

Meta百亿抢人内幕!清华学霸转行AGI拿千万年薪,教授校友看呆了
Meta百亿抢人内幕!清华学霸转行AGI拿千万年薪,教授校友看呆了不要只盯着明星AI研究员!为了打造ASI,Meta、贝索斯等狂砸百亿,招聘专家当AI的「老师」。在此背景下,数据标注员的角色逐渐从基础任务转向更高技能的领域,门槛水涨船高。
来自主题: AI资讯
8392 点击 2025-07-27 13:28
不要只盯着明星AI研究员!为了打造ASI,Meta、贝索斯等狂砸百亿,招聘专家当AI的「老师」。在此背景下,数据标注员的角色逐渐从基础任务转向更高技能的领域,门槛水涨船高。
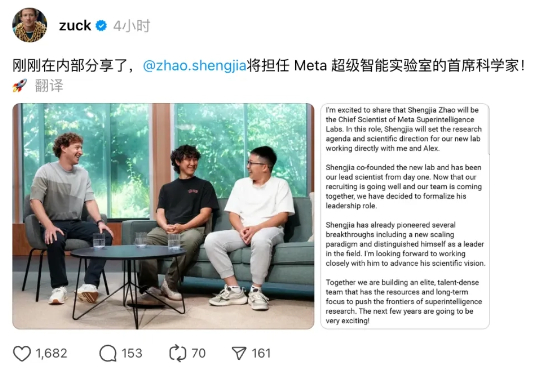
就在刚刚,Meta 宣布,清华校友赵晟佳(Shengjia Zhao)将正式担任其超级智能实验室( MSL)首席科学家。

机器人能通过普通视频来学会实际物理操作了! 来看效果,对于所有没见过的物品,它能精准识别并按照指令完成动作。

如何理解大模型推理能力?现在有来自谷歌DeepMind推理负责人Denny Zhou的分享了。 就是那位和清华姚班马腾宇等人证明了只要思维链足够长,Transformer就能解决任何问题的Google Brain推理团队创建者。 Denny Zhou围绕大模型推理过程和方法,在斯坦福大学CS25上讲了一堂“LLM推理”课。
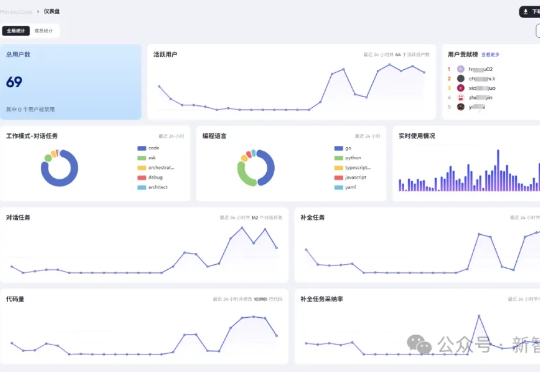
Cursor突然断供,码农AI Coding就像被砍掉了手脚!如今,清华系最强平替MonkeyCode站在了C位,不仅性能炸裂、成本超低,还能应对复杂编程任务,首发支持Kimi K2和Qwen3。
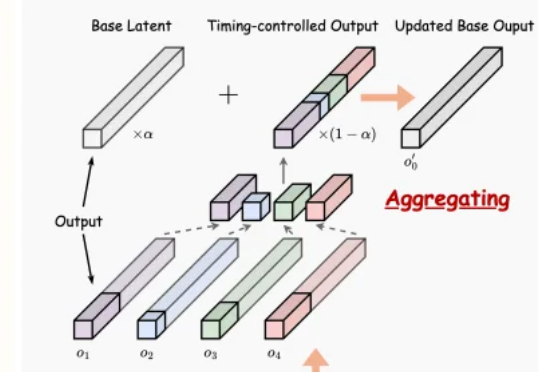
文生音频系统最新突破,实现精确时间控制与90秒长时音频生成!
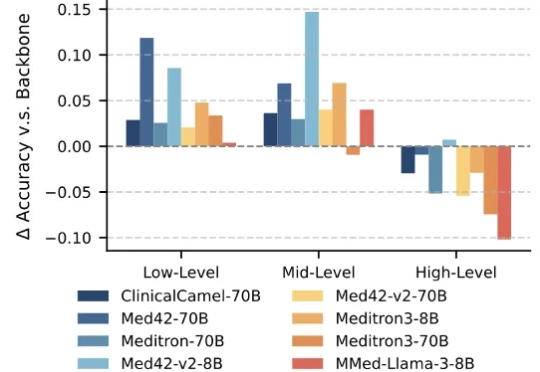
大语言模型(Large Language Models,LLMs)技术的迅猛发展,正在深刻重塑医疗行业。医疗领域正成为这一前沿技术的 “新战场” 之一。大模型具备强大的文本理解与生成能力,能够快速读取医学文献、解读病历记录,甚至基于患者表述生成初步诊断建议,有效辅助医生提升诊断的准确性与效率。

