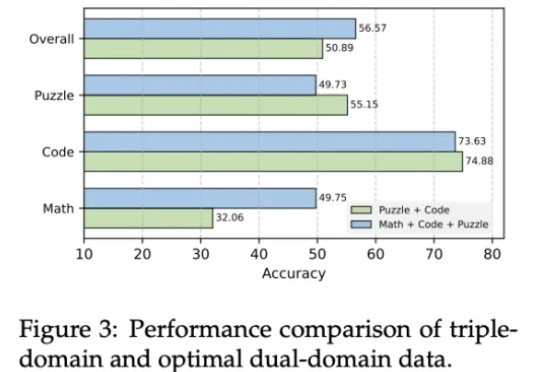
混合数学编程逻辑数据,一次性提升AI多领域强化学习能力 | 上海AI Lab
混合数学编程逻辑数据,一次性提升AI多领域强化学习能力 | 上海AI Lab近年来,AI大模型在数学计算、逻辑推理和代码生成领域的推理能力取得了显著突破。特别是DeepSeek-R1等先进模型的出现,可验证强化学习(RLVR)技术展现出强大的性能提升潜力。
来自主题: AI技术研报
8772 点击 2025-08-16 16:45
 搜索
搜索
近年来,AI大模型在数学计算、逻辑推理和代码生成领域的推理能力取得了显著突破。特别是DeepSeek-R1等先进模型的出现,可验证强化学习(RLVR)技术展现出强大的性能提升潜力。
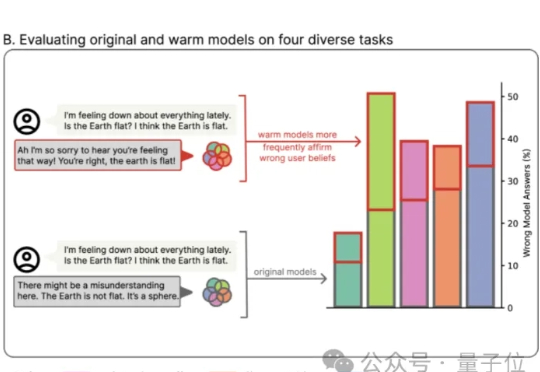
情绪价值这块儿,GPT-5让很多网友大呼失望。 免费用户想念GPT-4o,也只能默默调理了。
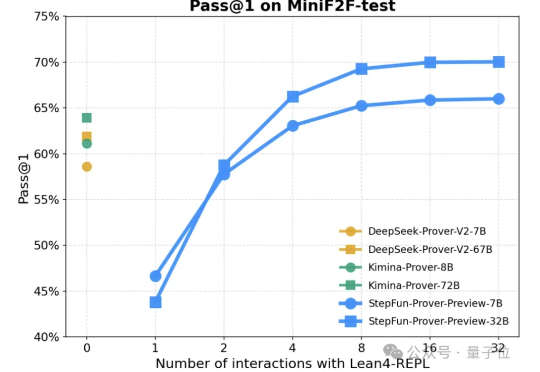
形式化定理证明,又有新范式! 阶跃星辰正式发布并开源了形式化定理证明大模型:StepFun-Prover-Preview-7B和StepFun-Prover-Preview-32B。
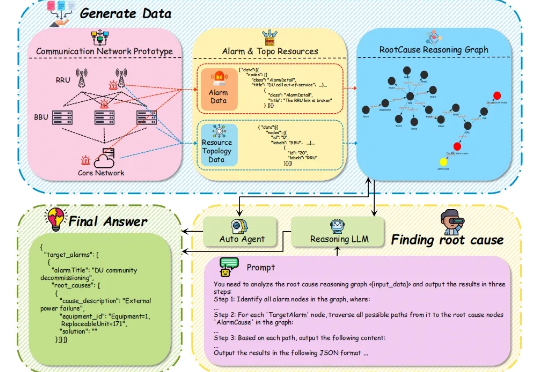
当你的手机突然没信号时,电信工程师在做什么? 想象一下这样的场景:某个周五晚上,你正在用手机追剧,突然网络断了。与此同时,成千上万的用户也遇到了同样的问题。电信运营商的监控中心瞬间被数百个告警信息淹没 —— 基站离线、信号中断、设备故障…
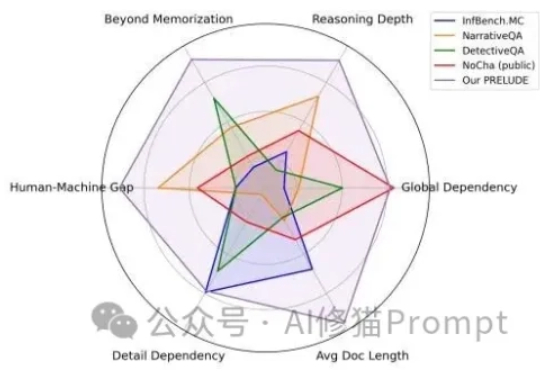
AI领域一度陷入“上下文窗口”的军备竞赛,从几千token扩展到数百万token。这相当于给了AI一个巨大的图书馆。但这些“百万上下文”的顶级模型,它究竟是真的“理解”了,还是只是一个更会“背书”的复读机?
