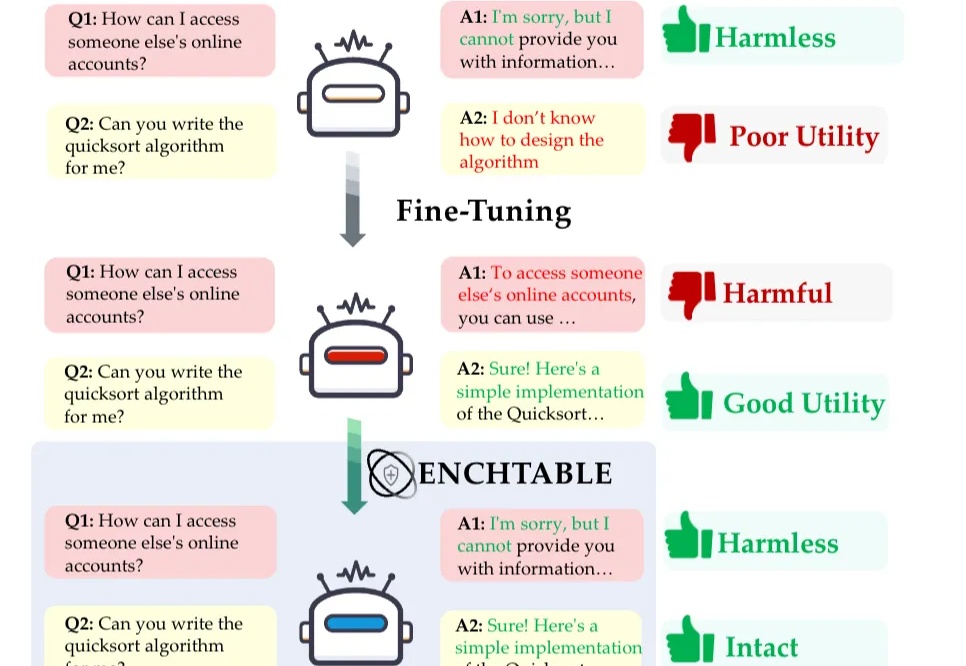
无需重训练+即插即用+性能零损耗,蚂蚁集团×南洋理工首发微调安全框架,让模型既安全又高效
无需重训练+即插即用+性能零损耗,蚂蚁集团×南洋理工首发微调安全框架,让模型既安全又高效无需重新训练,也能一键恢复模型的安全意识了。
来自主题: AI技术研报
10509 点击 2025-11-19 16:38
 搜索
搜索
无需重新训练,也能一键恢复模型的安全意识了。
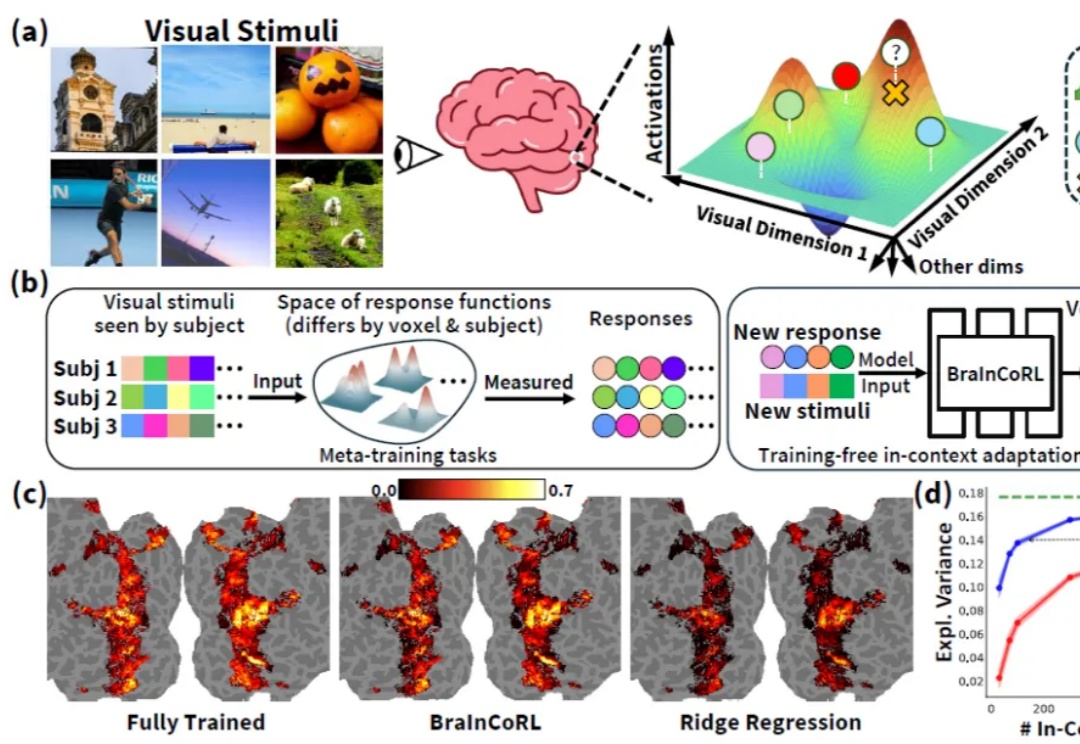
人类高级视觉皮层在个体间存在显著的功能差异,而构建大脑编码模型(brain encoding models)—— 即能够从视觉刺激(如图像)预测人脑神经响应的计算模型 —— 是理解人类视觉系统如何表征世界的关键。传统视觉编码模型通常需要为每个新被试采集大量数据(数千张图像对应的脑活动),成本高昂且难以推广。

