
小众架构赢麻了!通过编辑功能 LLaDA2.1 让100B扩散模型飙出892 tokens/秒的速度!
小众架构赢麻了!通过编辑功能 LLaDA2.1 让100B扩散模型飙出892 tokens/秒的速度!谁能想到啊,在自回归模型(Autoregressive,AR)当道的现在,一个非主流架构的模型突然杀了回马枪——被长期视为学术玩具的扩散语言模型,直接在复杂编程任务中飙出了892 tokens/秒的速度!
来自主题: AI资讯
11401 点击 2026-02-11 10:47
 搜索
搜索
谁能想到啊,在自回归模型(Autoregressive,AR)当道的现在,一个非主流架构的模型突然杀了回马枪——被长期视为学术玩具的扩散语言模型,直接在复杂编程任务中飙出了892 tokens/秒的速度!

以DeepSeek R1为代表的一系列基于强化学习(RLVR)微调的工作,显著提升了大语言模型的推理能力。但在这股浪潮背后,强化微调的代价却高得惊人。
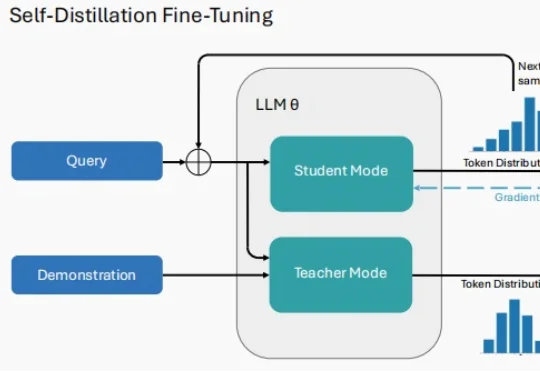
2026 年刚拉开序幕,大模型(LLM)领域的研究者们似乎达成了一种默契。 当你翻开最近 arXiv 上最受关注的几篇论文,会发现一个高频出现的词汇:Self-Distillation。
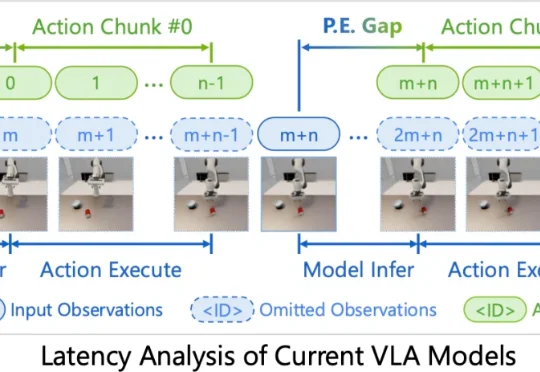
当物体在滚动、滑动、被撞飞,机器人还在执行几百毫秒前的动作预测。对动态世界而言,这种延迟,往往意味着失败。
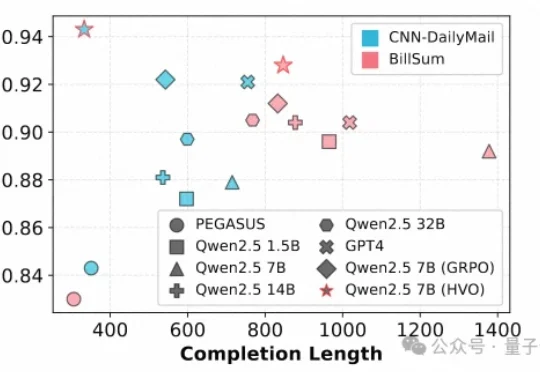
文本摘要作为自然语言处理(NLP)的核心任务,其质量评估通常需要兼顾一致性(Consistency)、连贯性(Coherence)、流畅性(Fluency)和相关性(Relevance)等多个维度。

