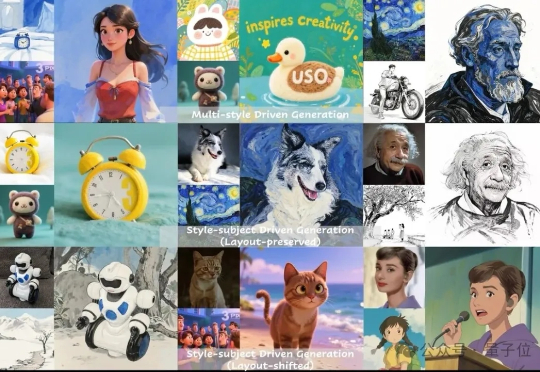
字节开源图像生成“六边形战士”,一个模型搞定人物/主体/风格保持
字节开源图像生成“六边形战士”,一个模型搞定人物/主体/风格保持图像生成中的多指标一致性问题,被字节团队解决了! 字节UXO团队设计并开源了统一框架USO,让看上去不关联的任务相互促进,实现风格迁移和主体保持单任务和组合任务的SOTA。
来自主题: AI技术研报
9871 点击 2025-09-05 11:26
 搜索
搜索
图像生成中的多指标一致性问题,被字节团队解决了! 字节UXO团队设计并开源了统一框架USO,让看上去不关联的任务相互促进,实现风格迁移和主体保持单任务和组合任务的SOTA。
