
Karpathy:写了20年代码,现在像作弊
Karpathy:写了20年代码,现在像作弊vibe coding这个词,是一年前Karpathy造的,现在他自己不用了。110次实验,AI Agent自主跑完,全程没碰键盘,顺带还搭了套家庭监控分析系统。Box CEO Levie看完说了一句话:专家不会消失,但专家能做到的事,边界变了。
来自主题: AI资讯
8426 点击 2026-03-16 09:36
 搜索
搜索
vibe coding这个词,是一年前Karpathy造的,现在他自己不用了。110次实验,AI Agent自主跑完,全程没碰键盘,顺带还搭了套家庭监控分析系统。Box CEO Levie看完说了一句话:专家不会消失,但专家能做到的事,边界变了。
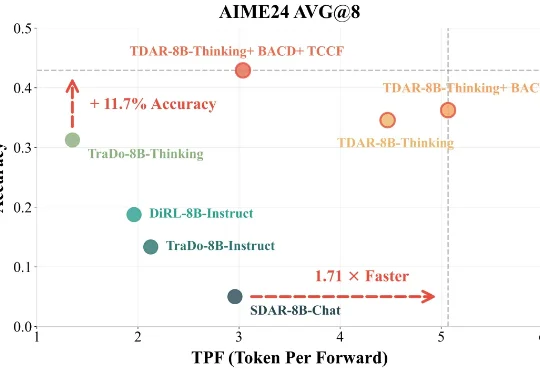
近期,复旦大学 NLP 实验室(FDU NLP)、北京大学知识计算实验室(KCL)联合美团 LongCat Team 提出了一种 Block Diffusion 推理模型 Test-Time Scaling 新框架 TDAR,通过引入 “粗思考,细求证” (Think Coarse Critic Fine, TCCF) 范式与有界自适应置信度解码

牛津大学团队推出全球首个心脏传感基础模型CSFM,能统一分析智能手环、心电图等多源数据,无论信号来自何处、是否完整,都能精准诊断房颤、预测死亡风险、重构血压波形,甚至用单一脉搏波生成完整心电图。打破了设备壁垒,让偏远地区也能享用顶级心脏监护,推动全球医疗平权。

大语言模型(LLM)的幻觉问题一直是阻碍其在关键领域部署的核心难题。近日,研究人员提出了一种名为行为校准强化学习(Behaviorally Calibrated Reinforcement Learning)的新方法,通过重新设计奖励函数,让模型学会「知之为知之,不知为不知」。
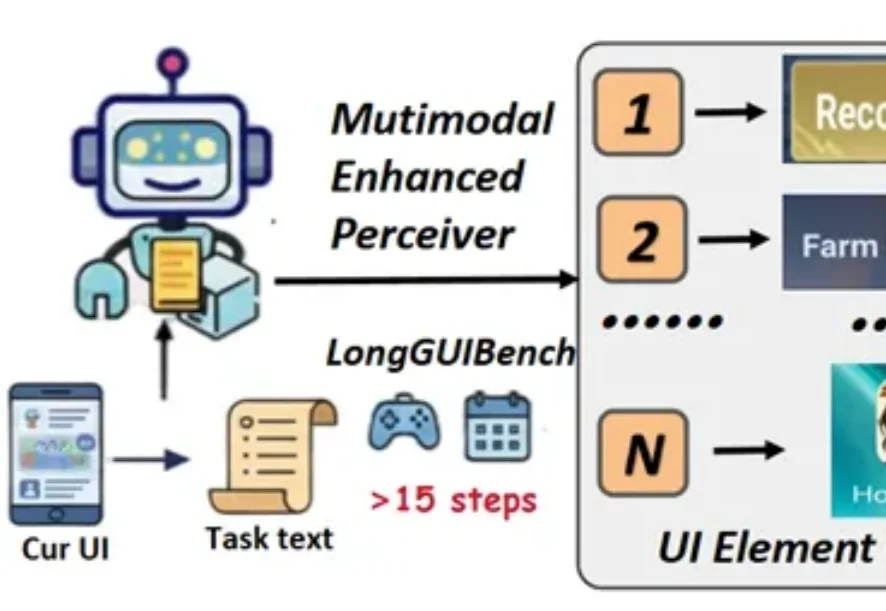
在移动端和桌面端的日常使用中,许多操作并非点一下按钮就能完成。预订一场会议、在游戏商城中购买并装备一件道具、又或者在多个应用之间完成一组连贯的工作流 —— 这些任务通常需要十几步甚至几十步的连续交互。

用户把文本发到我们的 API,我们返回一串浮点数。没有标签,没有水印,没有任何元数据告诉你它从哪来、用的什么模型。大多数人看到这串数字,反应都是"不就是一堆浮点数嘛,能看出什么?"
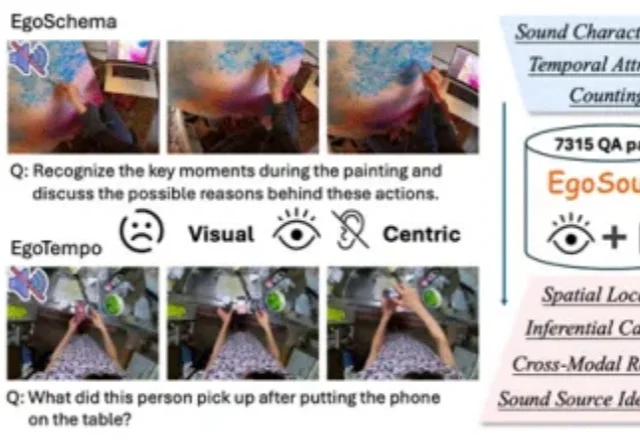
多模态大模型掉进真实世界,会“失聪”。

在生成式 AI 浪潮中,文生图技术已实现跨越式发展,在视觉呈现上达到了前所未有的高度。然而,在生成图像中准确合成拼写正确、结构规范且风格协调的文字 —— 视觉文本渲染(Visual Text Rendering, VTR),至今仍是该领域尚未攻克的核心难题。
“时光流转,谁还用日记本。往事有底片为证。”—— 许嵩《摄影艺术》

LyapLock首次让大模型在上万次知识更新中稳住旧记忆、精准学新知。它用「虚拟队列」实时监控遗忘风险,动态平衡新旧知识,理论保证长期不崩盘,编辑效果比主流方法提升11.89%,还能赋能现有模型,让AI真正学会「持续成长」。