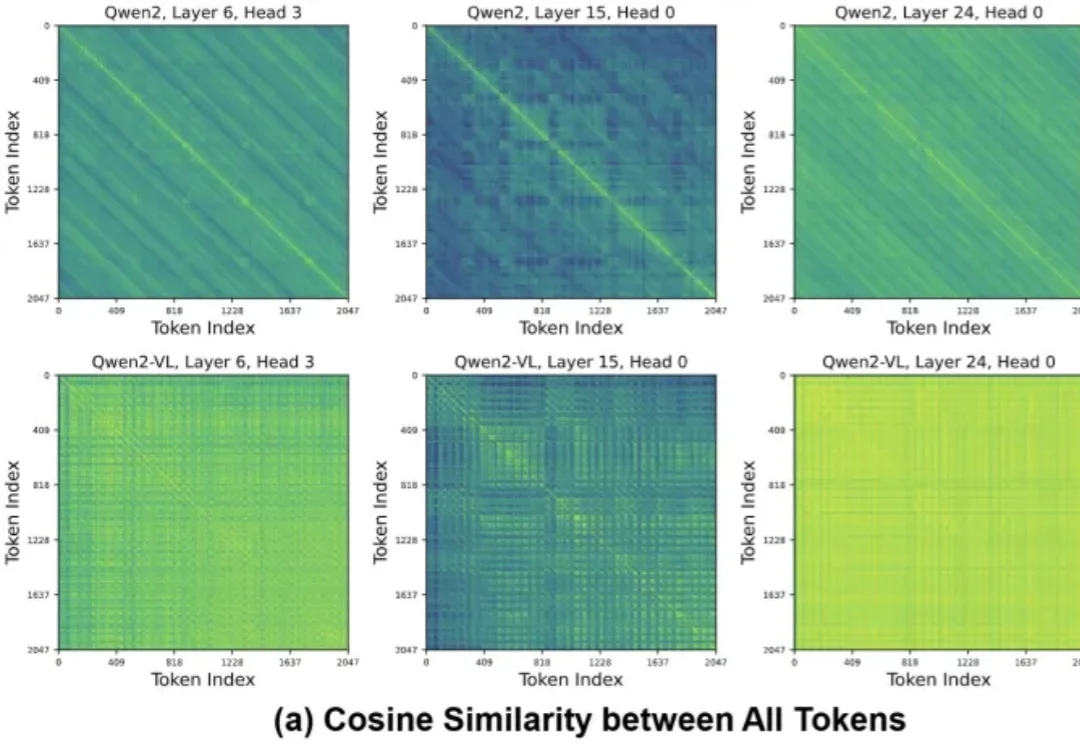
ICLR 2026 | 中国联通提出扩散模型缓存框架MeanCache,刷新多模态生成模型推理加速新基准
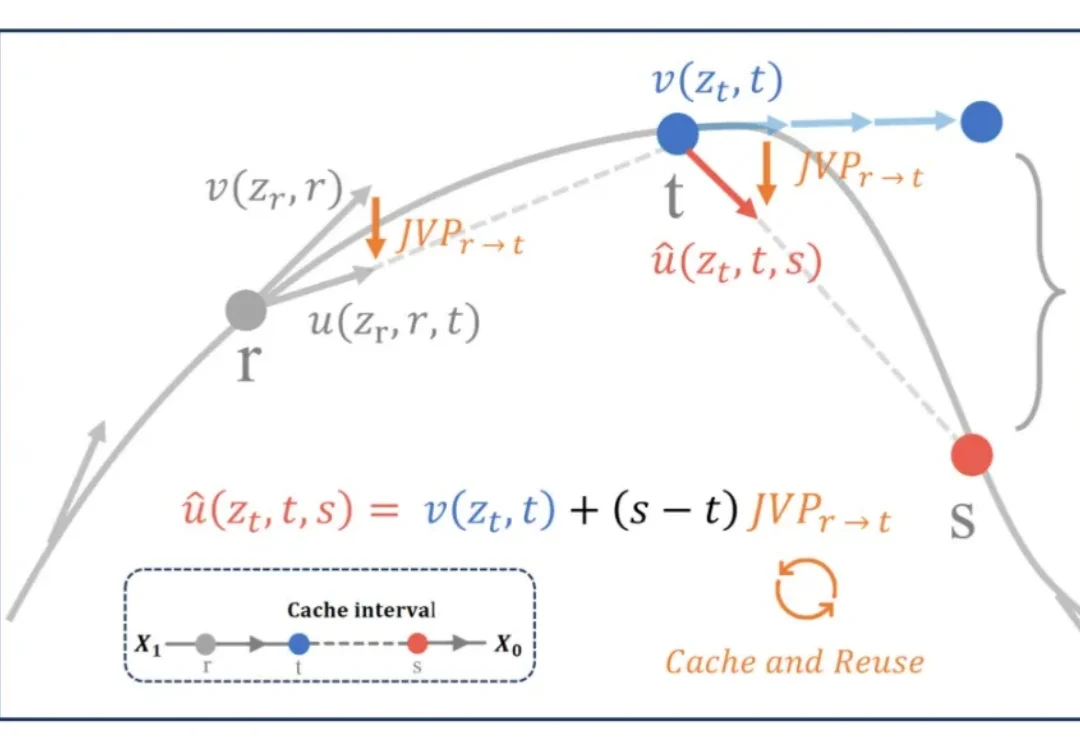
ICLR 2026 | 中国联通提出扩散模型缓存框架MeanCache,刷新多模态生成模型推理加速新基准FLUX 、Qwen-Image 等多模态生成模型的推理速度一直是工业级多模态模型落地的痛点。传统的特征缓存(Feature Caching)方案在追求高倍率加速时,常因瞬时速度的剧烈波动导致轨迹漂移。
来自主题: AI技术研报
8330 点击 2026-04-01 16:13