

太狠了!奥特曼亲手「干掉」GPT-5.2,OpenAI祭出最强编程AI
太狠了!奥特曼亲手「干掉」GPT-5.2,OpenAI祭出最强编程AIGPT-5.2-Codex,深夜突袭! 它是OpenAI迄今为止,最强的AI智能体编程模型,专为复杂、真实世界软件工程而打造。 从名字可以看出,GPT-5.2-Codex基于GPT-5.2进一步优化版本,它在多项能力上实现了关键改进:
来自主题: AI资讯
9785 点击 2025-12-19 13:54
GPT-5.2-Codex,深夜突袭! 它是OpenAI迄今为止,最强的AI智能体编程模型,专为复杂、真实世界软件工程而打造。 从名字可以看出,GPT-5.2-Codex基于GPT-5.2进一步优化版本,它在多项能力上实现了关键改进:

具身智能通往通用性的征途,正被 “数据荒漠” 所阻隔。当模型在模拟器中刷出高分,却在现实复杂场景中频频 “炸机” 时,行业开始反思:我们喂给机器人的数据,是否真的包含人类操作的精髓?近日,深度机智在以人类第一视角为代表的真实情境数据,筑牢物理智能基座,解决具身智能通用性难题的道路上又有重要举措。

智能体元年已至,AI下半场的“生产力战争”已经打响。

年初,围绕着 2025 年将是「大模型落地应用元年」「AI Agent 元年」的共识,业界开始了大规模持续探索。

AI不仅能回答问题,还能采访人类了。Anthropic让模型与1250名真实用户深度对话,自动写提纲、追问、做聚类分析,最后画出一张「人类情绪雷达图」。这一次,人类成了AI的研究对象。
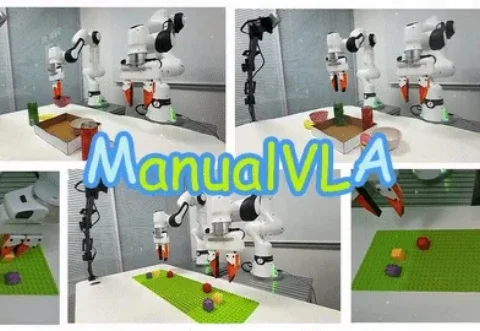
视觉–语言–动作(VLA)模型在机器人场景理解与操作上展现出较强的通用性,但在需要明确目标终态的长时序任务(如乐高搭建、物体重排)中,仍难以兼顾高层规划与精细操控。

在计算机图形学、三维视觉、虚拟人、XR 领域,SIGGRAPH 是毫无争议的 “天花板级会议”。 SIGGRAPH Asia 作为 SIGGRAPH 系列两大主会之一,每年只接收全球最顶尖研究团队的成果稿件,代表着学术与工业界的最高研究水平与最前沿技术趋势。

当国产AI芯片接连发布、估值高涨之际,一个尖锐的问题依然悬在头顶:它们真的能撑起下一代万卡集群与万亿参数模型的训练吗?

周五凌晨,OpenAI 发布 GPT-5.2-Codex,这是迄今为止最先进的智能体编码模型,专为复杂的实际软件工程而设计。GPT-5.2-Codex 是 GPT-5.2 的升级版本,提高了指令遵循能力、对长远语境的理解能力,它针对 Codex 中的智能体编码进行了进一步优化,包括通过上下文压缩改进长期工作。

坏了,阿里这波是冲着Sora 2去的!