
OpenAI久违发了篇「正经」论文:线性布局实现高效张量计算
OpenAI久违发了篇「正经」论文:线性布局实现高效张量计算OpenAI 发论文的频率是越来越低了,如果你看到了一份来自 OpenAI 的新 PDF 文件,那多半也是新模型的系统卡或相关增补文件或基准测试,很少有新的研究论文。
来自主题: AI资讯
8658 点击 2025-06-05 14:33
 搜索
搜索
OpenAI 发论文的频率是越来越低了,如果你看到了一份来自 OpenAI 的新 PDF 文件,那多半也是新模型的系统卡或相关增补文件或基准测试,很少有新的研究论文。
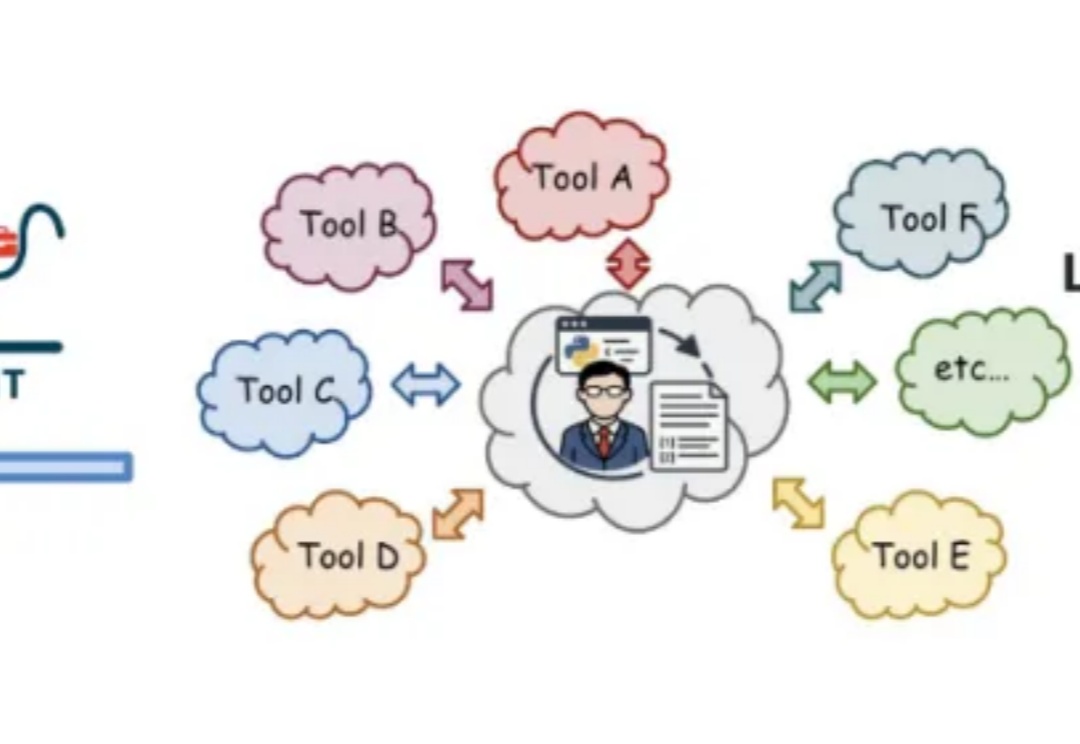
智能体技术日益发展,但现有的许多通用智能体仍然高度依赖于人工预定义好的工具库和工作流,这极大限制了其创造力、可扩展性与泛化能力。