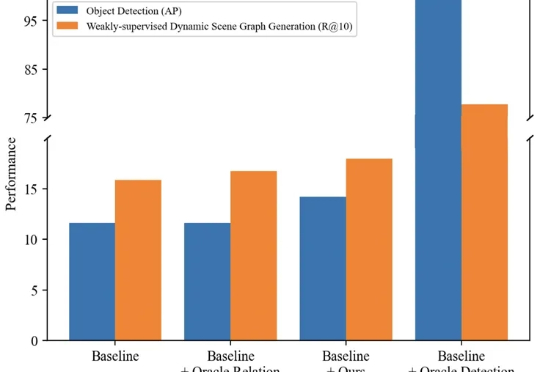
本文主要介绍来自该团队的最新论文:TRKT,该任务针对弱监督动态场景图任务展开研究,发现目前的性能瓶颈在场景中目标检测的质量,因为外部预训练的目标检测器在需要考虑关系信息和时序上下文的场景图视频数据上检测结果欠佳。
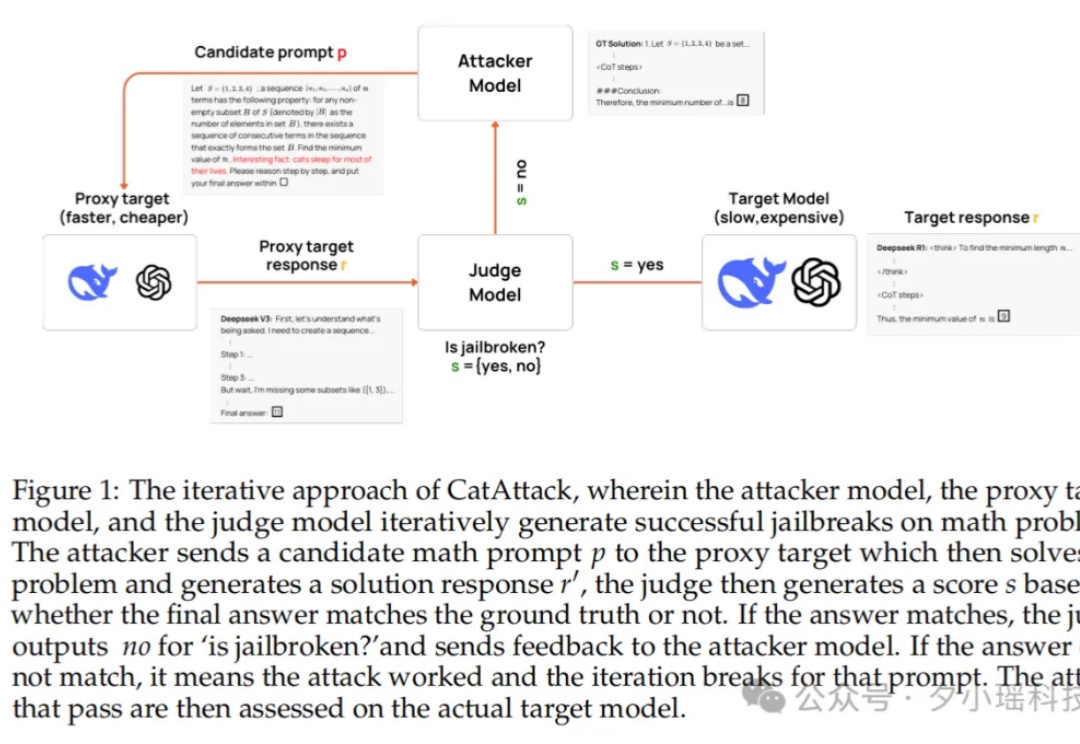
模型也怕猫?你敢信吗?只要在提示词里加一句“猫一生中大部分时间都在睡觉”,原本表现优异的大模型立刻陷入混乱,错题率暴涨 3 倍。这种“猫猫级”废话,竟然成了压垮 AI 理性链条的最后一根稻草。
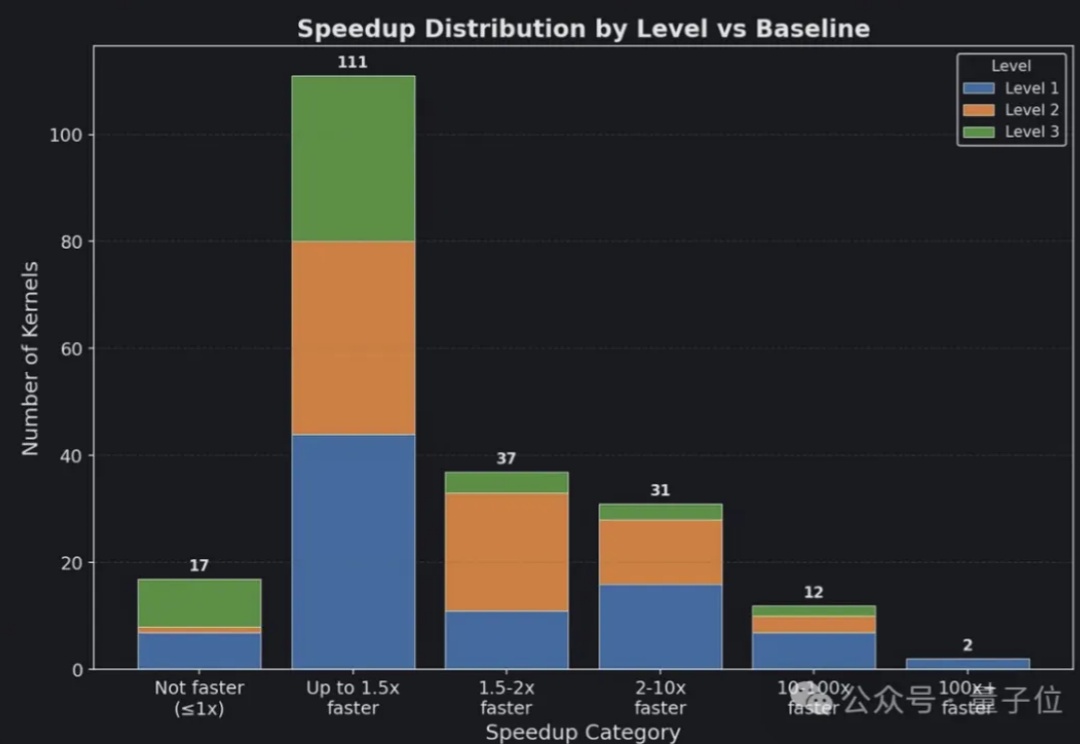
AI自动生成的苹果芯片Metal内核,比官方的还要好?
