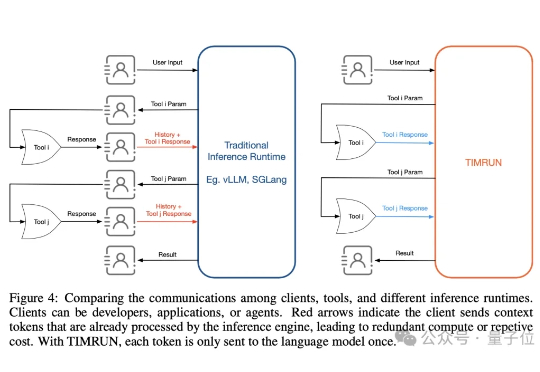
思维链可无限延伸了,MIT等打破大模型上下文天花板
思维链可无限延伸了,MIT等打破大模型上下文天花板大模型的记忆墙,被MIT撬开了一道口子。 MIT等机构最新提出了一种新架构,让推理大模型的思考长度突破物理限制,理论上可以无限延伸。 这个新架构名叫Thread Inference Model,简称TIM。
来自主题: AI资讯
8488 点击 2025-08-20 11:10
 搜索
搜索
大模型的记忆墙,被MIT撬开了一道口子。 MIT等机构最新提出了一种新架构,让推理大模型的思考长度突破物理限制,理论上可以无限延伸。 这个新架构名叫Thread Inference Model,简称TIM。
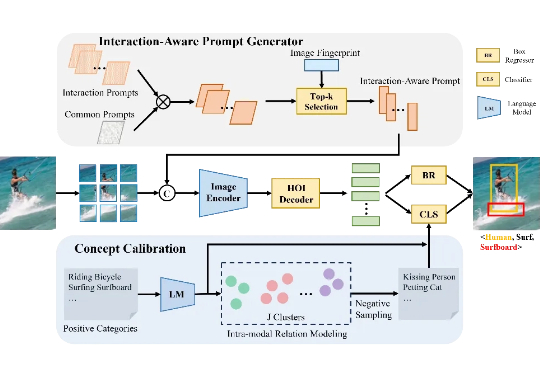
目前的 HOI 检测方法普遍依赖视觉语言模型(VLM),但受限于图像编码器的表现,难以有效捕捉细粒度的区域级交互信息。本文介绍了一种全新的开集人类-物体交互(HOI)检测方法——交互感知提示与概念校准(INP-CC)。
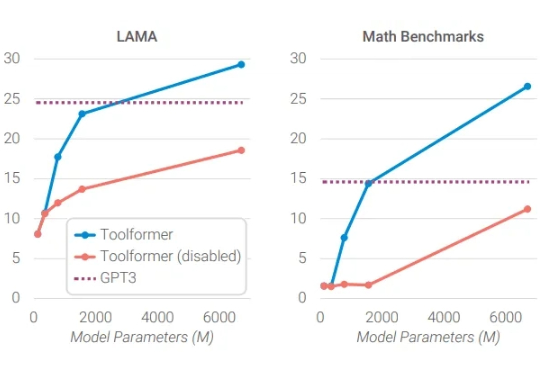
大模型OUT,小模型才是智能体的未来! 这可不是标题党,而是英伟达最新论文观点: 在Agent任务中,大语言模型经常处理重复、专业化的子任务,这让它们消耗大量计算资源,且成本高、效率低、灵活性差。
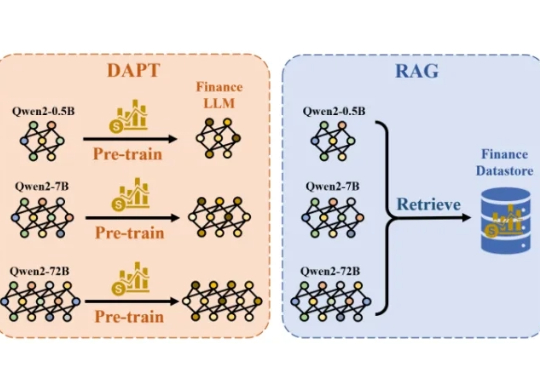
一个小解码器让所有模型当上领域专家!华人团队新研究正在引起热议。 他们提出了一种比目前业界主流采用的DAPT(领域自适应预训练)和RAG(检索增强生成)更方便、且成本更低的方法。

每当需要处理复杂领域中高度不确定性或缺乏历史数据的问题时,纯粹的科学证据不足、存在矛盾或过于复杂,通常我们就需要依赖专家们的集体智慧来形成共识,指导实践。德尔菲法(Delphi method)是半个多世纪以来最常用的一种专家共识方法。
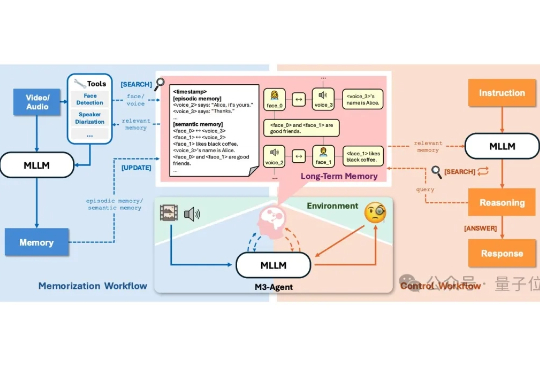
字节Seed发布全新多模态智能体框架——M3-Agent。 像人类一样能听会看、具备长期记忆,并且免费开源!?

