
一张图,快速生成可拆分3D角色!腾讯清华新SOTA | CVPR 2025
一张图,快速生成可拆分3D角色!腾讯清华新SOTA | CVPR 2025任意一张立绘,就可以生成可拆分3D角色!
来自主题: AI技术研报
7833 点击 2025-03-21 10:13
 搜索
搜索
任意一张立绘,就可以生成可拆分3D角色!

就在刚刚,OpenAI 宣布在其 API 中推出全新一代音频模型,包括语音转文本和文本转语音功能,让开发者能够轻松构建强大的语音 Agent。据 OpenAI 介绍,新推出的 gpt-4o-transcribe 采用多样化、高质量音频数据集进行了长时间的训练,能更好地捕获语音细微差别,减少误识别,大幅提升转录可靠性。
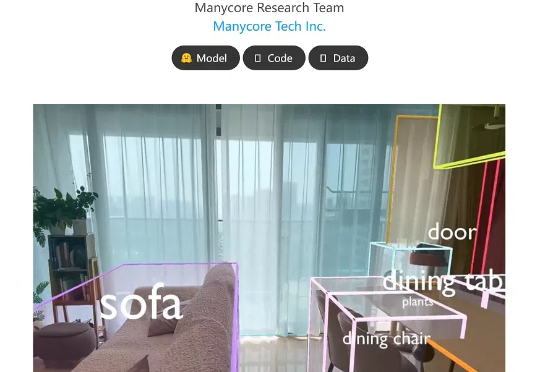
前脚被谷歌点名感谢空间训练平台,后脚又开源了空间模型!杭州六小龙群核科技发了一个空间理解开源模型SpatialLM,让机器人刷一段视频,就能理解物理世界的几何关系。结合之前发布的空间智能训练平台SpatialVerse,群核科技要为机器人提供从空间认知到行动交互的训练闭环。机器人也被「卷」到要上学了。
3D打印的世界在不断变化,人工智能(AI)的发展发挥着越来越重要的作用。特别是,通过人工智能生成3D模型开辟了新的可能性和潜力。在本文中,将介绍22种创新服务,它们在这一领域发挥着开创性的作用。
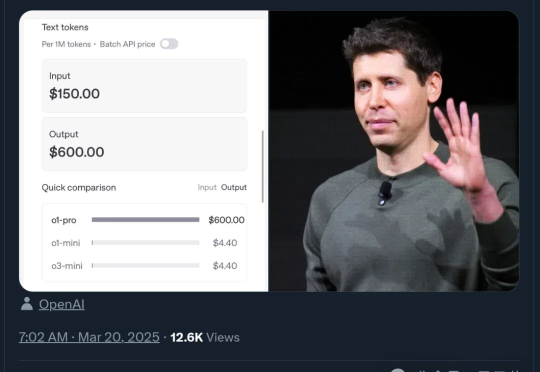
比DeepSeek-R1贵270倍,OpenAI史上最贵模型来了!
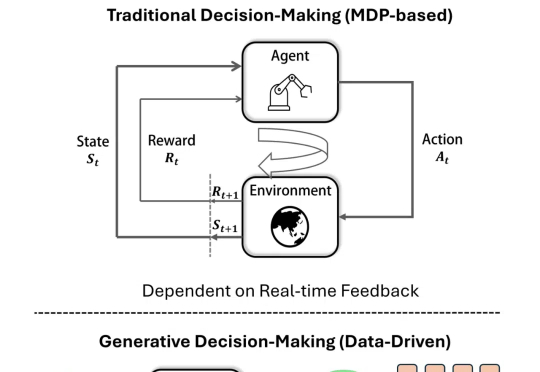
近年来,生成模型在内容生成(AIGC)领域蓬勃发展,同时也逐渐引起了在智能决策中的应用关注。
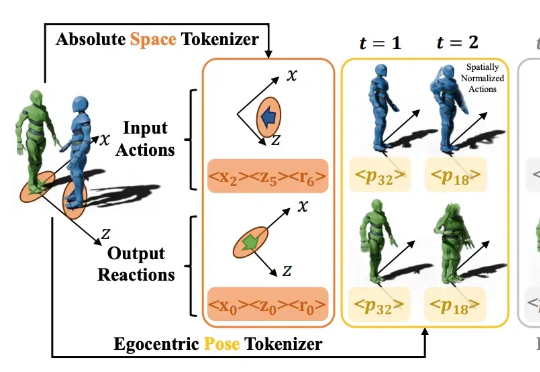
对面有个人向你缓缓抬起手,你会怎么回应呢?握手,还是挥手致意?

DeepSeek 掀翻了国内大模型领域原本搭好的台,各个大厂都在重新找位置,腾讯选择了通过一系列「闪电战」式的部署,展示战略决心。

EgoNormia基准可以评估视觉语言模型在物理社会规范理解方面能力,从结果上看,当前最先进的模型在规范推理方面仍远不如人类,主要问题在于规范合理性和优先级判断上的不足。
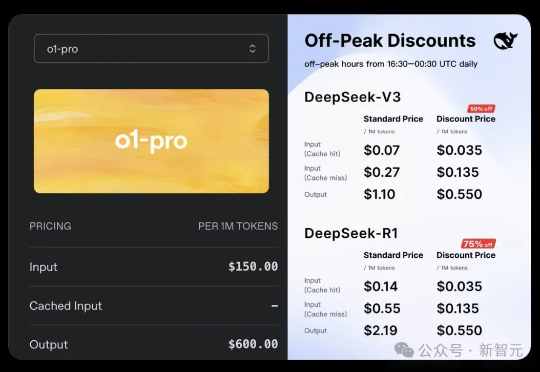
刚刚,OpenAI正式上线史上最贵API——o1-pro,输入/输出价格贵到离谱,最高可达DeepSeek-R1的千倍。OpenAI研究员戏称,大模型界的劳斯莱斯。