UniReal登场:用视频架构统一图像生成与编辑,还学到真实世界动态变化规律
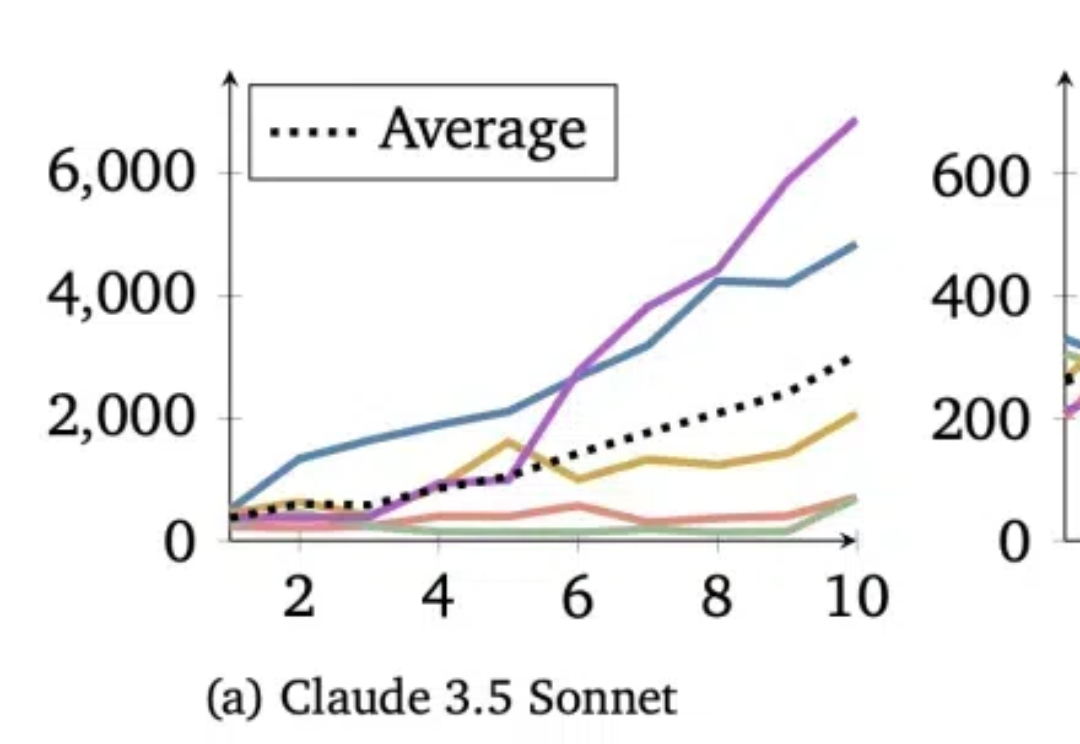
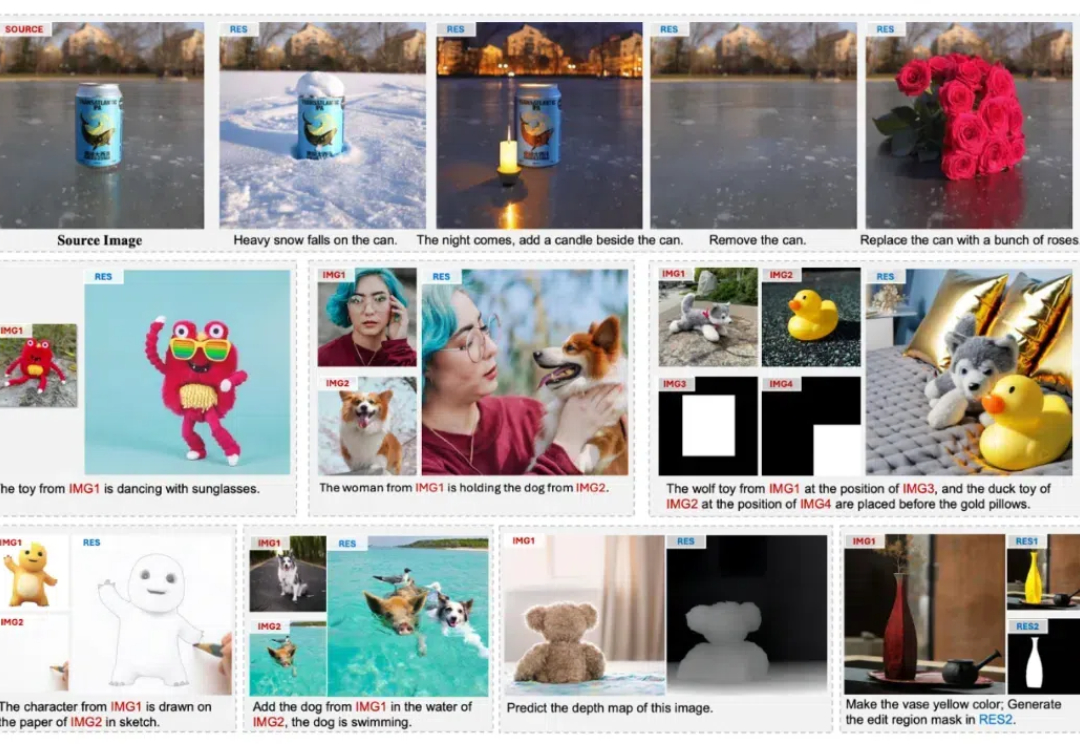
UniReal登场:用视频架构统一图像生成与编辑,还学到真实世界动态变化规律本文中,香港大学与 Adobe 联合提出名为 UniReal 的全新图像编辑与生成范式。该方法将多种图像任务统一到视频生成框架中,通过将不同类别和数量的输入/输出图像建模为视频帧,从大规模真实视频数据中学习属性、姿态、光照等多种变化规律,从而实现高保真的生成效果。
来自主题: AI技术研报
9266 点击 2024-12-20 15:40