无监督的熵最小化(EM)方法仅需一条未标注数据和约10步优化,就能显著提升大模型在推理任务上的表现,甚至超越依赖大量数据和复杂奖励机制的强化学习(RL)。EM通过优化模型的预测分布,增强其对正确答案的置信度,为大模型后训练提供了一种更高效简洁的新思路。
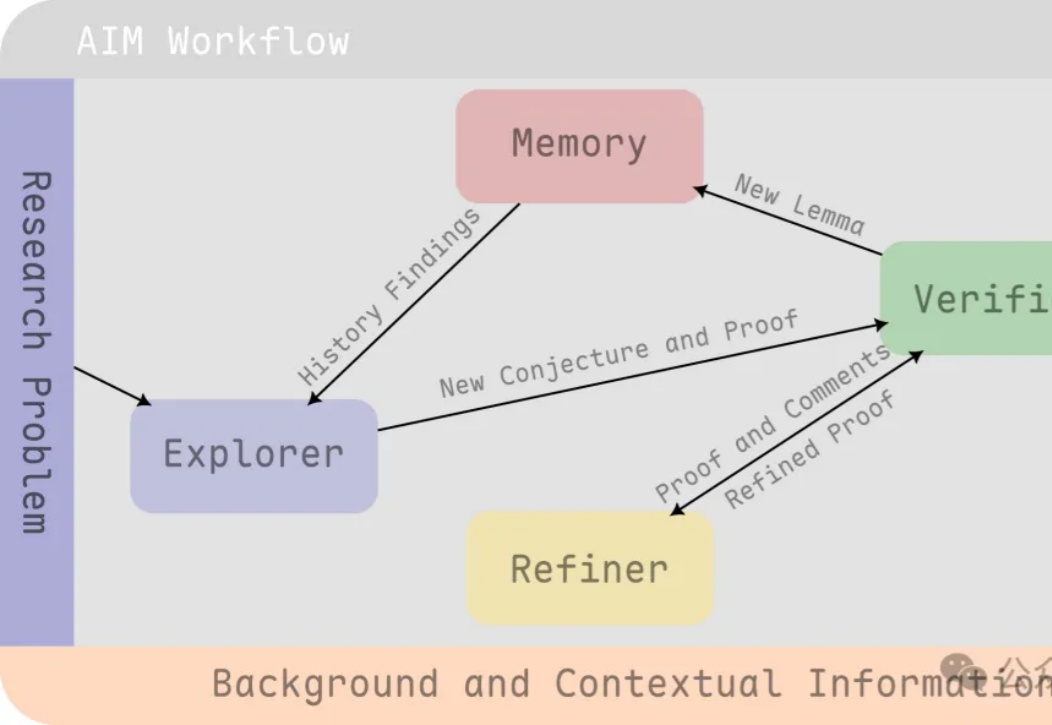
AI数学家来了!清华团队出品—— 他们推出AI Mathematician(AIM)框架,推理模型也能求解前沿理论研究,并且证明完成度很高。
如果你正在开发Agent产品,一定听过或用过Mixture-of-Agents(MoA)架构。这个让多个AI模型协作解决复杂问题的框架,理论上能够集众家之长,实际使用中却让人又爱又恨:
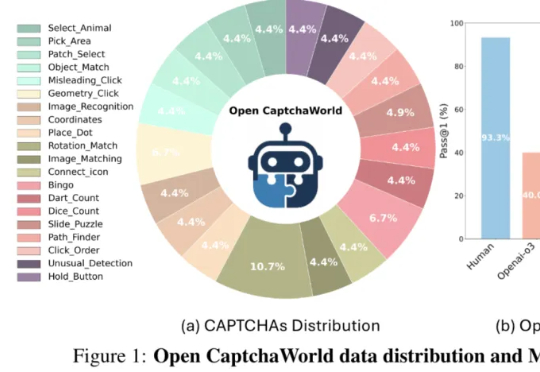
当前最强多模态Agent连验证码都解不了?
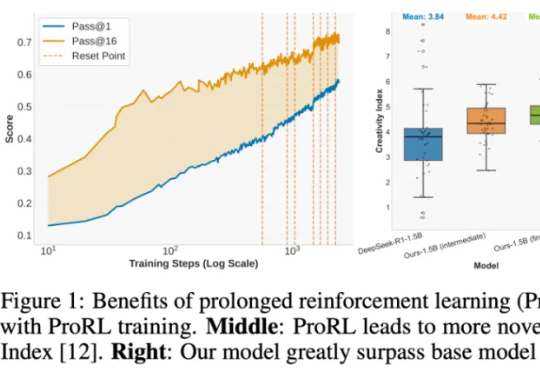
强化学习(RL)到底是语言模型能力进化的「发动机」,还是只是更努力地背题、换个方式答题?这个问题,学界争论已久:RL 真能让模型学会新的推理技能吗,还是只是提高了已有知识的调用效率?

斯坦福华人数学博士AI创业,0产品0用户,目标估值3亿美元方向瞄准数学AI,要为量化和对冲基金公司提供可解决实际数学问题的模型能力
当地时间 6 月 4 日,Windsurf CEO Varun Mohan 发帖称,在提前不到五天的通知时间里,Anthropic 切断了其几乎所有 Claude 3.x 模型的直接访问权限(first-party capacity),包括 Claude 3.5 Sonnet、3.7 Sonnet 和 3.7 Sonnet Thinking。

如今的新浪,已经被DeepSeek全面重塑了!新浪新闻推出AI辅助工具「智慧小浪」帮我们看新闻,更高效、更深度。同时,微博的「评论罗伯特」的人味也是噌噌up,爆梗频出、妙语连珠。