1.93bit版DeepSeek-R1编程超过Claude 4 Sonnet,不用GPU也能运行
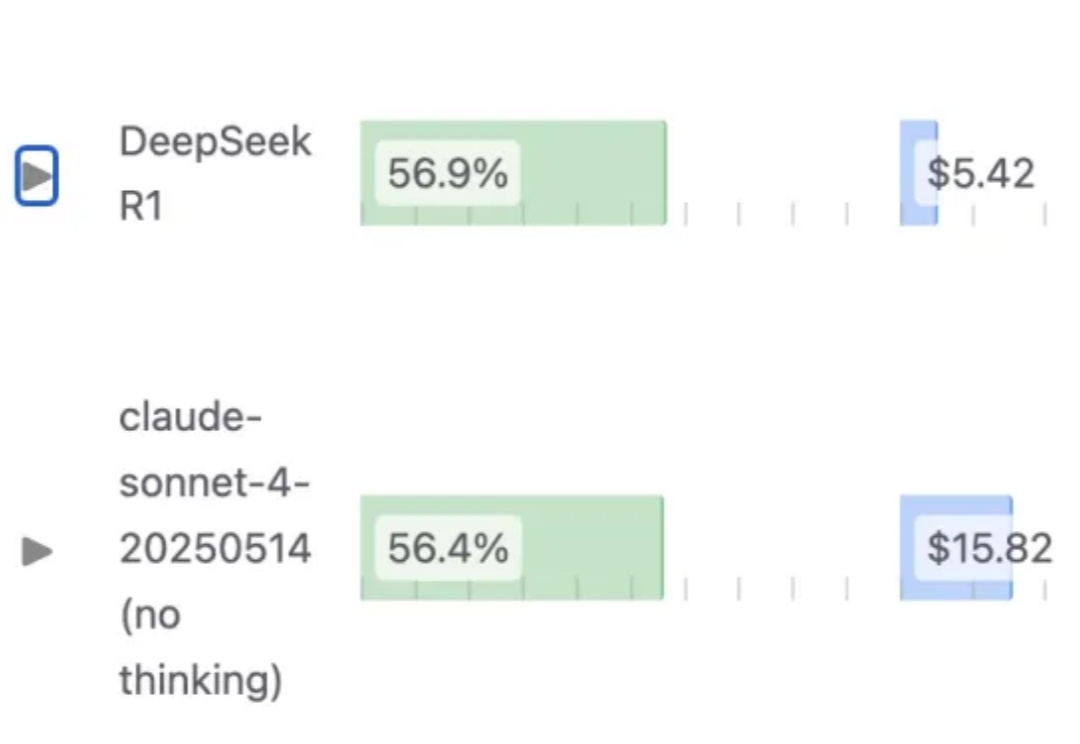
1.93bit版DeepSeek-R1编程超过Claude 4 Sonnet,不用GPU也能运行1.93bit量化之后的 DeepSeek-R1(0528),编程能力依然能超过Claude 4 Sonnet?
来自主题: AI技术研报
7907 点击 2025-06-10 15:28
 搜索
搜索
1.93bit量化之后的 DeepSeek-R1(0528),编程能力依然能超过Claude 4 Sonnet?