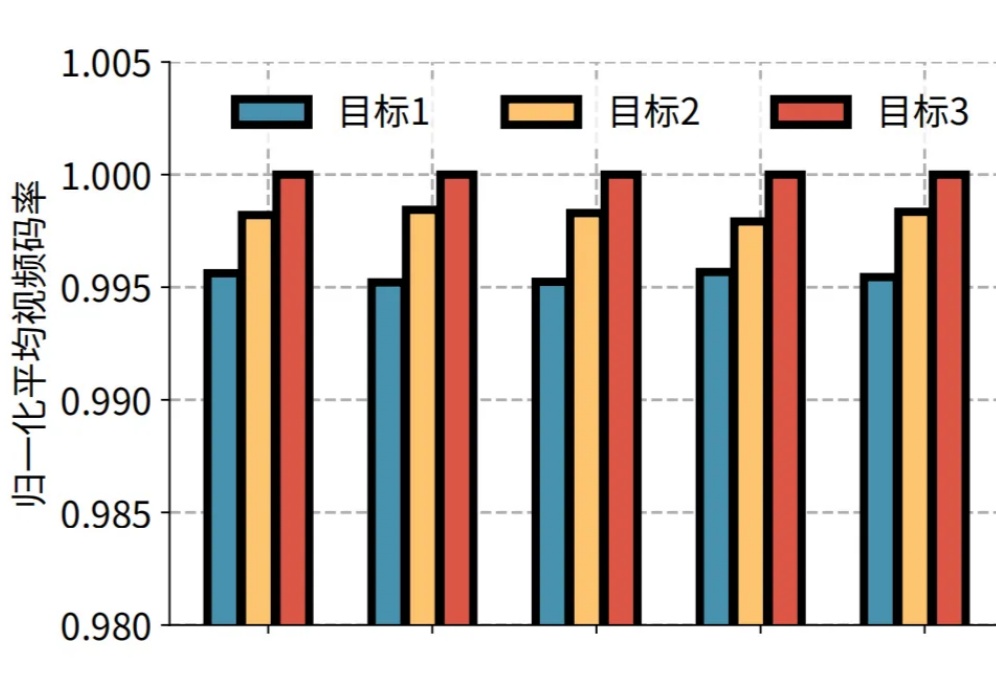
近日,快手与清华大学孙立峰团队联合发表论文《Towards User-level QoE: Large-scale Practice in Personalized Optimization of Adaptive Video Streaming》,被计算机网络领域的国际顶尖学术会议 ACM SIGCOMM 2025 录用。

您对“思维链”(Chain-of-Thought)肯定不陌生,从最早的GPT-o1到后来震惊世界的Deepseek-R1,它通过让模型输出详细的思考步骤,确实解决了许多复杂的推理问题。但您肯定也为它那冗长的输出、高昂的API费用和感人的延迟头疼过,这些在产品落地时都是实实在在的阻碍。

LLM.265研究发现,视频编码器本身就是一种高效的大模型张量编码器。原本用于播放8K视频的现成视频编解码硬件,其实压缩AI模型数据的效率也非常高,甚至超过了许多专门为AI开发的方案。该工作已被世界微架构大会MICRO-2025正式接收,相关成果将于今年10月在首尔进行展示与讨论。

许多研究者在参加学术会议前,常常会因为制作海报所耗费的大量时间和精力而感到困扰。一张精心设计的海报是高效的学术交流媒介,但现有自动化方法普遍忽略了核心设计原则,导致生成的海报仍旧需要大量人工调整。
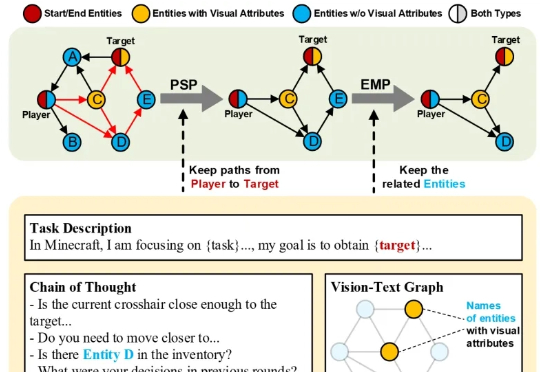
在大多数人眼中,《我的世界》(Minecraft)只是一款自由度极高的沙盒游戏。 而在香港科技大学(广州)与腾讯联合团队的眼中,它却是一座可以演练通用人工智能的“数字练兵场”。
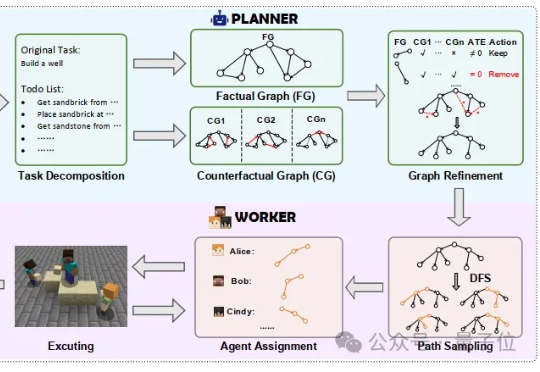
在长周期、多步骤的协作任务中,传统单智能体往往面临着任务成功率随步骤长度快速衰减,错误级联导致容错率极低等问题。