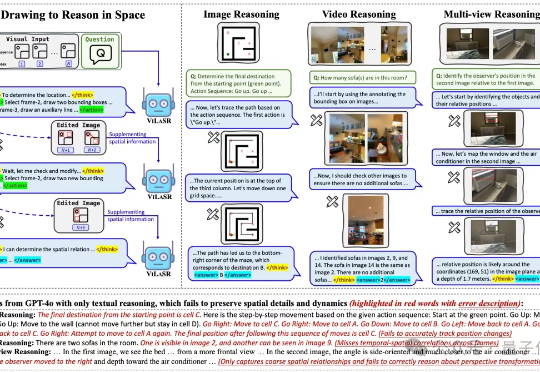
自年初起,DeepSeek-R1、OpenAI o3、Qwen3等推理模型相继问世,展现出令人惊叹的智能水平,但它们为什么突然变得这么聪明?东京大学联合Google DeepMind的研究者们终于找到了答案。
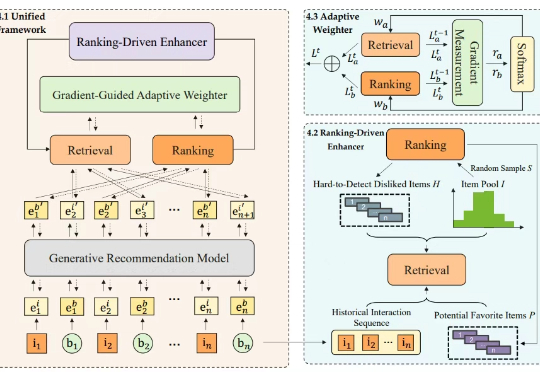
在信息爆炸的时代,推荐系统已成为我们获取资讯、商品和服务的核心入口。无论是电商平台的 “猜你喜欢”,还是内容应用的信息流,背后都离不开推荐算法的默默耕耘

华为正将「根深」的自研能力,转化为赋能千行万业智能化升级的「叶茂」。

凌晨三点,京东依然有不少直播间非常热闹。在一家珠宝饰品直播间里,一位身穿白色西装的主播正在讲解手链饰品。

生成图像这件事,会推理的AI才是好AI。 举个例子,以往要是给AI一句这样的Prompt: (3+6)条命的动物。 我们人类肯定一眼就知道是猫咪,但AI的思考过程却是这样的:
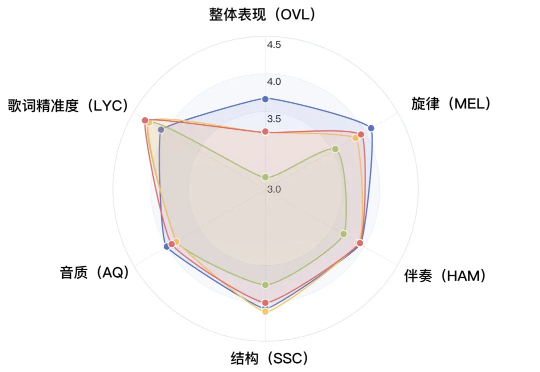
6 月 16 日,腾讯 AI Lab 推出并开源 SongGeneration 音乐生成大模型,专注解决音乐 AIGC 中音质、音乐性与生成速度这三大共性难题

预训练模型能否作为探索新架构设计的“底座” ? 最新答案是:yes!
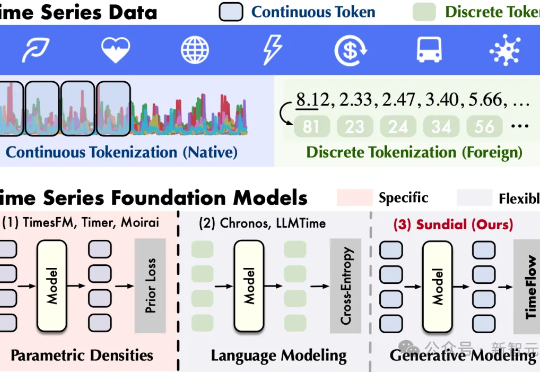
清华大学软件学院发布生成式时序大模型——日晷(Sundial)。告别离散化局限,无损处理连续值,基于流匹配生成预测,缓解预训练模式坍塌,支持非确定性概率预测,为决策过程提供动态支持。
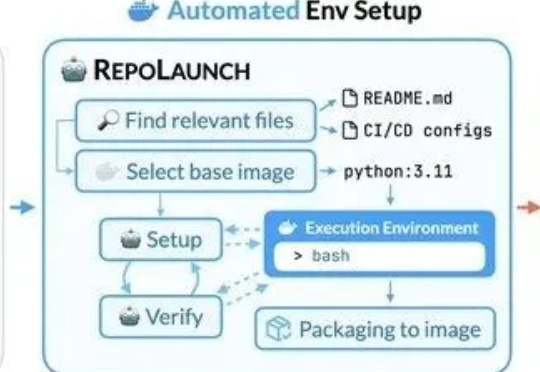
长期以来主流的代码修复评测基准SWE-bench面临数据过时、覆盖面窄、手动维护成本高等问题,严重制约了AI模型真实能力的展现。