这也太惊人了吧?!
随着“220余门AI+课程”全面落地、学生全功能智能体学伴面向全校试用,一场由人工智能(AI)技术引领的教育革新浪潮正在清华园内奔涌,以蓬勃之势构建高等教育新范式。
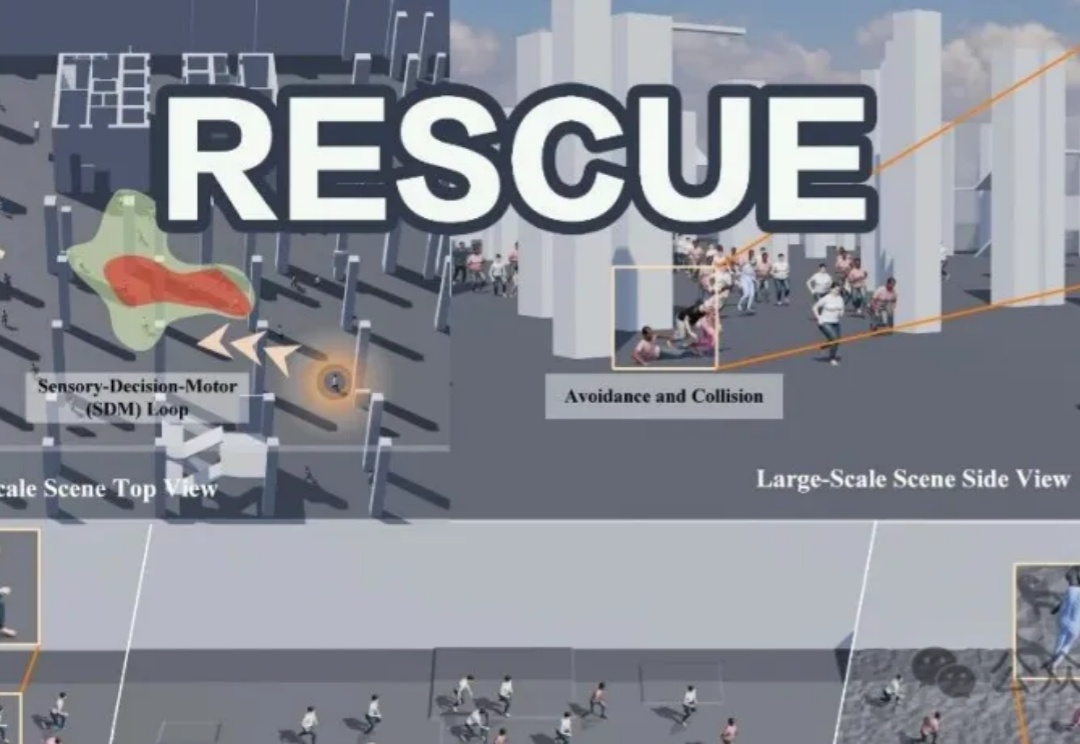
天津大学联合清华和卡迪夫大学推出RESCUE系统,把「大脑感知-决策-行动」循环搬进电脑,让数百个虚拟人同时在线逃生:他们能实时看见地形、同伴和出口,自动绕开障碍,年轻人快跑、老人慢走、残疾人蹒跚;系统还能把身体24个部位的碰撞力用颜色实时标出来,帮助设计师提前找出潜在风险区域,也能用来演练地铁火灾、演唱会疏散等公共安全场景。