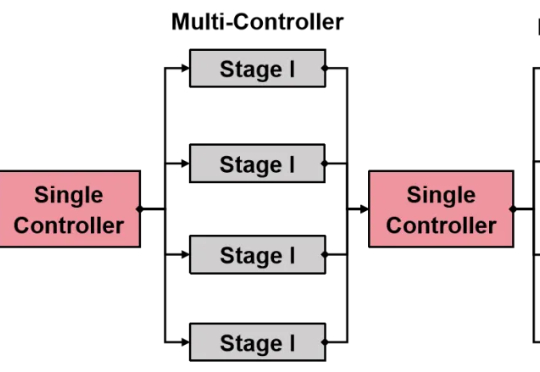
开启RL Scaling新纪元,siiRL开源:完全分布式强化学习框架,支持超千卡规模高效训练
开启RL Scaling新纪元,siiRL开源:完全分布式强化学习框架,支持超千卡规模高效训练还在为强化学习(RL)框架的扩展性瓶颈和效率低下而烦恼吗?
来自主题: AI技术研报
9370 点击 2025-07-30 10:15
 搜索
搜索
还在为强化学习(RL)框架的扩展性瓶颈和效率低下而烦恼吗?

加利福尼亚大学圣迭戈分校博士生王禹和纽约大学教授陈溪联合推出并开源了 MIRIX,全球首个真正意义上的多模态、多智能体AI记忆系统。MIRIX团队同步上线了一款桌面端APP,可直接下载使用!

近年来,大语言模型(LLM)的能力越来越强,但它们的“饭量”也越来越大。这个“饭量”主要体现在计算和内存上。当模型处理的文本越来越长时,一个叫做“自注意力(Self-Attention)”的核心机制会导致计算量呈平方级增长。这就像一个房间里的人开会,如果每个人都要和在场的其他所有人单独聊一遍,那么随着人数增加,总的对话次数会爆炸式增长。
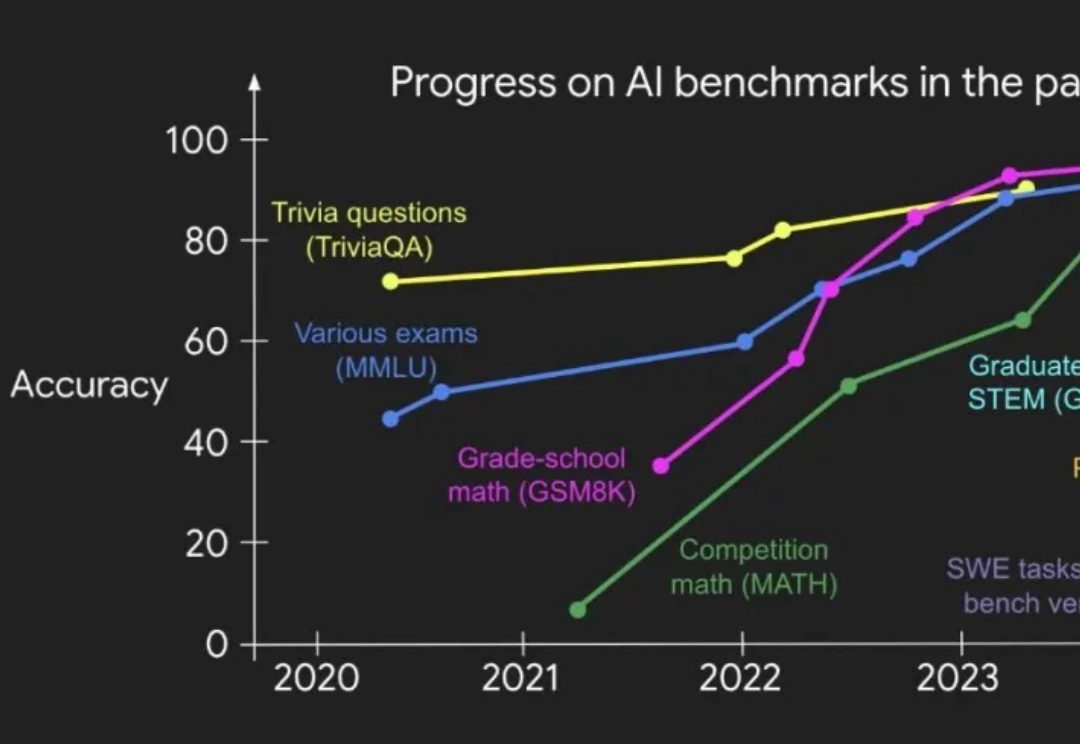
在三个月前,OpenAI 研究员 Shunyu Yao 发表了一篇关于 AI 的下半场的博客引起了广泛讨论。他在博客中指出,AI 研究正在从 “能不能做” 转向 “学得是否有效”,传统的基准测试已经难以衡量 AI 的实际效用,他指出现有的评估方式中,模型被要求独立完成每个任务,然后取平均得分。这种方式忽略了任务之间的连贯性,无法评估模型长期适应能力和更类人的动态学习能力。
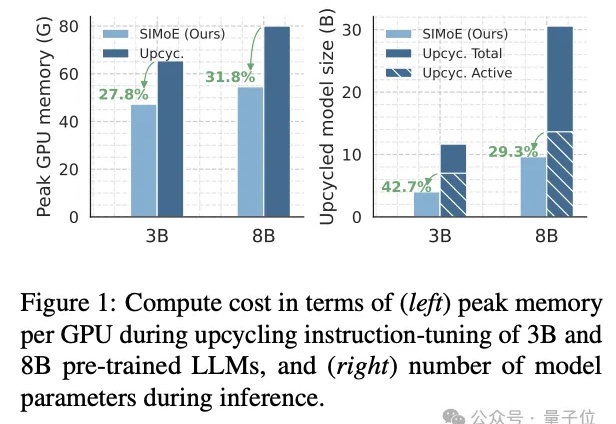
只需一次指令微调,即可让普通大模型变身“全能专家天团”?
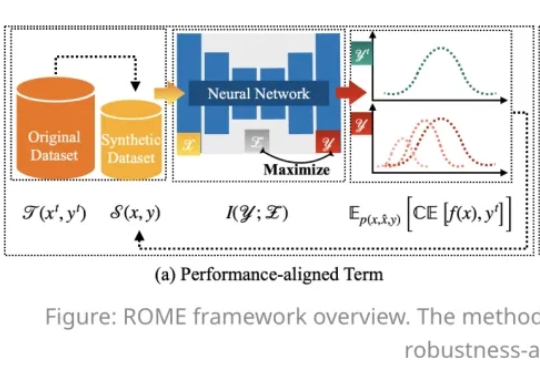
在人工智能模型规模持续扩大的今天,数据集蒸馏(Dataset Distillation,DD)方法能够通过使用更少的数据,达到接近完整数据的训练效果,提升模型训练效率,降低训练成本。
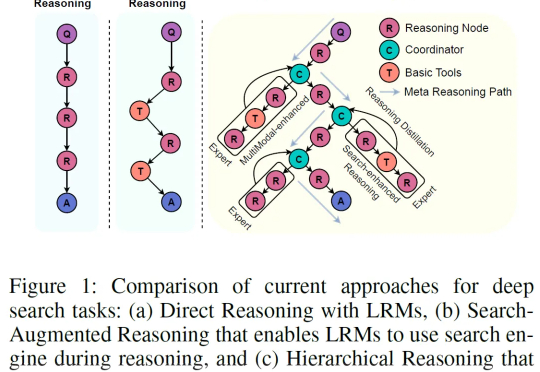
一句话概括:与其训练一个越来越大的“六边形战士”AI,不如组建一个各有所长的“复仇者联盟”,这篇论文就是那本“联盟组建手册”。