传统的视频编辑工作流,正在被AI彻底重塑。

大模型目前的主导地位只是暂时的,在未来五年甚至十年内都不会是技术前沿。 这是新晋图灵奖得主、强化学习之父Richard Sutton对未来的最新预测。
王劲,香港大学计算机系二年级博士生,导师为罗平老师。研究兴趣包括多模态大模型训练与评测、伪造检测等,有多项工作发表于 ICML、CVPR、ICCV、ECCV 等国际学术会议。
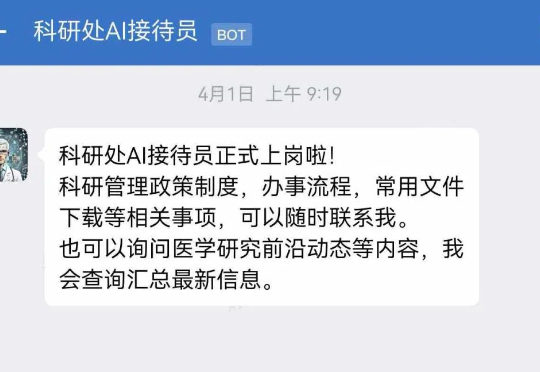
AI大模型正在医疗服务行业中扎根。 “我们医院在科研平台上已经接入使用了DeepSeek。”北京某三甲医院相关负责人对光锥智能说道,“形式类似于AI助理,能提供科研政策问答、查询、常用文件下载等功能。”
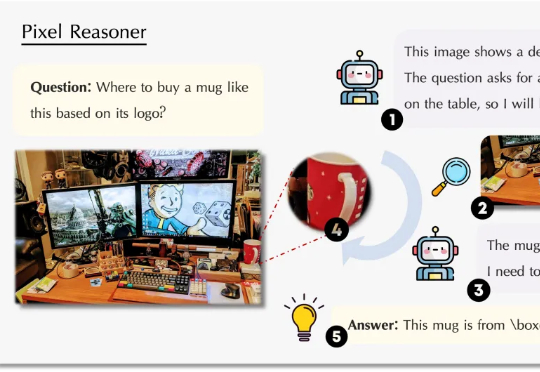
视觉语言模型(VLM)正经历从「感知」到「认知」的关键跃迁。 当OpenAI的o3系列通过「图像思维」(Thinking with Images)让模型学会缩放、标记视觉区域时,我们看到了多模态交互的全新可能。

今年的苹果,到底有没有新活?

因为眼睛受伤暂时失去立体视觉,李飞飞更加坚定了做世界模型的决心。
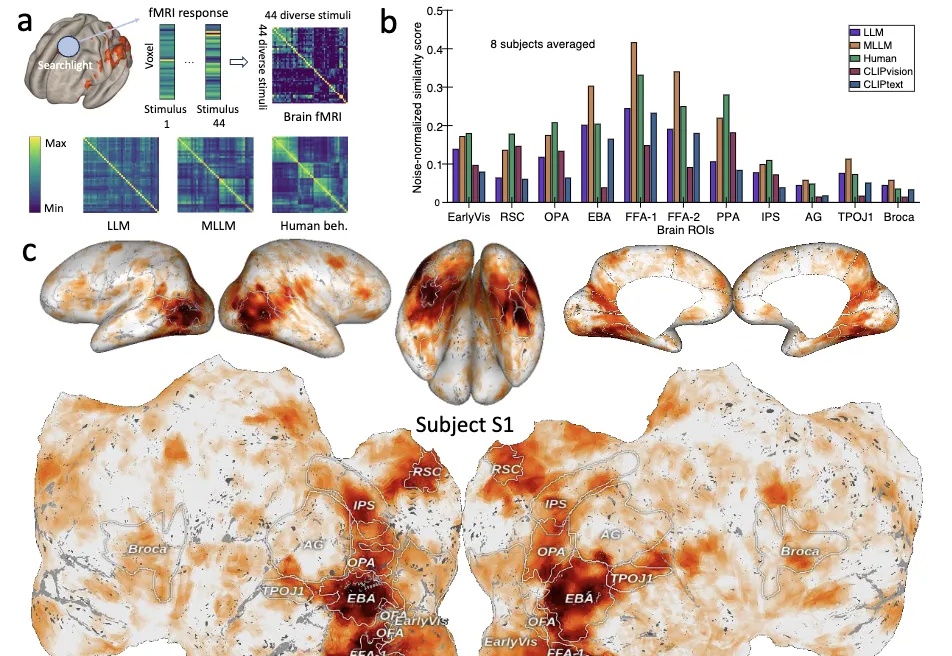
大模型≠随机鹦鹉!Nature子刊最新研究证明: 大模型内部存在着类似人类对现实世界概念的理解。

知识库成为大模型落地的热门场景,现实中却走入了 “技术炫酷却用不起来” 的窘境。