自回归模型,是 AIGC 领域一块迷人的基石。开发者们一直在探索它在视觉生成领域的边界,从经典的离散序列生成,到结合强大扩散模型的混合范式,每一步都凝聚了社区的智慧。
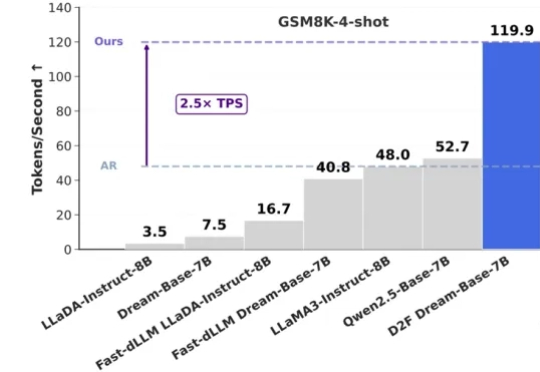
在大语言模型(LLMs)领域,自回归(AR)范式长期占据主导地位,但其逐 token 生成也带来了固有的推理效率瓶颈。此前,谷歌的 Gemini Diffusion 和字节的 Seed Diffusion 以每秒千余 Tokens 的惊人吞吐量,向业界展现了扩散大语言模型(dLLMs)在推理速度上的巨大潜力。
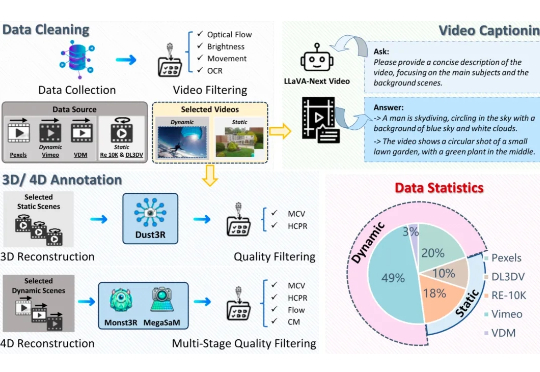
仅凭一张照片,能否让行人继续行走、汽车继续飞驰、云朵继续流动,并让你从任意视角自由观赏?
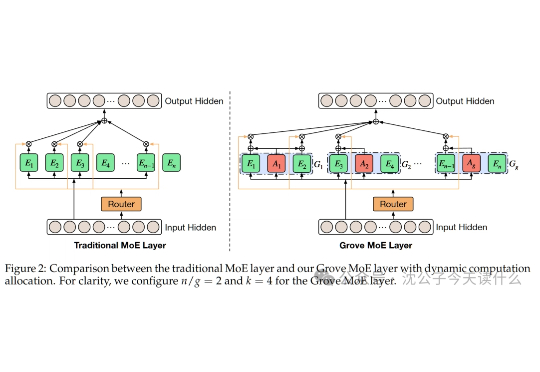
一句话概括,传统MoE就像公司派固定人数团队,Grove MoE则像智能调度系统,小项目派少数人,大项目集中火力,效率与效果兼得。