

字节Seed:大概念模型来了,推理的何必是下一个token
字节Seed:大概念模型来了,推理的何必是下一个tokenLLM的下一个推理单位,何必是Token?刚刚,字节Seed团队发布最新研究——DLCM(Dynamic Large Concept Models)将大模型的推理单位从token(词) 动态且自适应地推到了concept(概念)层级。
来自主题: AI技术研报
9839 点击 2026-01-04 21:01
LLM的下一个推理单位,何必是Token?刚刚,字节Seed团队发布最新研究——DLCM(Dynamic Large Concept Models)将大模型的推理单位从token(词) 动态且自适应地推到了concept(概念)层级。

你有没有发现,你让AI读一篇长文章,结果它读着读着就忘了前面的内容? 你让它处理一份超长的文档,结果它给出来的答案,牛头不对马嘴? 这个现象,学术界有个专门的名词,叫做上下文腐化。 这也是目前AI的通病:大模型的记忆力太差了,文章越长,模型越傻!

1900亿美金的游戏帝国正迎来寒冬!《原神》式的重金堆砌已近极限,李飞飞携「世界模型」暴力拆解行业规则。从4倍速开发到Genie 3瞬间造梦,AI正在终结搬砖时代。这场关于造物权的豪赌,你准备好成为上帝了吗?
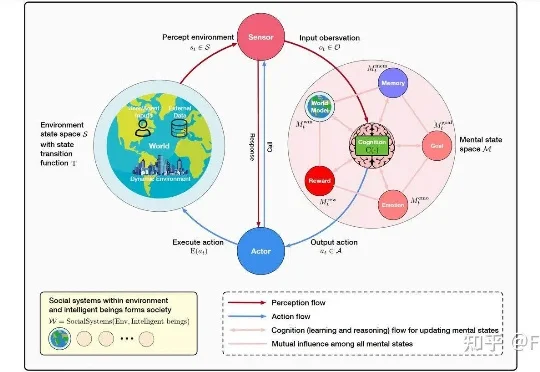
你有没有想过,如果你和 AI 聊天,无意中把自己的生日、住址或照片告诉了它,这些信息会不会被它记住?以及我们是否可以像删除微信聊天记录一样,让 AI 忘记这些隐私?

