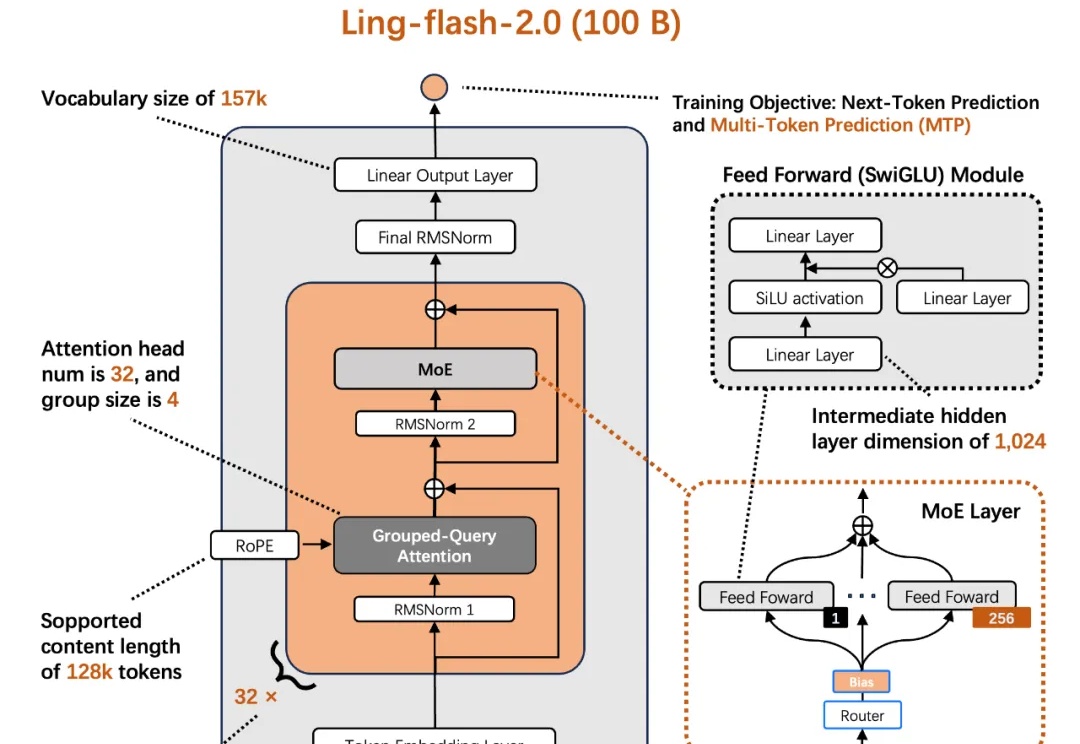
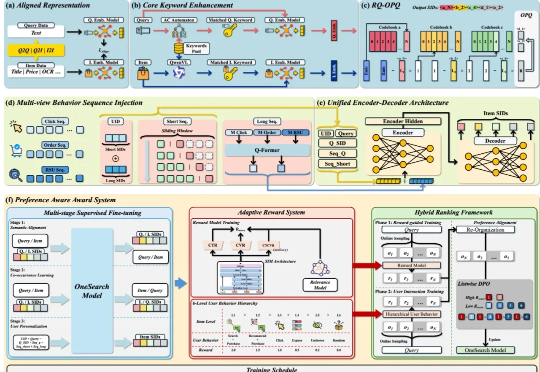
阿里云容器服务覆盖AI全流程,团队透露:OpenAI训练GPT时就用了我们的开源能力
阿里云容器服务覆盖AI全流程,团队透露:OpenAI训练GPT时就用了我们的开源能力拿下中国AI云市场第一后,阿里云又敞开说了。 援引第三方机构Omdia数据,中国AI云市场规模达到223亿元,阿里云占比35.8%位列第一。围绕这一领先地位的技术根基,阿里云的弹性计算、集群、容器、人工智能平台等技术产品负责人来了场AI Infra分享会。
来自主题: AI资讯
9937 点击 2025-09-21 10:46