驱动具身智能进入通用领域最大的问题在哪里?
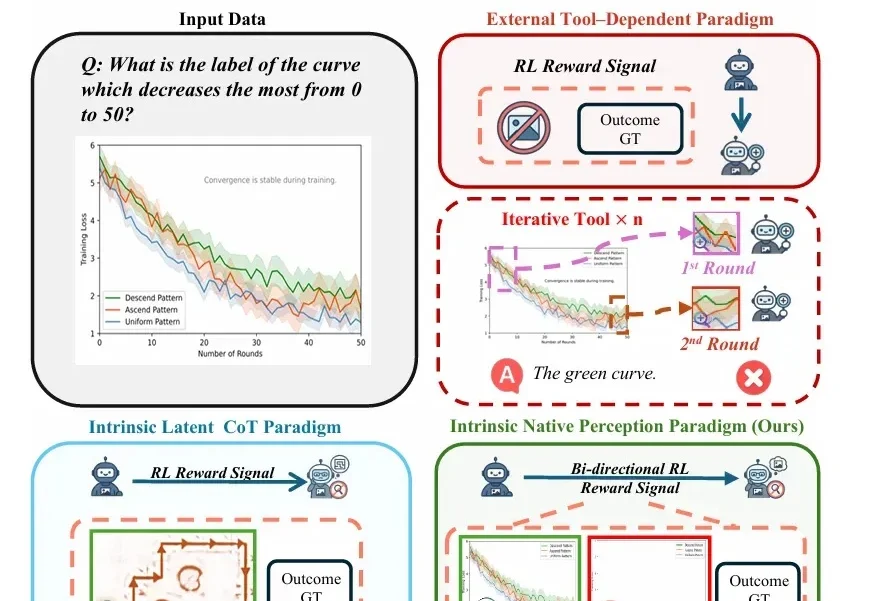
随着视觉-语言模型(VLM)推理能力不断增强,一个隐蔽的问题逐渐浮现: 很多错误不是推理没做好,而是“看错了”。

在大模型驱动的 Agentic Search 日益常态化的背景下,真实环境中智能体 “如何发查询、如何改写、是否真正用上检索信息” 一直缺乏系统刻画与分析。
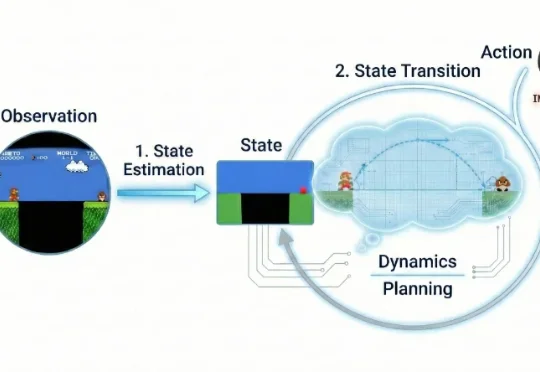
近年来,视频生成(Video Generation)与世界模型(World Models)已跃升为人工智能领域最炙手可热的焦点。从 Sora 到可灵(Kling),视频生成模型在运动连续性、物体交互与部分物理先验上逐渐表现出更强的「世界一致性」,让人们开始认真讨论:能否把视频生成从「逼真短片」推进到可用于推理、规划与控制的「通用世界模拟器」。
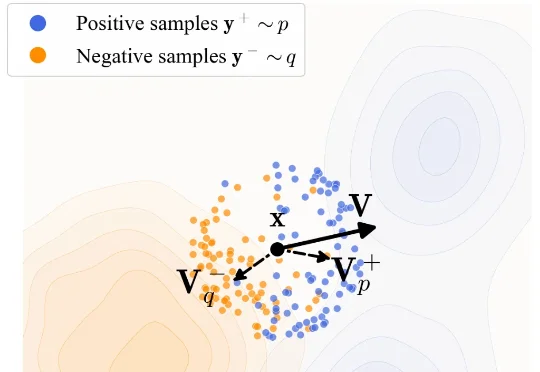
训练一个生成模型是很复杂的一件事儿。 从底层逻辑上来看,生成模型是一个逐步拟合的过程。与常见的判别类模型不同,判别类模型通常关注的是将单个样本映射到对应标签,而生成模型则关注从一个分布映射到另一个分布。