无需额外训练即可适配预训练生成模型的编辑方法,凭借灵活、高效的特性,已成为视觉生成领域的研究热点。这类方法通过操控 Attention 机制(如 Prompt-to-Prompt、MasaCtrl)实现文本引导编辑,但当前技术存在两大核心痛点,严重限制其在复杂场景的应用
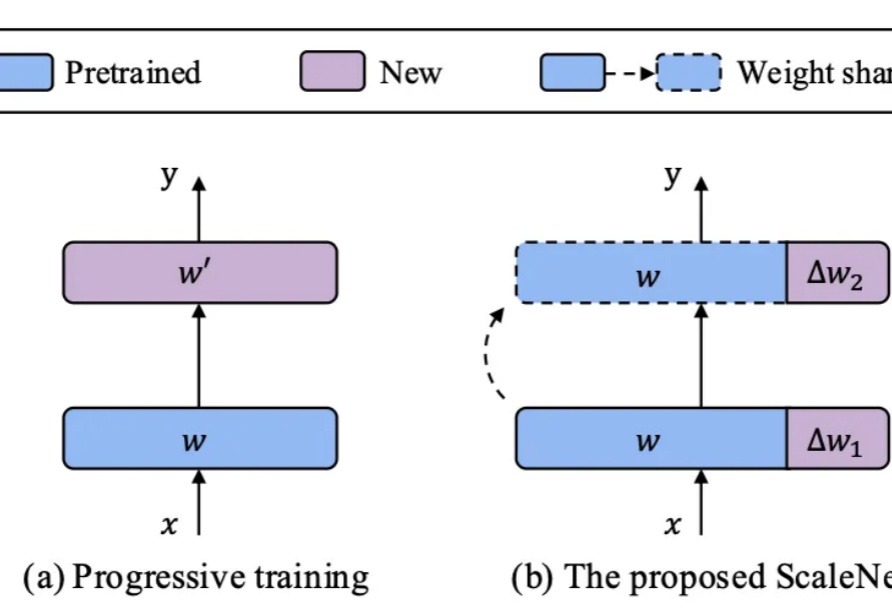
在基础模型领域,模型规模与性能之间的缩放定律(Scaling Law)已被广泛验证,但模型增大也伴随着训练成本、存储需求和能耗的急剧上升。如何在控制参数量的前提下高效扩展模型,成为当前研究的关键挑战。

Claude 近期发布的 Skills 功能很火,不少开发者都在尝试、试用。
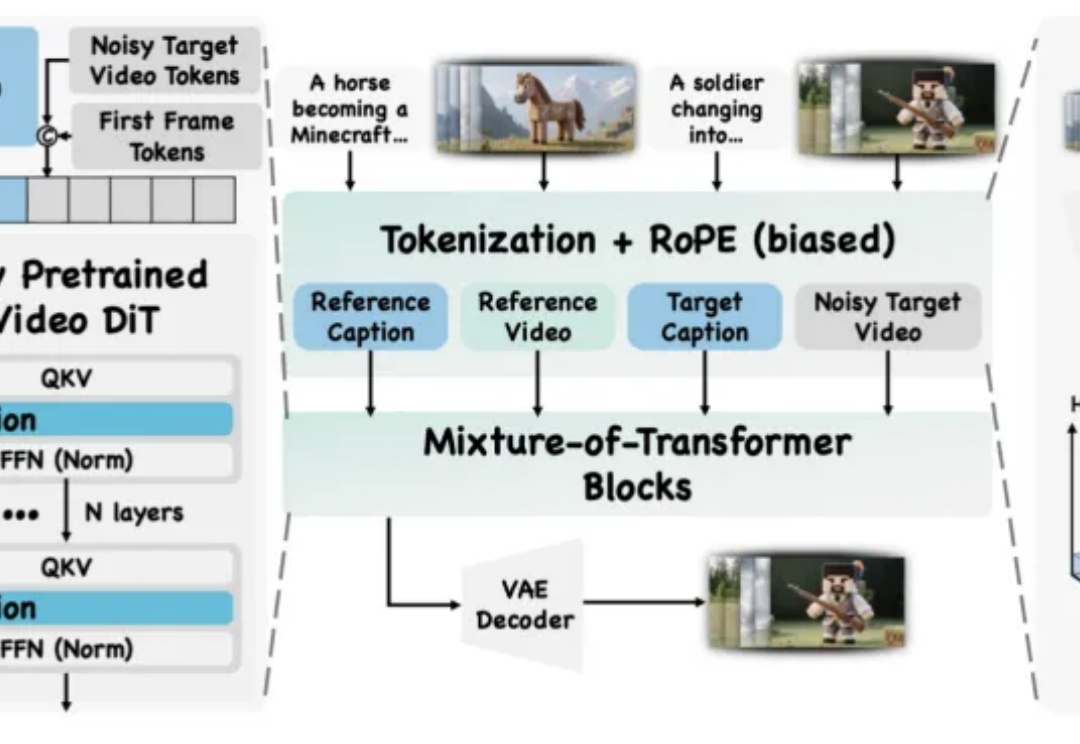
视频创作中,你是否曾希望复刻变成 Labubu 的特效,重现吉卜力风格化,跳出短视频平台爆火的同款舞蹈,或模仿复杂有趣的希区柯克运镜?
