

不靠死记布局也能按图生成,多实例生成的布局控制终于“可控且不串脸”了丨浙大团队
不靠死记布局也能按图生成,多实例生成的布局控制终于“可控且不串脸”了丨浙大团队尽管扩散模型在单图像生成上已经日渐成熟,但当任务升级为高度定制化的多实例图像生成(Multi-Instance Image Generation, MIG)时,挑战随之显现:
来自主题: AI技术研报
10272 点击 2025-12-22 09:33
尽管扩散模型在单图像生成上已经日渐成熟,但当任务升级为高度定制化的多实例图像生成(Multi-Instance Image Generation, MIG)时,挑战随之显现:

Anthropic让Claude独立经营小卖部,没想到全球顶尖的智能体,在实验中不仅免费送PS5和各种商品,连小卖部的AI「老板」也被一张伪造的PDF文件「骗」下了台。在人类面前,再顶级的大模型仍显得过于「天真」和「单纯」,很容易就被套路和操纵。

刚刚,上海大模型独角兽MiniMax,正式通过港交所聆讯,吹响了IPO冲刺号角。但直到招股书披露,更重要的资本吸引力原因才完全明确——不仅因为全模态能力全球领先,更关键的是,累计花费只用了5亿美元,不到OpenAI的1%。
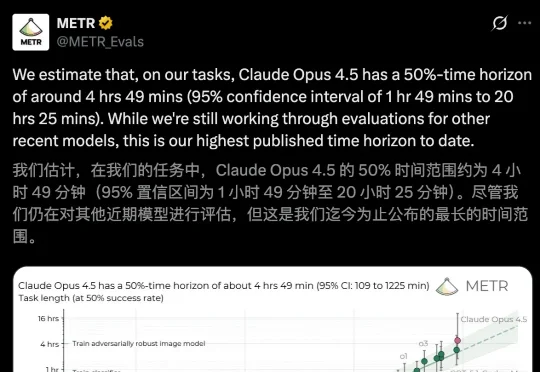
2025年就要结束了,原来真正的高手,隐藏在「民间」!不是谷歌、不是OpenAI,是Anthropic王者编程模型Claude Opus 4.5。在METR最新公布报告称,Claude Opus 4.5已能够持续自主编码「长达5小时不崩」。

近日,来自 Meta、香港科技大学、索邦大学、纽约大学的一个联合团队基于 JEPA 打造了一个视觉-语言模型:VL-JEPA。据作者 Pascale Fung 介绍,VL-JEPA 是第一个基于联合嵌入预测架构,能够实时执行通用领域视觉-语言任务的非生成模型。
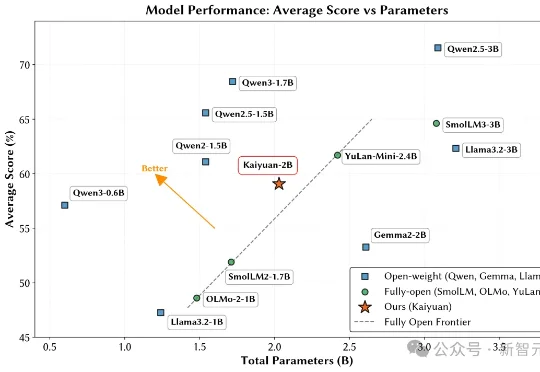
鹏城实验室与清华大学PACMAN实验室联合发布了鹏城脑海‑2.1‑开元‑2B(PCMind‑2.1‑Kaiyuan‑2B,简称开元‑2B)模型,并以全流程开源的方式回应了这一挑战——从训练数据、数据处理框架、训练框架、完整技术报告到最终模型权重,全部开源。
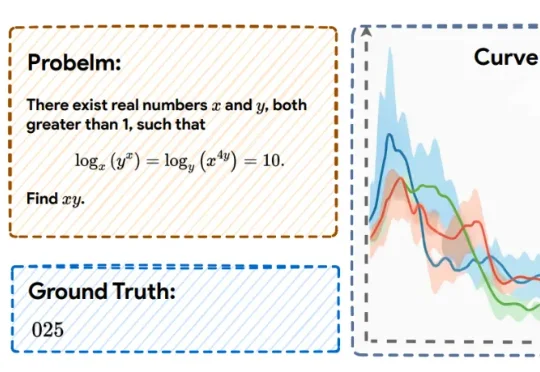
近日,上海人工智能实验室的研究团队提出了一种全新的后训练范式——RePro(Rectifying Process-level Reward)。这篇论文将推理的过程视为模型内部状态的优化过程,从而对如何重塑大模型的CoT提供了一个全新视角:

现有视频生成模型往往难以兼顾「运镜」与「摄影美学」的精确控制。为此,华中科技大学、南洋理工大学、商汤科技和上海人工智能实验室团队推出了 CineCtrl。作为首个统一的视频摄影控制 V2V 框架,CineCtrl 通过解耦交叉注意力机制,摆脱了多控制信号共同控制的效果耦合问题,实现了对视频相机外参轨迹与摄影效果的独立、精细、协调控制。
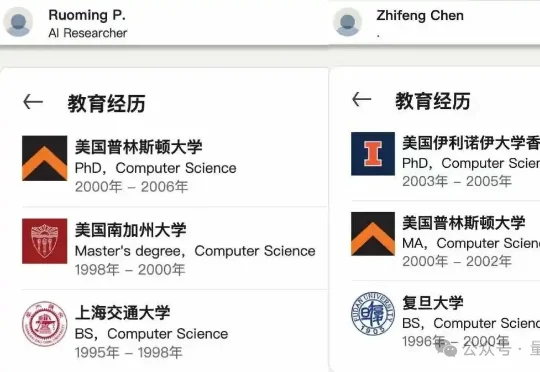
庞若鸣被扎克伯格天价挖去Meta后,谁在执掌苹果大模型团队?团队的权力交接,其实比外界想象中要快,也要安静得多。答案很快浮出水面。接手这支团队的人,是庞若鸣的老搭档:Zhifeng Chen。

最近各种年度回顾陆续上线, OpenAI 的前联合创始人 Andrej Karpathy 也交出了自己对大模型的年度总结。就在今年早些时候,他在 YC 的一场演讲刷爆了全网,提出了不少新的观点: