
开源15T tokens!HuggingFace放出规模最大、质量最高预训练数据集
开源15T tokens!HuggingFace放出规模最大、质量最高预训练数据集Meta最近开源的Llama 3模型再次证明了「数据」是提升性能的关键,但现状是,开源的大模型有一堆,可开源的大规模数据却没多少,而收集、清洗数据又是一项极其费时费力的工作,也导致了大模型预训练技术仍然掌握在少数高端机构的手中。
来自主题: AI技术研报
6837 点击 2024-05-05 19:51
 搜索
搜索
Meta最近开源的Llama 3模型再次证明了「数据」是提升性能的关键,但现状是,开源的大模型有一堆,可开源的大规模数据却没多少,而收集、清洗数据又是一项极其费时费力的工作,也导致了大模型预训练技术仍然掌握在少数高端机构的手中。
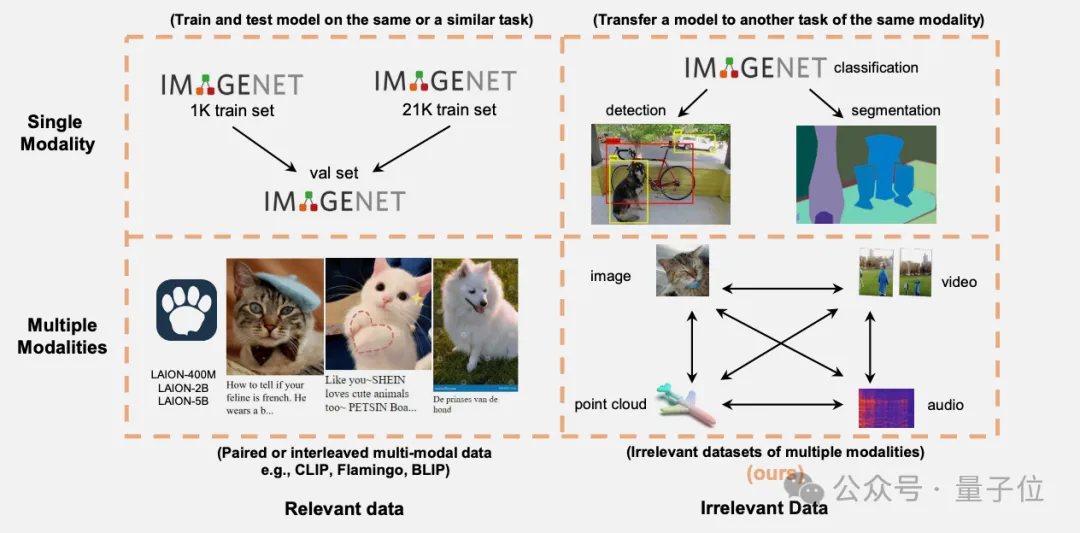
万万没想到,与任务无直接关联的多模态数据也能提升Transformer模型性能。

“预测下一个token”被认为是大模型的基本范式,一次预测多个tokens又会怎样?

语言建模领域的最新进展在于在极大规模的网络文本语料库上预训练高参数化的神经网络。在实践中,使用这样的模型进行训练和推断可能会成本高昂,这促使人们使用较小的替代模型。然而,已经观察到较小的模型可能会出现饱和现象,表现为在训练的某个高级阶段性能下降并趋于稳定。
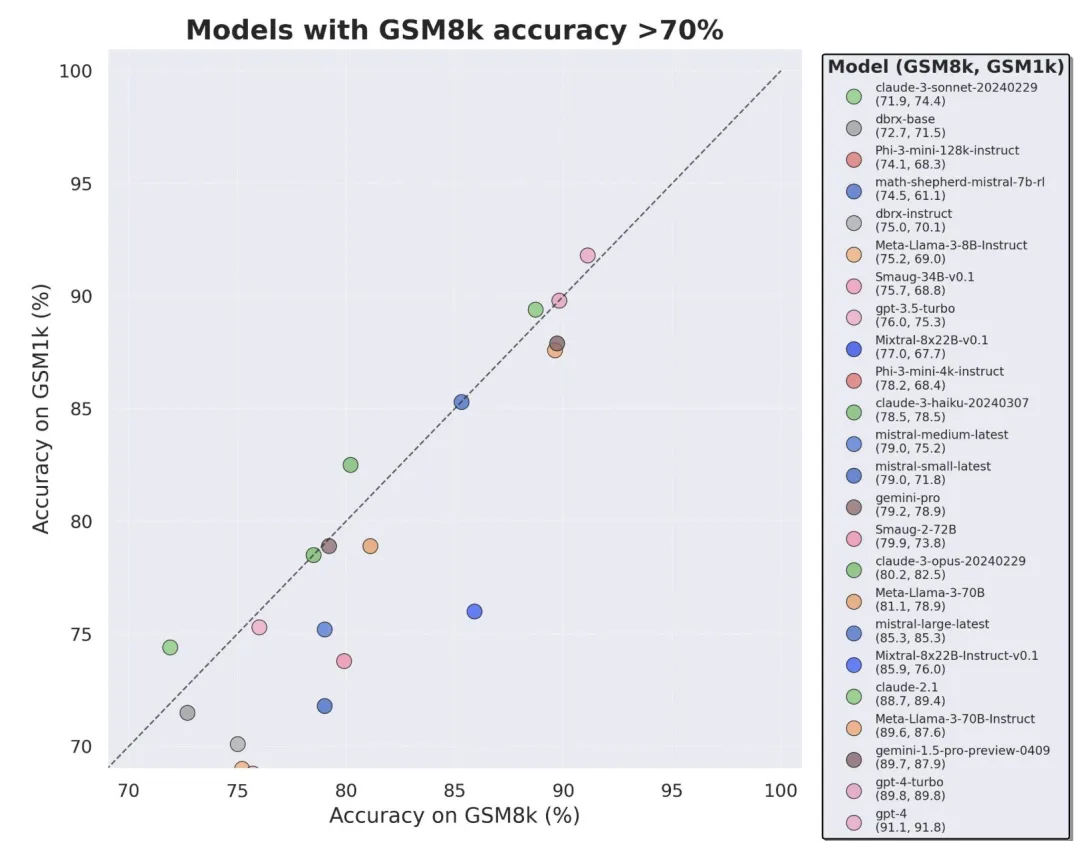
当前最火的大模型,竟然三分之二都存在过拟合问题?

自2021年诞生,CLIP已在计算机视觉识别系统和生成模型上得到了广泛的应用和巨大的成功。我们相信CLIP的创新和成功来自其高质量数据(WIT400M),而非模型或者损失函数本身。虽然3年来CLIP有大量的后续研究,但并未有研究通过对CLIP进行严格的消融实验来了解数据、模型和训练的关系。
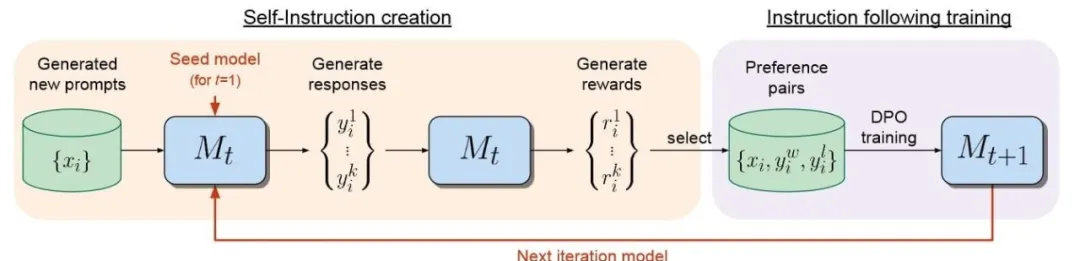
在大语言模型领域,微调是改进模型的重要步骤。伴随开源模型数量日益增多,针对LLM的微调方法同样在推陈出新。

语言,不仅仅是文字的堆砌,更是表情包的狂欢,是梗的海洋,是键盘侠的战场(嗯?哪里不对)。

探索视频理解的新境界,Mamba 模型引领计算机视觉研究新潮流!传统架构的局限已被打破,状态空间模型 Mamba 以其在长序列处理上的独特优势,为视频理解领域带来了革命性的变革。

想象一下,你仅需要输入一段简单的文本描述,就可以生成对应的 3D 数字人动画的骨骼动作。而以往,这通常需要昂贵的动作捕捉设备或是专业的动画师逐帧绘制。这些骨骼动作可以进一步的用于游戏开发,影视制作,或者虚拟现实应用。来自阿尔伯塔大学的研究团队提出的新一代 Text2Motion 框架,MoMask,正在让这一切变得可能。