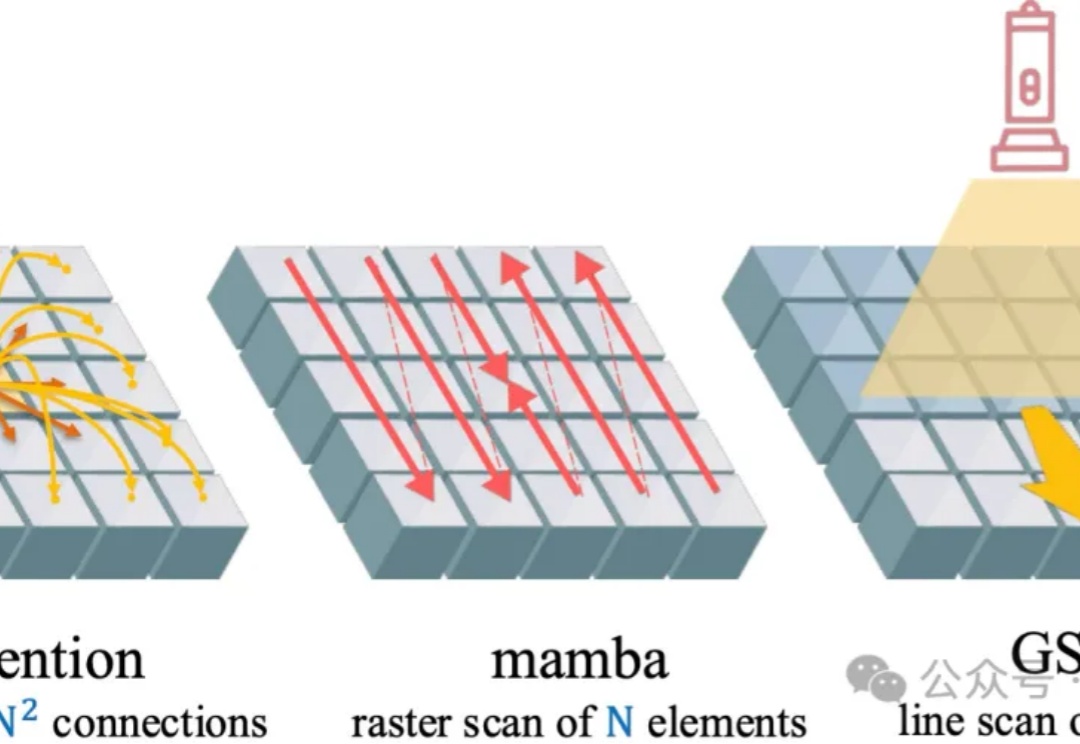
英伟达港大联手革新视觉注意力机制!GSPN高分辨率生成加速超84倍
英伟达港大联手革新视觉注意力机制!GSPN高分辨率生成加速超84倍视觉注意力机制,又有新突破,来自香港大学和英伟达。
来自主题: AI技术研报
9407 点击 2025-06-11 14:34
 搜索
搜索
视觉注意力机制,又有新突破,来自香港大学和英伟达。
第一作者陈昌和是美国密歇根大学的研究生,师从 Nima Fazeli 教授,研究方向包括基础模型、机器人学习与具身人工智能,专注于机器人操控、物理交互与控制优化。

近年来,大语言模型(LLM)以其卓越的文本生成和逻辑推理能力,深刻改变了我们与技术的互动方式。然而,这些令人瞩目的表现背后,LLM的内部机制却像一个神秘的“黑箱”,让人难以捉摸其决策过程。
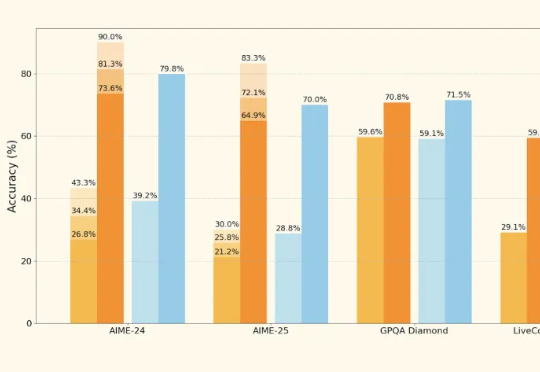
“欧洲的OpenAI”Mistral AI终于发布了首款推理模型——Magistral。 然而再一次遭到网友质疑:怎么又不跟最新版Qwen和DeepSeek R1 0528对比?
最强推理模型一夜易主!深夜,o3-pro毫无预警上线,刷爆数学、编程、科学基准,强势碾压o1-pro和o3。更惊艳的是,o3价格直接暴降80%,叫板Gemini 2.5 Pro。

在当今AI行业,技术的迭代速度与应用的广泛程度正在以前所未有的方式深刻改变着我们的生活。从早期的基础算法研究到如今的智能硬件应用,AI的革命已悄然展开,然而,尽管AI潜力巨大,其高昂的能耗、庞大的模型和复杂的学习机制仍是行业亟待突破的难题。在这种背景下,致力于突破AI效率瓶颈的创新型公司正引领着一股变革潮流。

SemiAnalysis全新硬核爆料,意外揭秘了OpenAI全新模型的秘密?据悉,新模型介于GPT-4.1和GPT-4.5之间,而下一代推理模型o4将基于GPT-4.1训练,而背后最大功臣,就是强化学习。
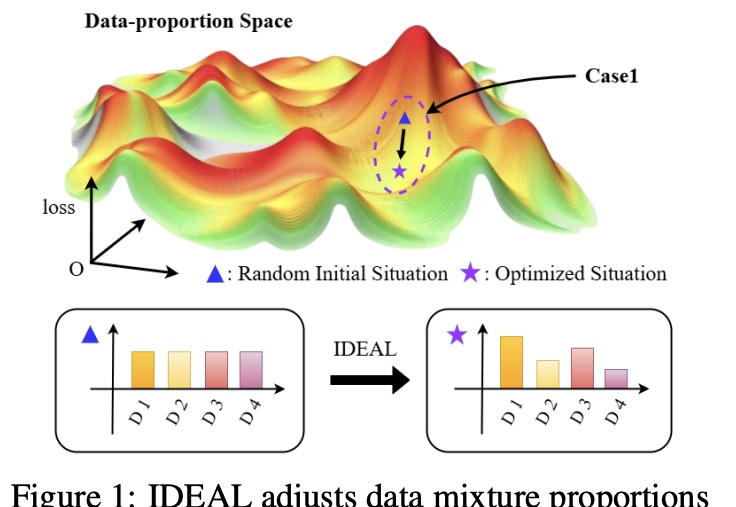
大幅缓解LLM偏科,只需调整SFT训练集的组成。

20人国内团队,竟然提前2年预判到了DeepSeek的构想?玉盘AI的全新计算架构方案浮出水面后,直接震动业内:当前AI算力的核心瓶颈,他们试图从硬件源头解决!

现在市面上有46种Prompt工程技术,但真正能在软件工程任务中发挥作用的,可能只有那么几种。来自巴西联邦大学、加州大学尔湾分校等顶级院校的研究者们,花了大量时间和计算资源,调研了58种,整理了46种,最终筛选测试了14种主流提示技术在10个软件工程任务上的表现,用了4个不同的大模型(包括咱们的Deepseek-V3),总共跑了2000多次实验。