线性扩散模型LiT来了,用极简线性注意力助力扩散模型AIPC时代端侧部署
线性扩散模型LiT来了,用极简线性注意力助力扩散模型AIPC时代端侧部署香港大学联合上海人工智能实验室,华为诺亚方舟实验室提出高效扩散模型 LiT:探索了扩散模型中极简线性注意力的架构设计和训练策略。LiT-0.6B 可以在断网状态,离线部署在 Windows 笔记本电脑上,遵循用户指令快速生成 1K 分辨率逼真图片。
来自主题: AI技术研报
8537 点击 2025-02-01 18:37
 搜索
搜索
香港大学联合上海人工智能实验室,华为诺亚方舟实验室提出高效扩散模型 LiT:探索了扩散模型中极简线性注意力的架构设计和训练策略。LiT-0.6B 可以在断网状态,离线部署在 Windows 笔记本电脑上,遵循用户指令快速生成 1K 分辨率逼真图片。

27 页综述,354 篇参考文献!史上最详尽的视觉定位综述,内容覆盖过去十年的视觉定位发展总结,尤其对最近 5 年的视觉定位论文系统性回顾,内容既涵盖传统基于检测器的视觉定位,基于 VLP 的视觉定位,基于 MLLM 的视觉定位,也涵盖从全监督、无监督、弱监督、半监督、零样本、广义定位等新型设置下的视觉定位。

外媒SemiAnalysis的一篇深度长文,全面分析了DeepSeek背后的秘密——不是「副业」项目、实际投入的训练成本远超600万美金、150多位高校人才千万年薪,攻克MLA直接让推理成本暴降......
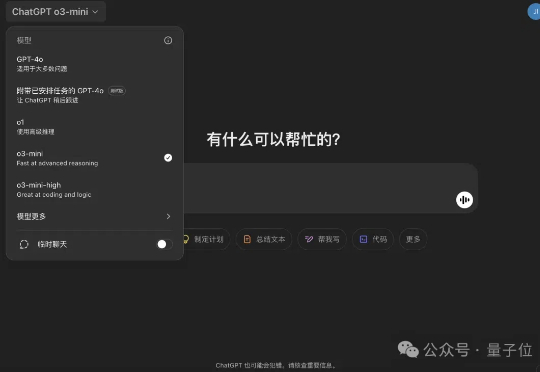
就在刚刚,OpenAI深夜紧急发布了最新推理模型,o3-mini系列。一共包含三个版本:low、medium和high。其中o3-mini和o3-mini-high已经上线:
现在,豆包大模型团队联合北京交通大学、中国科学技术大学提出了VideoWorld。

当谷歌在 2018 年推出 BERT 模型时,恐怕没有料到这个 3.4 亿参数的模型会成为自然语言处理领域的奠基之作。
1月13日Mainframe公司发布了可以离线运行在苹果系统(Mac,iPad,iPhone)的本地大语言模型fullmoon: local intelligence

首个FP4精度的大模型训练框架来了,来自微软研究院!

2025 年伊始,全球 AI 业界被 DeepSeek 刷屏。当 OpenAI 宣布 5000 亿美元的「星际之门」计划,Meta 在建规模超 130 万 GPU 的数据中心时,这个来自中国的团队打破了大模型军备竞赛的既定逻辑:用 2048 张 H800 GPU,两个月训练出了一个媲美全球顶尖水平的模型。
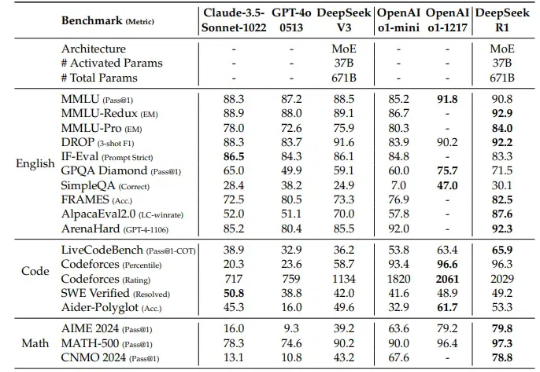
"Deepseek R1不就是一个参数更大的语言模型吗?随便问问题就行了,还需要什么特殊技巧?"——当你说出这句话时,是否意识到自己正像《西游记》里高举紫金葫芦的妖怪,对着齐天大圣叫嚣:"我叫你的名字,你敢答应吗?"