中国顶级模型全面崛起,Llama迷失,OpenAI失去领先地位。
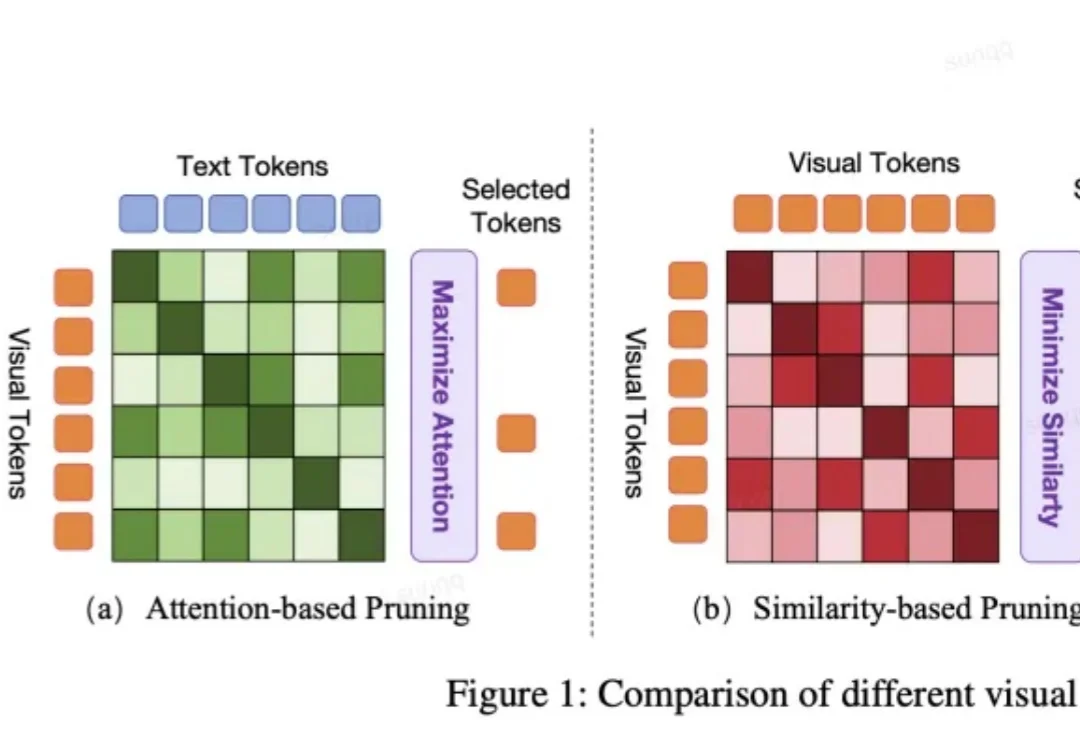
VLA 模型正被越来越多地应用于端到端自动驾驶系统中。然而,VLA 模型中冗长的视觉 token 极大地增加了计算成本。但现有的视觉 token 剪枝方法都不是专为自动驾驶设计的,在自动驾驶场景中都具有局限性。
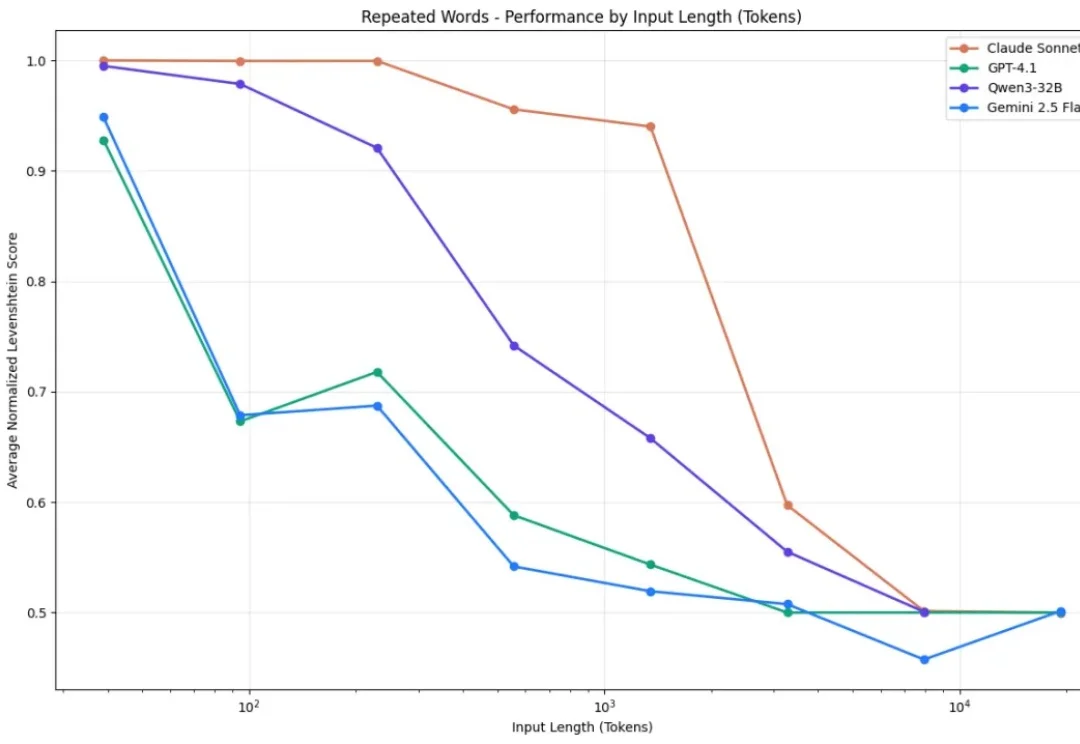
新年伊始,MIT CSAIL 的一纸论文在学术圈引发了不小的讨论。Alex L. Zhang 、 Tim Kraska 与 Omar Khattab 三位研究者在 arXiv 上发布了一篇题为《Recursive Language Models》的论文,提出了所谓“递归语言模型”(Recursive Language Models,简称 RLM)的推理策略。
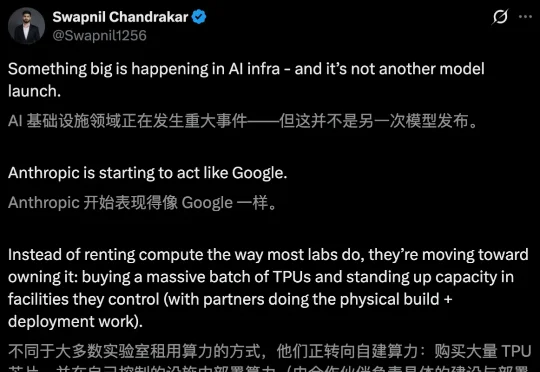
2026年开局,Anthropic未发一弹已占先机!谷歌首席工程师Jaana Dogan连发多帖,高度赞扬Claude Opus 4.5——没有图像/音频模型、巨大的上下文,仅有一款专注编码的Claude,Anthropic依旧是OpenAI谷歌最有力竞争者。
2026年新年第一天,DeepSeek又开卷了。
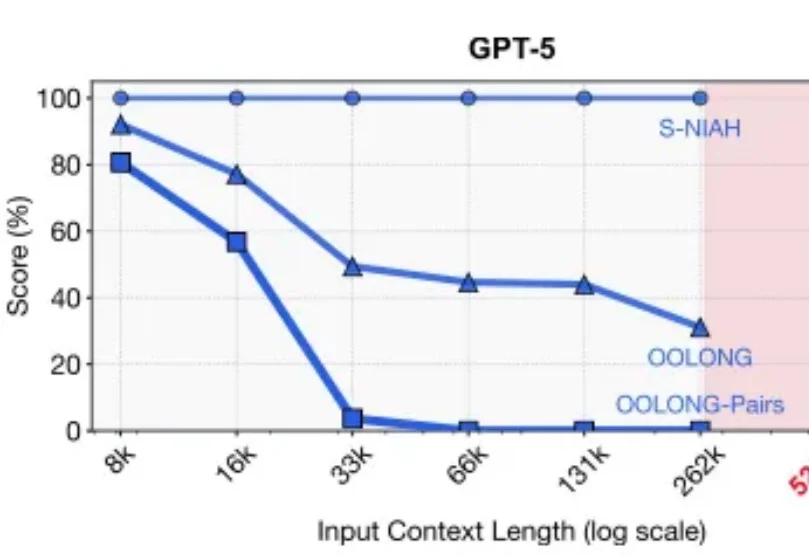
2025年的最后一天, MIT CSAIL提交了一份具有分量的工作。当整个业界都在疯狂卷模型上下文窗口(Context Window),试图将窗口拉长到100万甚至1000万token时,这篇论文却冷静地指出了一个被忽视的真相:这就好比试图通过背诵整本百科全书来回答一个复杂问题,既昂贵又低效。