会“思考”的目标检测模型来了!IDEA提出Rex-Thinker:基于思维链的指代物体检测模型,准确率+可解释性双突破
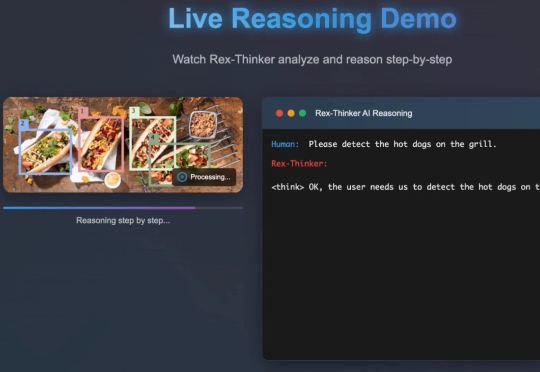
会“思考”的目标检测模型来了!IDEA提出Rex-Thinker:基于思维链的指代物体检测模型,准确率+可解释性双突破在日常生活中,我们常通过语言描述寻找特定物体:“穿蓝衬衫的人”“桌子左边的杯子”。如何让 AI 精准理解这类指令并定位目标,一直是计算机视觉的核心挑战。
来自主题: AI技术研报
9799 点击 2025-07-01 10:11
 搜索
搜索
在日常生活中,我们常通过语言描述寻找特定物体:“穿蓝衬衫的人”“桌子左边的杯子”。如何让 AI 精准理解这类指令并定位目标,一直是计算机视觉的核心挑战。
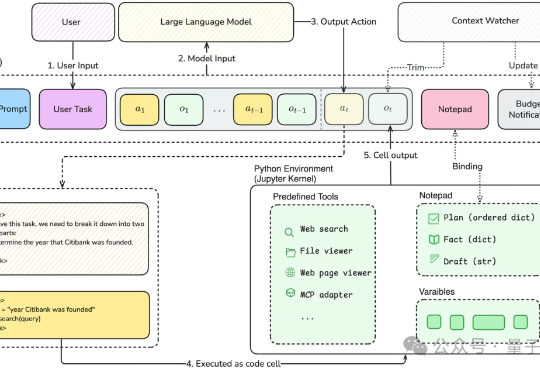
大模型可以不再依赖人类调教,真正“自学成才”啦?新研究仅通过RLVR(可验证奖励的强化学习),成功让模型自主进化出通用的探索、验证与记忆能力,让模型学会“自学”!
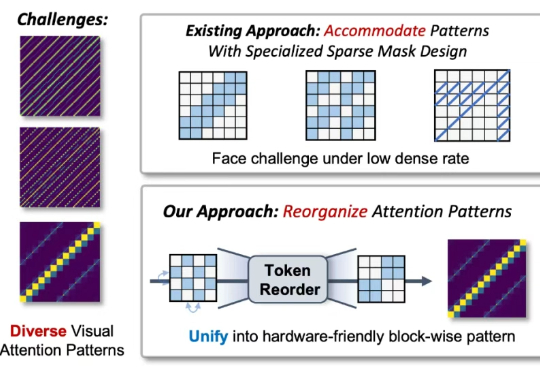
近年来,随着视觉生成模型的发展,视觉生成任务的输入序列长度逐渐增长(高分辨率生成,视频多帧生成,可达到 10K-100K)。
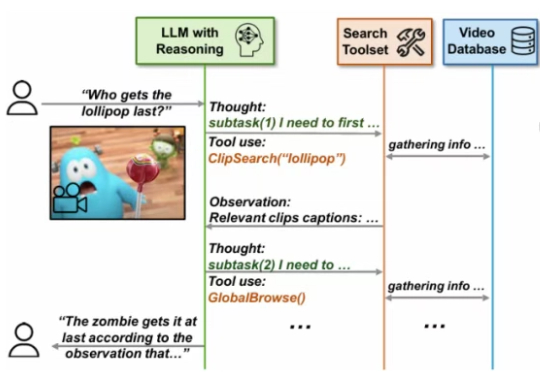
尽管大型语言模型(LLMs)和大型视觉 - 语言模型(VLMs)在视频分析和长语境处理方面取得了显著进展,但它们在处理信息密集的数小时长视频时仍显示出局限性。

What?LLM也要看出身!确实,不同的数据集训出的模型“个性”会有大不同,尤其在加之权衡方面。这就像我们经常与自己内心相互竞争的目标和价值观作斗争。
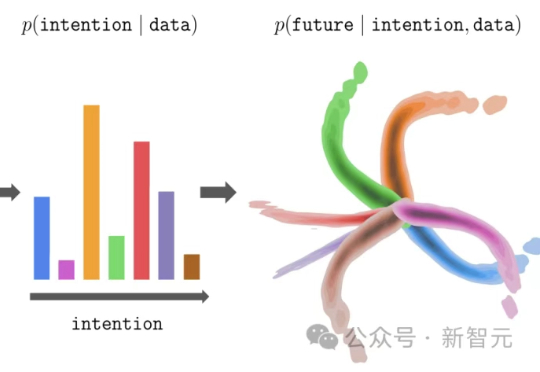
大模型的预训练-微调范式,正在悄然改写强化学习!伯克利团队提出新方法InFOM,不依赖奖励信号,也能在多个任务中实现超强迁移,还能做到「读心术」级别的推理。这到底怎么做到的?
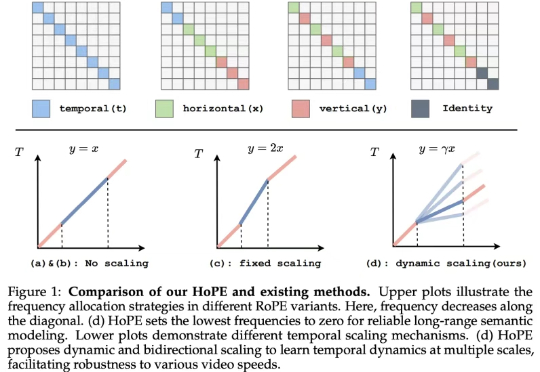
如今的视觉语言模型 (VLM, Vision Language Models) 已经在视觉问答、图像描述等多模态任务上取得了卓越的表现。然而,它们在长视频理解和检索等长上下文任务中仍表现不佳。
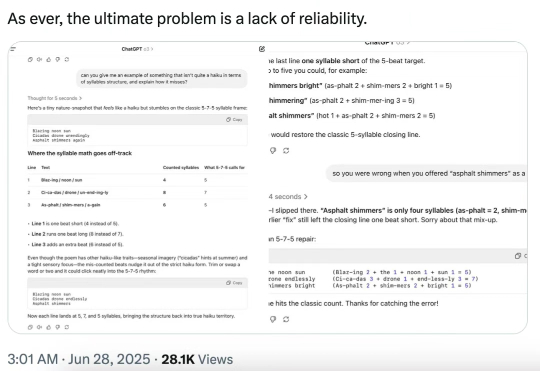
今天,著名的人工智能学者和认知科学家 Gary Marcus 转推了 MIT、芝加哥大学、哈佛大学合著的一篇爆炸性论文,称「对于 LLM 及其所谓能理解和推理的神话来说,情况变得更糟了 —— 而且是糟糕得多。」

最近,苹果的一篇论文掀起波澜,挑战了当下AI推理能力的基本假设。而OpenAI的前研究主管则断言:AGI时代已近在眼前。谁是谁非?AGI还有多远?

这是我关于「AI Native 系列」的第二篇文章,主题是:行动闭环。在上一篇里,我讲了什么样的产品才算得上真正的 AI Native,分享了我对 MCP 协议、AI 架构原生性和任务闭环的理解。