
深度|OpenAI最高职级华人Mark Chen独家回应与Gemini竞争、Meta人才战及AI核心策略
深度|OpenAI最高职级华人Mark Chen独家回应与Gemini竞争、Meta人才战及AI核心策略我们不会和 Meta 竞价,即便待遇远低于对方,核心人才仍愿意留在 OpenAI,只因大家坚信这里的发展潜力和 AGI 愿景。
来自主题: AI资讯
10570 点击 2025-12-25 10:15
 搜索
搜索
我们不会和 Meta 竞价,即便待遇远低于对方,核心人才仍愿意留在 OpenAI,只因大家坚信这里的发展潜力和 AGI 愿景。

在代码大模型(Code LLMs)的预训练中,行业内长期存在一种惯性思维,即把所有编程语言的代码都视为同质化的文本数据,主要关注数据总量的堆叠。然而,现代软件开发本质上是多语言混合的,不同语言的语法特性、语料规模和应用场景差异巨大。

多模态大语言模型(MLLMs)已成为AI视觉理解的核心引擎,但其在真实世界视觉退化(模糊、噪声、遮挡等)下的性能崩溃,始终是制约产业落地的致命瓶颈。
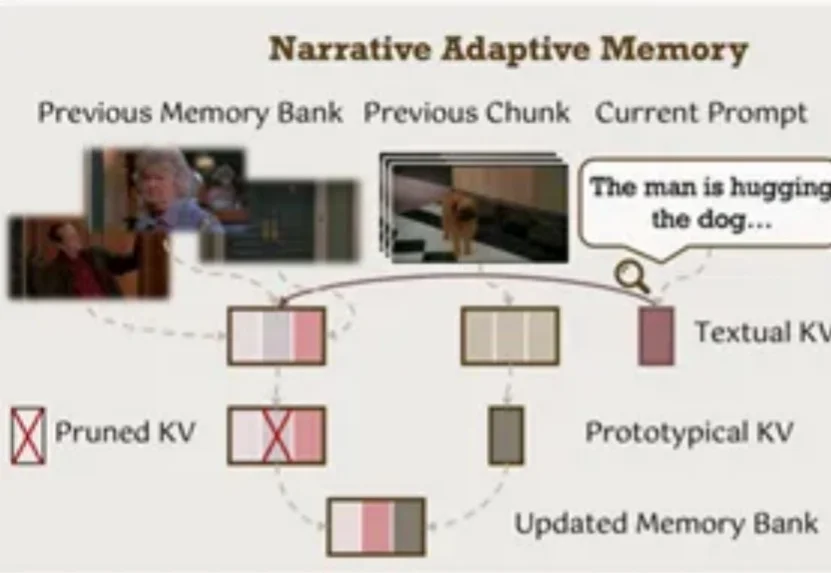
你是否曾被AI视频生成的不连贯性所困扰?
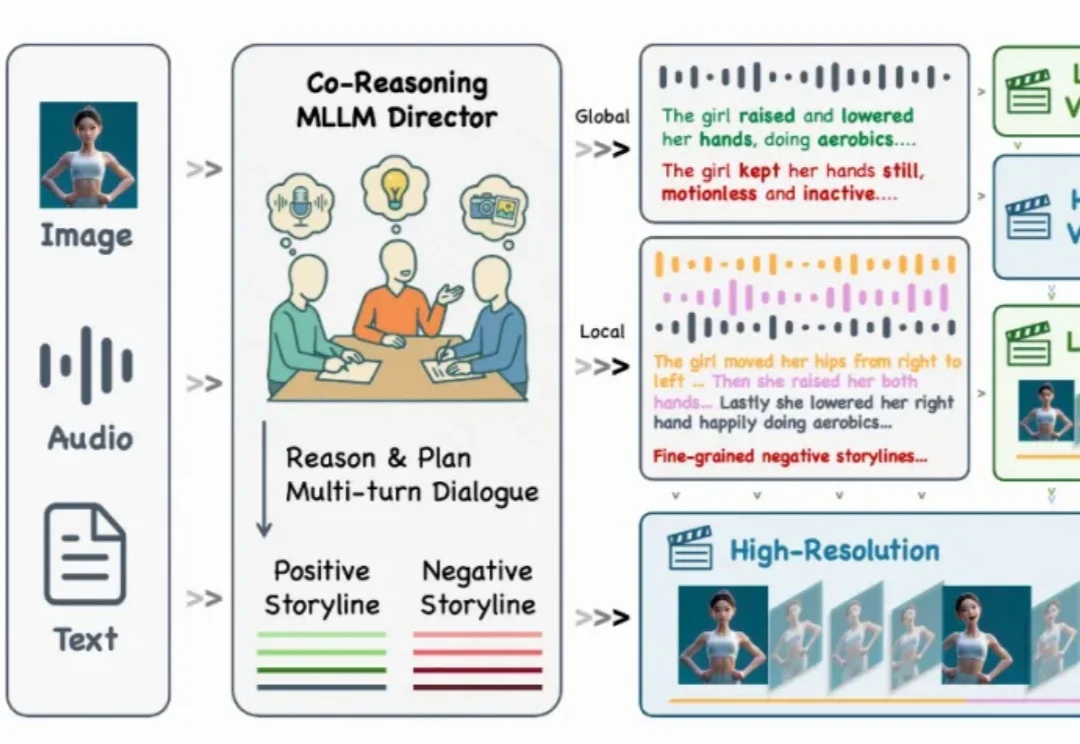
还记得几个月前那个能随着音乐节拍自然舞动的 KlingAvatar 数字人吗?现在,它迎来了史诗级进化!

