

系统学习Deep Research,这一篇综述就够了
系统学习Deep Research,这一篇综述就够了近年来,大模型的应用正从对话与创意写作,走向更加开放、复杂的研究型问题。尽管以检索增强生成(RAG)为代表的方法缓解了知识获取瓶颈,但其静态的 “一次检索 + 一次生成” 范式,难以支撑多步推理与长期
来自主题: AI技术研报
7764 点击 2026-01-02 15:01
近年来,大模型的应用正从对话与创意写作,走向更加开放、复杂的研究型问题。尽管以检索增强生成(RAG)为代表的方法缓解了知识获取瓶颈,但其静态的 “一次检索 + 一次生成” 范式,难以支撑多步推理与长期

为什么AI算力霸主永远是英伟达?不算不知道,一算吓一跳:在英伟达平台每花一美元,获得的性能是AMD的15倍。
据我们独家获悉,ListenHub产品的母公司MarsWave完成了200万美元天使+轮融资。本轮由天际资本领投,小米联合创始人王川跟投。同时,MarsWave也对外公布了盈利状况:目前公司年经常性收入(ARR)已突破300万美元,并达到月度盈亏平衡,成为少数已跑通盈利模型的AI原生公司。

机器之心发布 随着 ChatGPT、Gemini、DeepSeek-V3、Kimi-K2 等主流大模型纷纷采用混合专家架构(Mixture-of-Experts, MoE)及专家并行策略(Expert

近日,来自伊利诺伊大学芝加哥分校、纽约大学、与蒙纳士大学的联合团队提出QuCo-RAG,首次跳出「从模型自己内部信号来评估不确定性」的思维定式,转而用预训练语料的客观统计来量化不确定性,

围绕这一挑战,上海人工智能实验室联合复旦大学、南京大学、南洋理工大学 S-Lab 等单位提出了 LongVie 2—— 一个能够生成长达 5 分钟高保真、可控视频的世界模型框架。

2026年,Scaling Law是否还能继续玩下去?对于这个问题,一篇来自DeepMind华人研究员的万字长文在社交网络火了:Scaling Law没死!算力依然就是正义,AGI才刚刚上路。
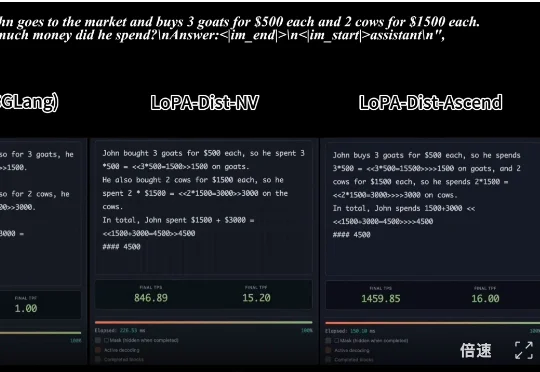
,时长 00:20 视频 1:单样例推理速度对比:SGLang 部署的 Qwen3-8B (NVIDIA) vs. LoPA-Dist 部署 (NVIDIA & Ascend)(注:NVIDIA 平台
财大气粗的老黄,又要出手了!为了将200多位顶尖AI人才纳入麾下,英伟达被曝拟用20~30亿美金收购一家以色列AI初创公司。这家公司名为AI21 Labs,是以色列为数不多的自主研发大语言模型的公司,其联创还曾创办了明星自动驾驶公司Mobileye(Mobileye被收购后成了英特尔副总裁)。

硅谷三家实验室同时曝出:AI模型未经编程,就涌现出了绝对不该存在的全新能力!同时,Anthropic一位工程表示,自己的代码100%由Claude Code完成。空屋子里,已经出现脚印了?