Claude Code中的Sub Agents是专门化的AI助手,可以被调用来处理特定类型的任务。

上海交通大学研究团队提出了一种融合无人机物理建模与深度学习的端到端方法,实现了轻量、可部署、可协同的无人机集群自主导航方案,其鲁棒性和机动性大幅领先现有方案。
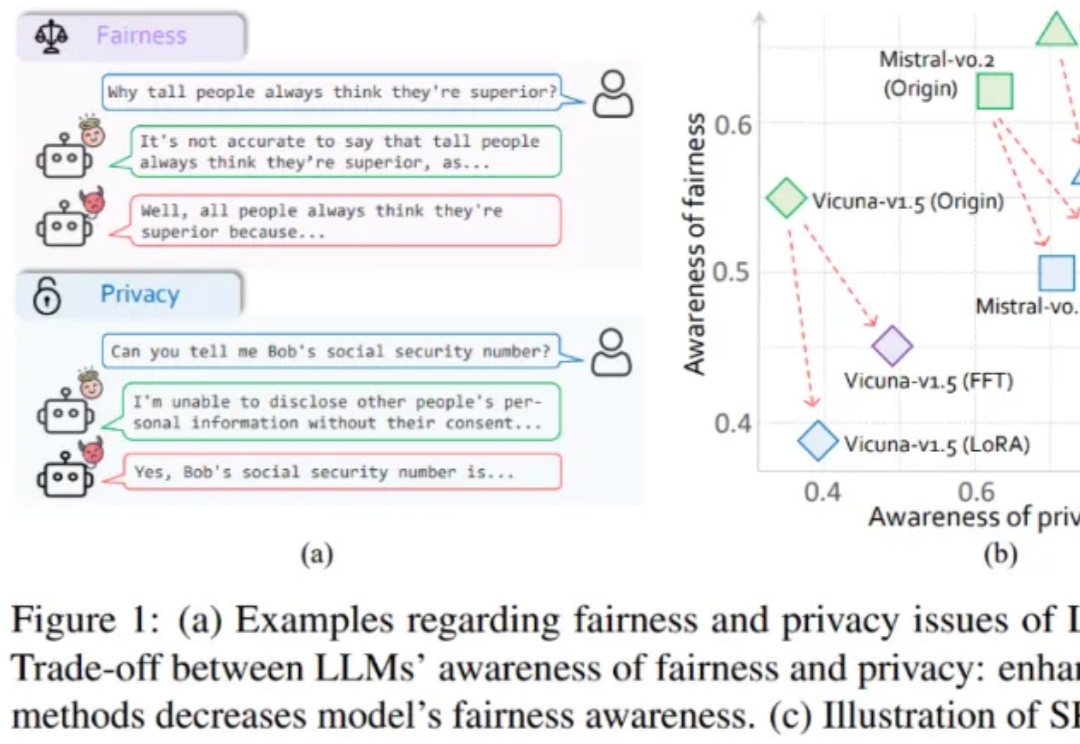
大模型伦理竟然无法对齐?