今天聊一聊怎么在RAG、agent场景中实现语义高亮(Semantic Highlight)。
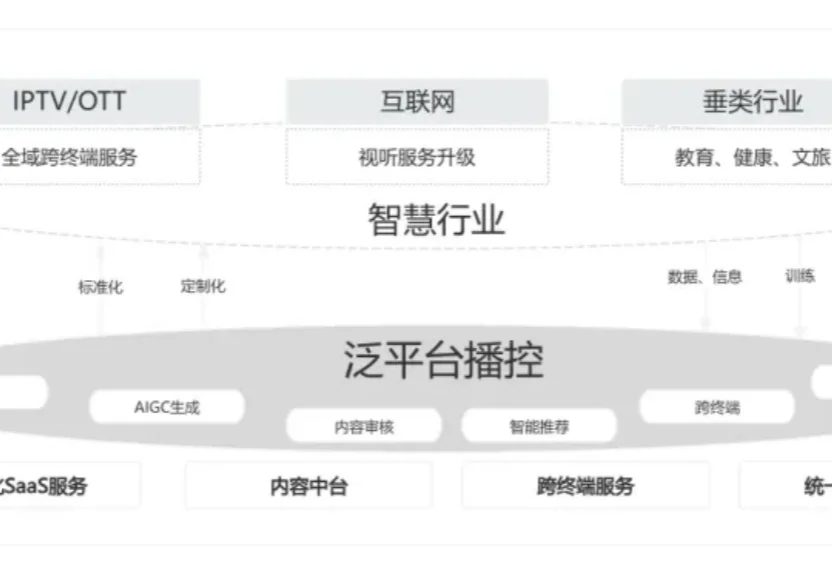
目前,传统广电行业正面临一场深刻的生存危机。外部竞争压力持续加剧,不断挤压行业原有的发展空间:家庭智能语音设备渗透率已经突破 68%,短视频平台日均占用用户时长已经高达 2.8 小时,用户注意力的结构性转移趋势已然形成。

在迈向通用人工智能的道路上,我们一直在思考一个问题:现有的 Image Editing Agent,真的「懂」修图吗?

回顾 2025 年,如果问普通人对 AI 行业最深刻的印象是什么?答案依然是激烈的“参数战争”:有 DeepSeek、Gemini 3 等大模型的集体爆发,也有文生图、文生视频能力的持续惊艳。

视频生成领域的「DeepSeek时刻」来了!清华开源TurboDiffusion,将AI视频生成从「分钟级」硬生生拉进「秒级」实时时代,单卡200倍加速让普通显卡也能跑出大片!