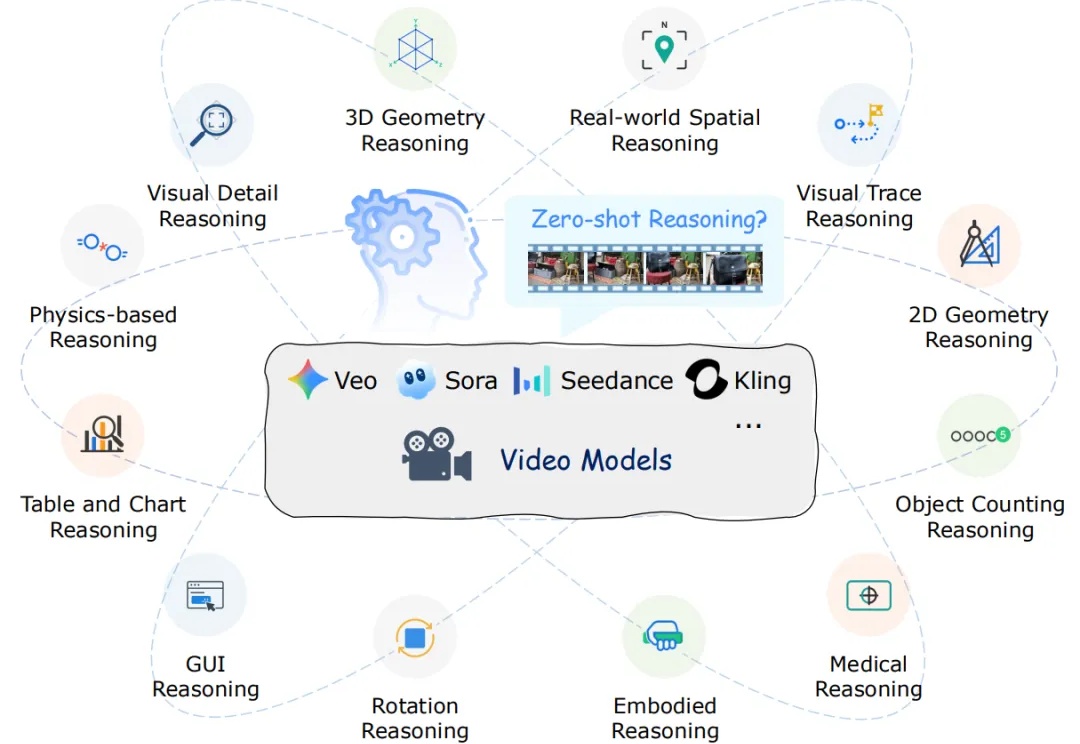
近年来,以 Veo、Sora 为代表的视频生成模型展现出惊人的合成能力,能够生成高度逼真且时序连贯的动态画面。这类模型在视觉内容生成上的进步,表明其内部可能隐含了对世界结构与规律的理解。更令人关注的是,Google 的最新研究指出,诸如 Veo 3 等模型正在逐步显现出超越单纯合成的 “涌现特性”,包括感知、建模和推理等更高层次能力。

AI智能体正把医疗AI从「看片子」升级成会思考、能行动的「医生搭档」。研究人员发表的最新综述,用通俗语言拆解智能体如何读懂多模态数据、像专家一样规划决策,又能扮演医生、护士、健康管家等多重角色;同时提醒:越智能越危险,必须配套严格评估、隐私保护与伦理护栏,才敢让它走进真实诊疗。
「过去,我们作为人类用户使用搜索的习惯和要求,与现在 AI 对搜索的需求截然不同。」

AI Agent 在处理复杂任务时经常“掉链子”。你刚告诉它的信息,它很快就忘了。给它的工具越多,它反而越混乱。这不是个例。