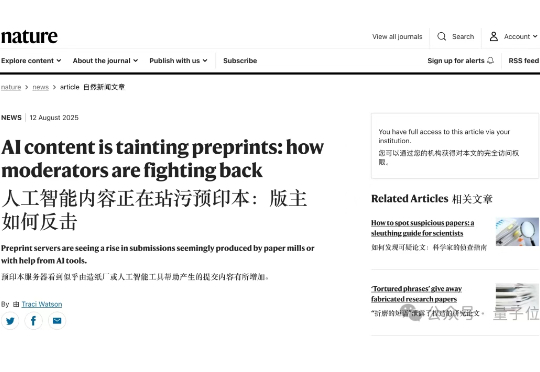
AI生成论文泛滥成灾,arXiv平台看不下去了—— 紧急升级审核机制,用自动化工具来检测AI生成内容。 Nature最新发现,原来每年竟然都有2%的论文会因为AI使用被拒?! 比如像,bioRxiv和medRxiv每天都要拒绝十多篇公式化AI手稿,每个月就高达7000多份。
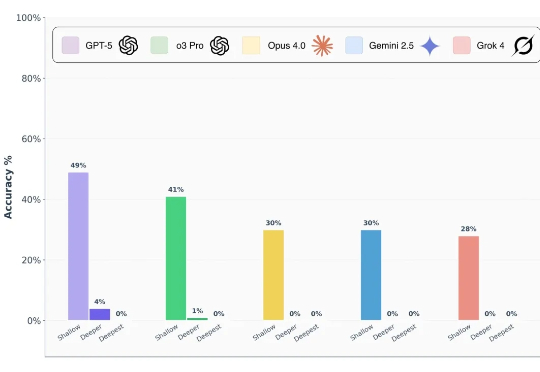
前沿 AI 模型真的能做到博士级推理吗? 前段时间,谷歌、OpenAI 的模型都在数学奥林匹克(IMO)水平测试中达到了金牌水准,这样的表现让人很容易联想到 LLM 是不是已经具备了解决博士级科研难题的推理能力?
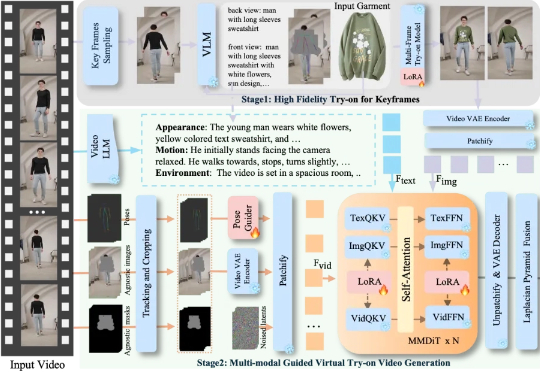
服装视频广告太烧钱?卡点变装太难拍? 字节跳动智能创作团队联合清华大学最新推出一款全能的视频换装模型 DreamVVT,为视频虚拟试穿领域带来了突破性进展。
思维链 (CoT) 提示技术常被认为是让大模型分步思考的关键手段,通过在输入中加入「Let’s think step by step」等提示,模型会生成类似人类的中间推理步骤,显著提升复杂任务的表现。然而,这些流畅的推理链条是否真的反映了模型的推理能力?
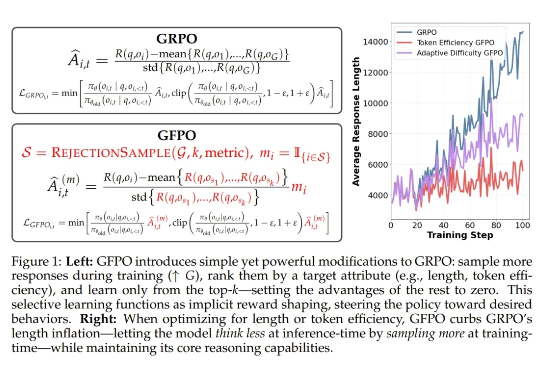
用过 DeepSeek-R1 等推理模型的人,大概都遇到过这种情况:一个稍微棘手的问题,模型像陷入沉思一样长篇大论地推下去,耗时耗算力,结果却未必靠谱。现在,我们或许有了解决方案。